OpenAI发布DALL·E语言模型与CLIP图像识别系统
类型:热点整理2026-07-02
OpenAI近期重磅推出了两款革命性多模态模型——DALL·E与CLIP。简单来说,前者能够从文本描述直接生成图像,堪称AI画师;后者则能迅速理解图像内容,如同一位图像识别专家。两者均隶属于OpenAI第三代语言生成器家族,核心目标非常明确:让机器像人类一样,实现图像与文本语义的深度打通与理解。 回
OpenAI近期重磅推出了两款革命性多模态模型——DALL·E与CLIP。简单来说,前者能够从文本描述直接生成图像,堪称AI画师;后者则能迅速理解图像内容,如同一位图像识别专家。两者均隶属于OpenAI第三代语言生成器家族,核心目标非常明确:让机器像人类一样,实现图像与文本语义的深度打通与理解。
回顾背景,2020年5月,OpenAI发布了当时全球最大的语言模型GPT-3,拥有1750亿参数和45TB训练数据。最令人惊叹的是,面对全新任务无需重新训练或微调,只需在对话中提供几个示例,它便能模仿完成相应任务。在翻译、问答、文本填空乃至需要即时推理的任务中,GPT-3的表现已接近人类水平。
DALL·E则是GPT-3的120亿参数版本,专注一个方向:将自然语言描述直接转化为图像。其名字巧妙融合了超现实主义艺术家萨尔瓦多·达利(Salvador Dali)与皮克斯动画机器人瓦力(WALL-E)的元素。简言之,它能够将文本标题转化为视觉概念,且无需依赖标签数据,而是直接从文本描述中学习上下文。
从技术角度而言,DALL·E是一种“转换语言模型”,它将文本和图像作为同一数据流进行训练。这意味着它不仅能从零开始绘制图像,还能根据文字提示,修改现有图像中的任意矩形区域。关键在于,它能够理解人类语言的细微差别,例如将不同想法组合成新物体。举例来说,输入“牛油果形状的扶手椅”,DALL·E确实能生成一把形似牛油果的椅子:

不仅如此,DALL·E还将GPT-3的零样本推理能力扩展到了视觉领域。简单来说,只要提示得当,它甚至能执行各种图像到图像的翻译任务,例如将素描转化为油画。

接下来看CLIP——图像识别领域的通才。以往大多数图像识别系统都针对特定任务进行训练,而CLIP直接利用网络上文本-图像配对数据进行学习,通用性远超单一任务模型。其工作方式非常直观:给定一个视觉类别名称,它就能判断图片中是否包含该物体。在各种图像分类基准测试中,CLIP无需针对每个测试单独优化即可获得优秀结果。更关键的是,OpenAI表示这种训练方式将稳健性差距缩小了多达75%。
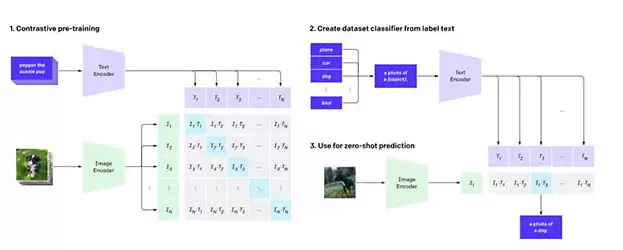
OpenAI联合创始人兼首席科学家Ilya Sutskever指出:人工智能的长期目标是构建多模态神经网络——让AI能够在文本和视觉等不同模态之间自由学习概念,从而真正理解世界。而DALL·E与CLIP的诞生,使我们离这一目标又前进了一大步。
未来,一个模型同时理解文字和图像将成为常态。当AI能够“看见”词语对应的画面时,它理解语言的方式将不再仅是统计关联,而是真正意义上的“看懂”。这正是多模态AI的独特魅力所在。