阿里云近日发布重磅消息——正式开源了新一代推理模型QwQ-32B。这个名称虽然有些拗口,但其性能却毫不含糊。用一句话概括:表现强劲、部署门槛低廉、商用完全免费,将开源推理模型的“性价比天花板”再次提升了一个台阶。
先来锁定几个核心判断:
该模型在数学、编程以及通用能力方面的表现,几乎与DeepSeek-R1并驾齐驱,而它的参数量仅为32B。更关键的是,它能够在消费级显卡上实现本地部署——这意味着,你不需要昂贵的云端设备,仅凭自己的机器就能运行出接近顶尖水平的推理结果。
阿里云此次采用了极为开放的Apache2.0协议,任何人都可以免费下载、商用,甚至进行二次开发与部署。具体细节如下。
性能对标全球最强开源推理模型
QwQ-32B是通义团队在推理模型方向的最新研究成果。这次的训练策略颇具巧思:在冷启动的基础上,分别针对数学与编程任务、通用能力进行了两轮大规模强化学习。最终结果是,在32B这一相对“轻量”的模型尺寸上,推理能力实现了质的飞跃,再次印证了大规模强化学习这条路径的可行性。
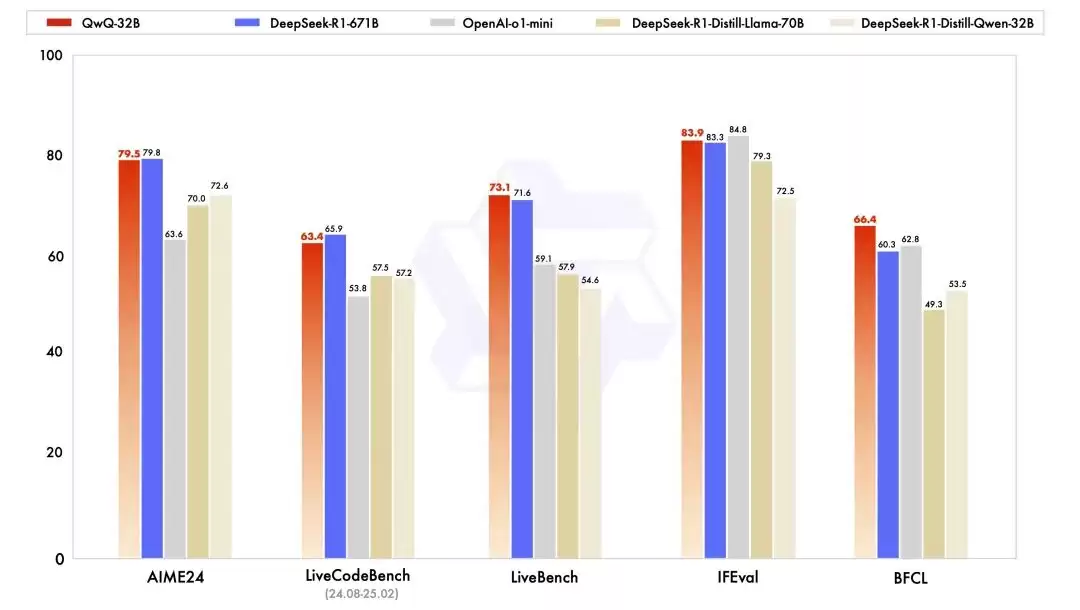
在一系列权威基准测试中,QwQ-32B的表现几乎全面超越OpenAI-o1-mini,整体水平与DeepSeek-R1相当。具体来看:
在数学能力评测集AIME24以及代码能力评估LiveCodeBench上,QwQ-32B与DeepSeek-R1不相上下,显著优于o1-mini以及同尺寸的R1蒸馏模型;在Meta首席科学家杨立昆参与推出的“最难LLMs评测榜”LiveBench、谷歌主导的指令遵循能力IFEval评测集,以及加州大学伯克利分校等提出的函数调用准确性评测BFCL中,QwQ-32B的得分甚至反超了DeepSeek-R1。
这些数据说明了什么?它意味着在推理能力这条赛道上,开源阵营已经涌现出不输甚至局部超越闭源模型的选手,而且参数量更小、成本更低。
消费级显卡即可完成本地部署
这是QwQ-32B最吸引人的亮点之一。它既提供了强大的推理能力,又将资源消耗控制在较低水平。对于追求快速响应或对数据安全有较高要求的应用场景而言,这简直是量身定制的解决方案。
开发者和企业可以轻松在消费级硬件上完成本地部署,比如常见的中高端PC或工作站,无需依赖云端资源。在此基础上,还能进一步进行微调和定制,打造专属的AI方案。这才是真正让开发者兴奋的地方——门槛降低了,想象空间打开了。
更值得一提的是,QwQ-32B模型内部还集成了智能体Agent的相关能力。简单来说,它不仅能推理,还能边使用工具边思考,并根据环境反馈动态调整推理过程。通义团队表示,下一步将继续探索智能体与强化学习的深度融合,推动长时推理能力的发展,最终目标自然是更高层次的智能,乃至AGI。
多种模型调用方式
目前QwQ-32B已经在魔搭社区和HuggingFace上架,采用Apache2.0协议开源,任何人都可以免费下载模型进行本地部署,或者通过阿里云百炼平台直接调用模型API服务。
如果你有云端部署的需求,也可以选择阿里云PAI平台快速部署,并进行模型微调、评测和应用搭建;或者通过容器服务ACK搭配阿里云GPU算力(比如GPU云服务器、容器计算服务ACS等),实现容器化部署和高效推理。
从2023年至今,通义团队已经开源了超过200款模型,覆盖了从文本、视觉、语音到文生图和视频的“全模态”,从0.5B到110B的“全尺寸”参数范围。在Chatbot Arena、司南OpenCompass等权威榜单上多次斩获“全球开源冠军”。截至目前,海内外社区中千问Qwen的衍生模型数量已突破10万,超越了美国Llama系列模型,成为全球最大的开源模型族群。
QwQ-32B的发布,不过是这条开源长征路上的又一次重要落子。但对于整个行业来说,它意味着更多人能够更自由地使用顶尖的推理能力——这才是开源真正的魅力所在。