神经网络(Neural Network,简称 NN)正逐步渗透到我们生活与工作的各个角落,几乎每个领域都能借助它找到富有创造力的解决方案。本文旨在带你深入了解神经网络的核心要点,阅读完成后你就能掌握它的基本认知:它究竟是如何工作的?又该怎样动手搭建一个属于自己的神经网络模型?
神经网络的发展历程
这一切要从1943年说起。沃伦·麦卡洛克(Warren McCulloch)和沃尔特·皮茨(Walter Pitts)首次提出了神经网络模型的数学与算法框架——但当时完全缺乏足够的计算资源来对其进行实际测试。
时间来到1958年,弗兰克·罗森布拉特(Frank Rosenblatt)带来了一个关键转折:他创建了史上第一个能够执行模式识别的模型,即感知器。不过,他仅给出了概念与模型框架,真正的神经网络依然无法运转,相关研究也十分有限。
直到1965年,阿列克谢·伊瓦赫年科(Alexey Ivakhnenko)与拉帕(Lapa)才制造出第一批真正可测试且包含多个层的神经网络。
此后,机器学习模型逐渐变得非常实用,神经网络的研究反而进入了一段相对停滞的时期。不少人将原因归结于1969年马文·明斯基(Marvin Minsky)和西摩·帕珀特(Seymour Papert)合著的《感知机》一书。不过,这段“寒冬”其实并不漫长——仅过了6年,也就是1975年,保罗·韦伯斯(Paul Werbos)提出了反向传播算法,一举攻克了XOR问题,极大地提升了神经网络的学习效率。
1992年,最大池化(max-pooling)技术被提出。这项技术对3D目标识别非常有效,因为它具备平移不变性,并且对形变具有一定的鲁棒性。
在2009年至2012年间,尤尔根·施密德胡伯(Jürgen Schmidhuber)研究小组开发的循环神经网络与深度前馈神经网络,在模式识别和机器学习领域的8项国际竞赛中夺得冠军。到了2011年,深度学习神经网络开始将卷积层与最大池化层整合在一起,然后将输出传递给若干个全连接层,最终抵达输出层——这正是我们今天常说的卷积神经网络(CNN)。
当然,在此之后还有大量的后续研究持续推动着这一领域向前发展。
什么是神经网络?
理解神经网络的一个有效方法是将它视为一个复合函数:当你输入一些数据,它便会输出另一些数据。整个结构由三大基本组件构成:
- 单元 / 神经元
- 连接 / 权重 / 参数
- 偏置项
你可以将它们类比为建造大楼的“砖块”。具体如何排列,取决于你想让这栋大楼实现怎样的功能。水泥就相当于权重——即便水泥再多,缺乏足够的砖块,大楼同样会坍塌。反过来,你可以先用最少量的砖块让建筑勉强运转起来,然后逐步扩充架构,直至解决既定问题。
关于权重、偏置项和单元,后面还会展开详细讲解。
单元 / 神经元
作为神经网络三大组件中最“不起眼”的部分,神经元实际上就是一个包含权重和偏置项的函数。它静静地等待数据传入,接收到数据后执行计算,再利用激活函数将结果限制在某个范围(大多数情况下如此)。
不妨把单元想象成一个带有权重和偏置项的盒子,两端开口,一端接收数据,另一端输出经过修改的数据。数据首先进入盒子,权重与它相乘,再加上偏置项——这就是一个单元,本质上就是一个函数。它和下面的直线方程非常相似:
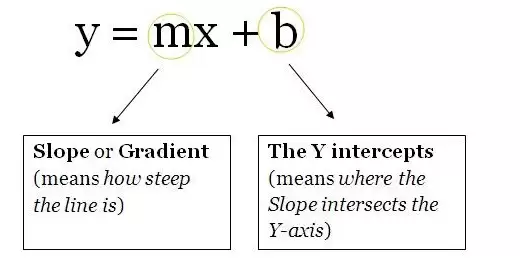
