AI声音克隆技术全解析:如何用AI复制任何声音?
首先明确一个核心判断:声音克隆技术正在从实验室加速迈向规模化应用,其成熟速度远超大多数人的预期。如今,这项技术已不再需要海量数据或复杂训练才能实现,而是通过几个开源工具就能轻松搞定,成为人人可用的“小事情”。
当前,以下三项声音克隆技术值得重点关注。
01 阿里开源 CosyVoice 2.0:多语言零样本语音克隆标杆
阿里巴巴通义实验室推出的 CosyVoice 2.0,是当前AI声音克隆赛道上的标志性选手。为何称其标志性?因为它在多语言支持、零样本克隆、情感控制等核心指标上,不仅覆盖全面,而且技术深度突出。更关键的是,它首次实现了双向流式语音合成——这意味着什么?直播带货、实时客服等对响应速度要求极高的场景,终于有了真正可落地的AI解决方案。

① 多语言与跨语言生成
支持中文、英文、日文、韩文等10种以上语言的语音合成,更令人瞩目的是其跨语言生成能力——例如,你只需输入一段中文文本,它就能直接输出流利的英语语音,完全无需额外翻译步骤。
② 零样本语音克隆
仅需3秒钟的语音样本,即可精准克隆目标音色,生成的声音自然流畅。此外,对音色、语速、情感的精细调节,也完全在控制范围之内。
③ 双向流式语音合成
突破了传统TTS的延迟瓶颈,支持实时流式输出。对于直播带货、智能客服等场景而言,这项功能堪称刚需。
④ 富文本与情感控制
你可以通过自然语言指令来引导语音的韵律和情感走向,例如“用欢快的语气强调第二句”。合成语音的细腻程度,已开始逼近真人表达水平。
02 零门槛声音克隆神器 Seed-VC:无需训练,一键模仿明星音色
想象一下这个场景:用AI一键模仿偶像的声音唱歌,或者将影视角色的配音替换成自己的音色。Seed-VC这个开源项目,正是为了实现“声音自由”而生——无需训练、无需学习,操作简单到新手都能快速上手。
它基于SEED-TTS架构开发,是一款零样本的语音/歌声转换模型。仅需1到30秒的参考音频,就能克隆目标音色,并实时应用于语音或歌曲转换。无论是将普通说话变成明星音色,还是翻唱周杰伦的歌曲,它都能轻松搞定。配音、翻唱、视频二创等场景,都是它的用武之地。
03 大规模声音克隆模型 MaskGCT:更自然、更可控的语音合成
由香港中文大学(深圳)与趣丸科技联合推出的MaskGCT,是另一款值得重点关注的大规模声音克隆模型。与现有的文本转语音模型相比,它生成的语音更加自然连贯。作为开源模型,它支持对语音的总长度、语速、停顿、预期等特征进行精细控制,甚至能够修改已经生成的语音。

一个非常实用的能力是:通过声音辨别说话人的情绪状态——愤怒、开心、恐惧——MaskGCT都能实现精准模拟。
MaskGCT 的架构解析
MaskGCT全称为Masked Generative Codec Transformer,是一种全新的非自回归式(NAR)文本到语音(TTS)模型。其设计初衷,是同时解决传统自回归(AR)和非自回归(NAR)TTS系统各自存在的短板。
它的架构采用两阶段设计:第一阶段,模型利用文本去预测从语音自监督学习模型中提取的语义tokens;第二阶段,在语义tokens的基础上生成声学tokens。
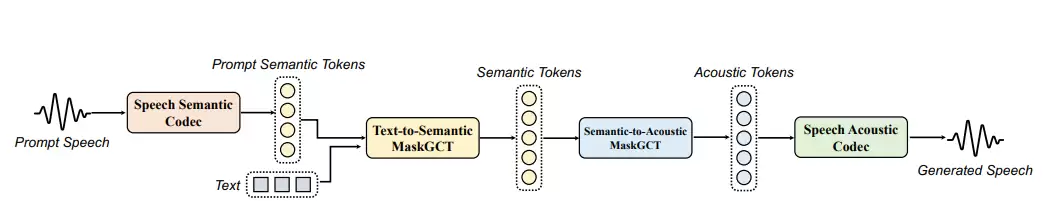
最终效果是:在没有对齐监督的情况下,直接合成出高质量的语音。它还支持语音内容编辑——通过遮罩与预测机制,对语义tokens做部分遮罩,即可实现零样本的语音内容编辑。与此同时,它也支持零样本语音转换:根据参考音频,将源语音转换为目标语音的音色,同时保持语义内容不变。这才是真正意义上的“声音自由”。