最近Deepseek爆火,老板们纷纷要求“上大模型”、“搞个知识库”。但对于真正埋头干活的开发者来说,理想很丰满,现实却很骨感——蒸馏版模型效果差强人意,满血版R1参数高达671B,显存需求直逼1342GB,换算成80G的A100也要17张,个人电脑上跑更是天方夜谭。难道就没有一个既便宜又好用的落地路径?
被老板催着加班调研了一个月后,负责任地说:Deepseek+Milvus+AnythingLLM这个组合,是目前部署本地私有知识库的最优解。它巧妙绕开了“7B太智障,671B用不起”的尴尬,通过API调用满血版模型,搭配专业的向量数据库和开箱即用的前端界面,真正做到了30分钟零门槛搭建企业级知识库。整个过程像搭积木一样简单,小白也能快速上手。
01 选型思路
先看看为什么是这三个组件,这套方案恰好解决了RAG落地的三大痛点。
1.1 模型性能问题
用过ollama提供的蒸馏版Deepseek的朋友应该都有同感——效果实在不聪明。总结起来就是:7B太智障,671B用不起。因此,推荐使用硅基流动这类云服务企业的API接口。通过API调用,可以用极低的成本获得满血版Deepseek的算力,新注册用户通常还有免费额度尝鲜。这是当前性价比最高的路线。
1.2 部署难度问题
市面上开源的RAG方案不少,但要么环境配置复杂,要么需要大量运维工作。AnythingLLM提供了完整的UI界面,天然支持Milvus向量数据库以及各种大模型接口,极大降低了入门门槛。Milvus在召回效率、支持的数据规模方面是业内公认的第一梯队,也是GitHub上向量数据库方向star数量最多的开源产品,属于AI开发者的入门基础课。
1.3 扩展性问题
这个组合最大的亮点在于灵活性:可以轻松切换不同的大模型,Milvus支持亿级数据的高性能检索,AnythingLLM的插件机制让功能扩展变得简单。总体来看,既保证了效果,又降低了门槛,还具备良好的扩展性。对于想要快速搭建私有知识库的个人来说,是非常理想的选择。
02 实战:搭建本地RAG
环境配置说明:本文以MacOS为例,Linux和Windows用户可参考对应平台的部署文档。docker和ollama安装不再展开。最低配置:CPU 4核、内存8G;建议配置:CPU 8核、内存16G。