现在,想象存在多个这样的直线方程——只要超过两个,就能在神经网络中引入非线性。你会对同一个数据点(输入)计算出多个输出值,这些输出会继续传递给下一个单元,最终网络会计算出一个最终输出。
权重 / 参数 / 连接
权重是神经网络中最为关键的部分。它们(与偏置项一起)是你利用神经网络解决问题时必须通过学习得到的数值。理解这一点就够了。
偏置项
这些数字代表了神经网络认为它在完成权重乘法之后还应该额外加上的值。当然,它经常猜错,但网络会在训练过程中逐步学习到最佳的偏置项。
超参数
超参数需要手动设定。如果把神经网络比作一台机器,那么超参数就是那些能够改变机器行为方式的旋钮。
激活函数
激活函数也叫映射函数。它接收来自 x 轴的数据,然后在有限范围内(大部分情况下)输出一个值。其主要用途是将单元输出的较大数值“压缩”到较小范围。你选择的激活函数会显著影响网络性能——甚至可能决定它是优秀还是糟糕。而且,你完全可以在不同单元上选用不同的激活函数。
下面列出一些常见的激活函数:
- Sigmoid
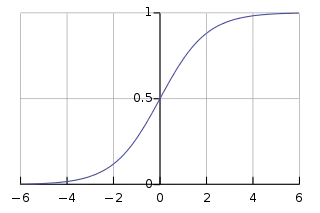
- Tanh
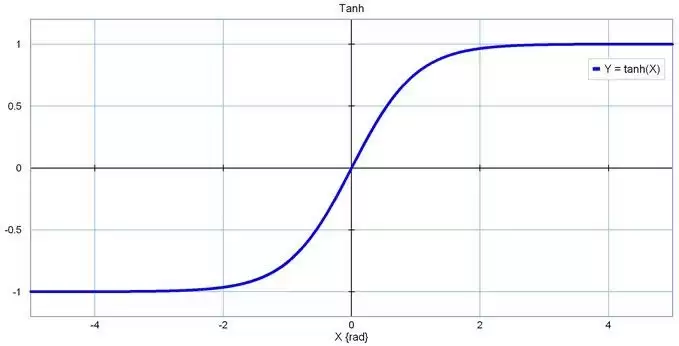
- ReLU:修正线性单元
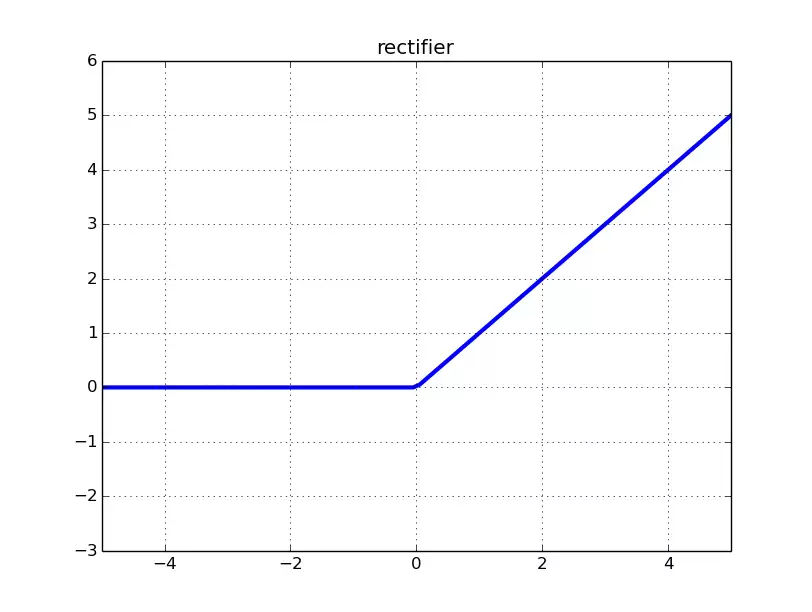
- Leaky ReLU
层
层是让神经网络能够处理复杂问题的关键所在。增加层数(以及每层中的单元数量)能够提升网络输出的非线性程度。每一层都包含一定数量的单元——在大多数情况下,数量完全由你自主决定。不过,对于简单的任务而言,堆叠过多层只会徒增复杂度,而且往往会降低准确率;反之亦然。
每个神经网络至少包含两层:输入层和输出层。位于它们之间的所有层统称为隐藏层。下图所示的网络拥有一个输入层(8个单元)、一个输出层(4个单元)以及3个隐藏层(每层9个单元)。
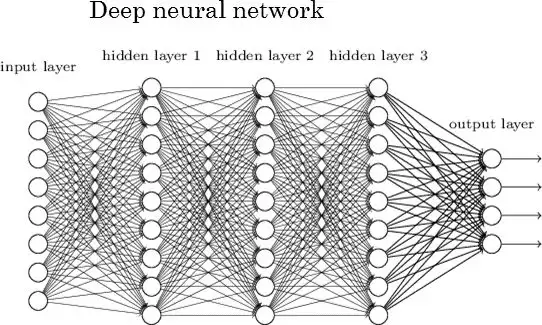
深度神经网络
当神经网络拥有两个或更多隐藏层,并且每层包含大量单元时,我们就称其为深度神经网络——这也是“深度学习”这一新兴领域诞生的土壤。上面那张图就是一个典型示例。
神经网络在学习过程中发生了什么?
训练神经网络解决问题最常用的方法之一是梯度下降。除此之外,另一种常见的训练方法就是反向传播。采用这种方法时,输出层的误差会通过微积分中的链式法则一层一层地向后传播。对于没有微积分基础的初学者来说,这可能会有些难以理解,但完全不必被吓到。
训练神经网络涉及非常多的注意事项,但一篇文章显然无法涵盖所有细节。
实现细节(如何管理项目中的所有要素)
为了说明如何将这些组件组织起来,我们可以看看一个学习XOR逻辑门的小型神经网络的实现。训练数据通常整理成矩阵的形式——这也是最常见的数据排列方式。在不同项目中,矩阵的维度可能会有所差异。
大量数据一般会被分成两类:训练数据(60%)和测试数据(40%)。神经网络首先利用训练数据进行学习,然后使用测试数据来评估其准确率。
如果你看完这些内容仍然觉得神经网络有些抽象,不妨找一些视频或在线课程来辅助理解,例如 YouTube 上的一些热门频道,或者 Coursera 上由多伦多大学、吴恩达、国立研究大学高等经济学院等机构开设的深度学习课程。动手去学、去尝试,远比死磕文字更加高效。