(1)Milvus部署
1.1 下载Milvus部署文件
bash-3.2$ wget https://github.com/milvus-io/milvus/releases/download/v2.5.4/milvus-standalone-docker-compose.yml -O docker-compose.yml1.2 修改配置文件
说明:AnythingLLM对接Milvus时需要提供账号密码,因此需修改docker-compose.yml中的username和password字段。
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: registry.cn-hangzhou.aliyuncs.com/xy-zy/etcd:v3.5.5
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
healthcheck:
test: ["CMD", "etcdctl", "endpoint", "health"]
interval: 30s
timeout: 20s
retries: 3
minio:
container_name: milvus-minio
image: registry.cn-hangzhou.aliyuncs.com/xy-zy/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
ports:
- "9001:9001"
- "9000:9000"
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: registry.cn-hangzhou.aliyuncs.com/xy-zy/milvus:v2.5.4
command: ["milvus", "run", "standalone"]
security_opt:
- seccomp:unconfined
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
COMMON_USER: milvus
COMMON_PASSWORD: milvus
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
interval: 30s
start_period: 90s
timeout: 20s
retries: 3
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
networks:
default:
name: milvus
1.3 启动并检查Milvus服务
bash-3.2$ docker-compose up -d(2)ollama下载向量模型
2.1 下载查看向量模型
bash-3.2$ ollama pull nomic-embed-text
bash-3.2$ ollama list(3)注册硅基流动获取API密钥
官网:https://siliconflow.cn/zh-cn/
3.1 复制满血版Deepseek模型名称
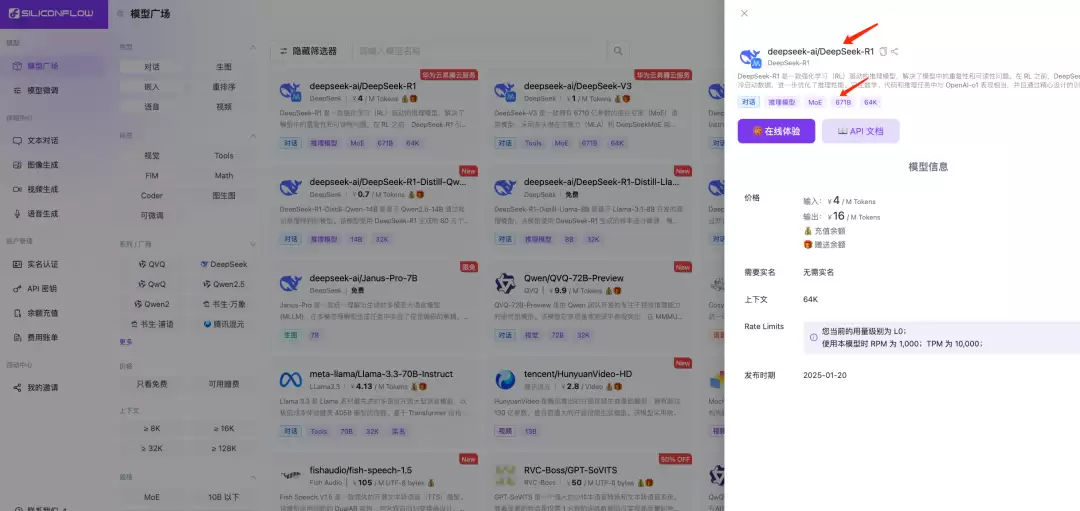
3.2 创建API密钥并记录
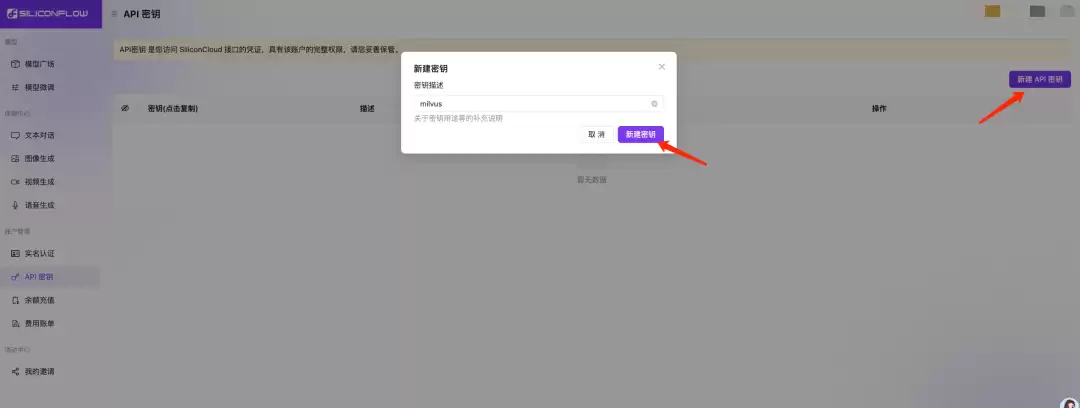
(4)下载安装AnythingLLM
4.1 安装时点击Get Started
4.2 暂不配置,先点下一步
4.3 点击Skip跳过
4.4 部署完成进入首页
(5)配置AnythingLLM
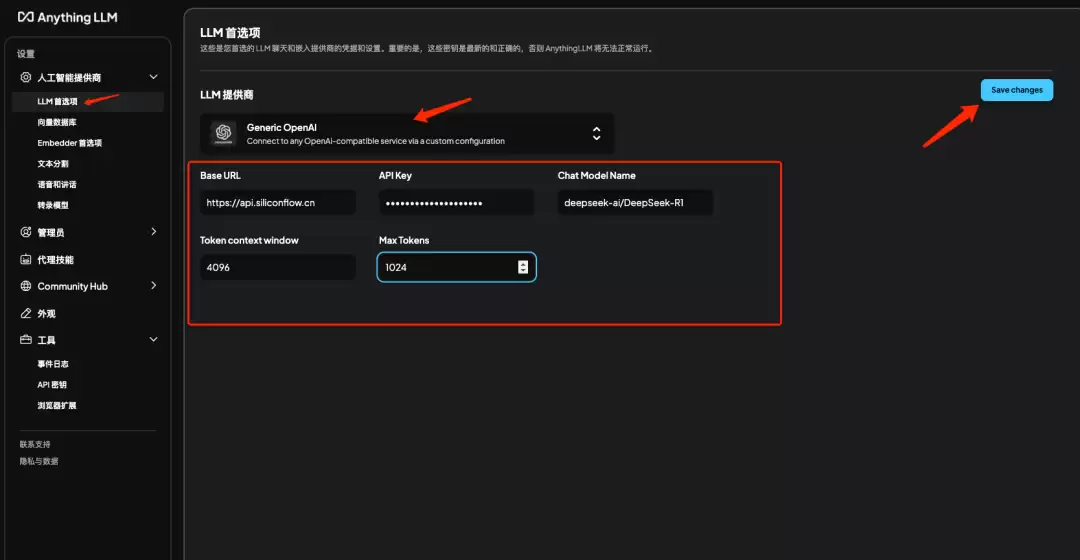
5.1 添加Deepseek模型
说明:点击LLM首选项,选择提供商Generic OpenAI,填入刚才注册的API密钥、baseurl、Deepseek模型名称并保存。
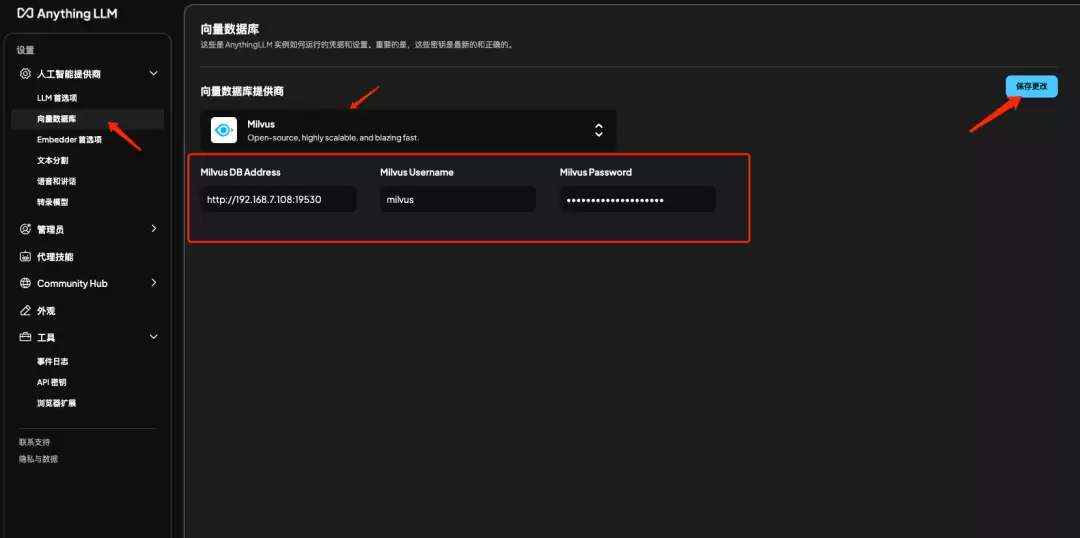
5.2 添加Milvus向量数据库
说明:点击向量数据库选项,选择Milvus,填入刚才部署好的Milvus地址、用户名、密码并保存。
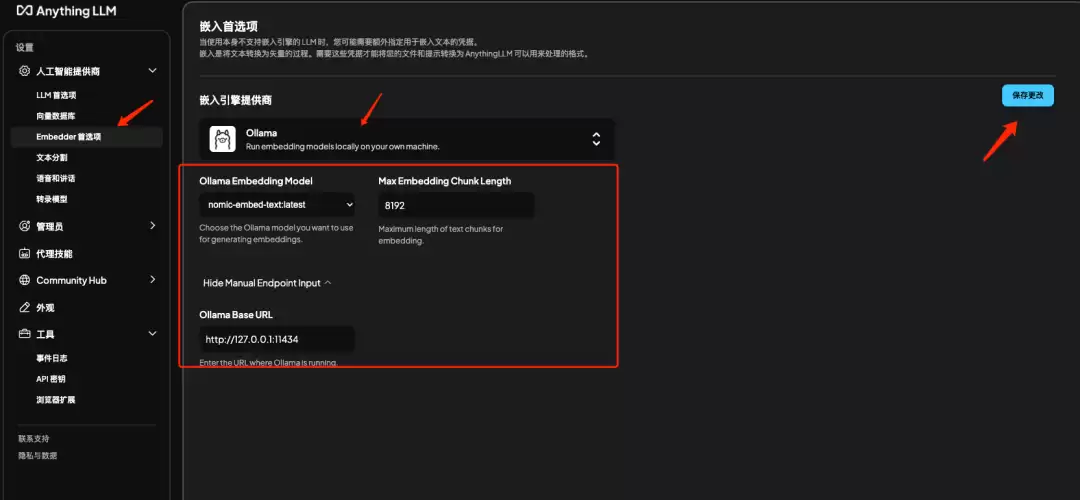
5.3 添加Embedding模型
说明:点击Embedder首选项,选择ollama,填入刚才部署好的ollama URL和模型名称(nomic-embed-text)并保存。
(6)效果演示
6.1 回到首页新建工作区
6.2 上传测试数据集
说明:数据集可以从HuggingFace获取(https://huggingface.co/datasets)。上传区域传入数据集并点击“Move”进行向量化,数据存入Milvus。
6.3 测试问答效果
说明:在对话框中输入“怎么实现向量检索?”,得到的回复符合预期,可以看到回复中引用了本地知识库中的内容。
03 写在结尾:RAG落地的思考与展望
看到这里,相信你已经成功搭建起了自己的知识库系统。除了具体的搭建步骤,这个方案背后还有一些值得分享的思考。
1. 架构设计的前瞻性
这套方案采用了“模型服务+向量数据库+应用前端”的解耦设计,好处是显而易见的:当新的大模型出现时,只需替换模型服务;数据规模扩大时,可以单独升级向量库;业务需求变化时,前端界面也能独立演进。这种松耦合的设计理念,让系统具备了持续进化的能力。在AI技术快速迭代的今天,这一点尤为重要。
2. 技术选型的平衡之道
在选择技术栈时,需要在多个维度之间找到平衡:性能与易用性(通过API调用满血版模型,而非本地部署蒸馏版)、开发效率与扩展性(选择开箱即用的AnythingLLM,但保留插件扩展能力)、成本与效果(利用硅基流动等云服务,避免高昂硬件投入)。这些选择背后,体现的是一种务实的工程思维。
3. RAG应用的演进趋势
从更大的视角来看,这套方案的出现反映了几个重要的行业趋势:知识库建设正在从企业级需求向个人需求扩展;RAG技术栈正在标准化、组件化,降低了使用门槛;云服务的普及让高性能AI能力变得触手可及。可以预见,未来随着更多优秀的开源组件出现,RAG的应用场景会越来越丰富,我们可能会看到更多细分领域的专业知识库方案、更智能的数据处理和检索算法、更便捷的部署和运维工具。
总的来说,“Deepseek+Milvus+AnythingLLM”这个组合不仅解决了当前的实际需求,也为未来的演进预留了空间。对于想要探索RAG应用的个人和团队来说,现在就是最佳的入局时点。