从口袋里的智能手机到天上的航天器,机器学习算法早已渗透进生活的每个角落。它告诉你明天会不会下雨,把一段文字从英语翻成中文,还能猜出你接下来想刷哪部剧。这些算法之所以能如此智能,关键在于它们能够根据数据自动调整内部参数——也就是学习。然而,有一类参数例外,无法通过学习获得,必须由专家手动配置,这就是所谓的超参数。随着人工智能应用日益广泛,超参数对我们生活的影响也愈发深远。
举个例子,决策树模型中的树深度、人工神经网络中的层数,都是典型的超参数。模型的性能很大程度上取决于超参数的选择。中等深度的树可能表现不错,但树要是太深,效果反而会大幅下滑。如果完全依靠人工调试,选出一组好参数几乎像一门玄学——因为最优值完全取决于手头的问题。算法不同、目标不同、数据类型和数据量也千差万别,指望一套超参数通吃所有模型和问题,根本不现实。因此,必须在每个机器学习项目的具体上下文里,对超参数进行优化。
下面,我们先回顾一下优化策略的工作逻辑,然后逐一介绍四种常用的方法:网格搜索、随机搜索、爬山和贝叶斯优化。
优化策略:让机器自己找参数
就算是有经验的专家,手动调参也是一件既耗时间又烧脑的活儿。更聪明的做法是把专家请出局,改用自动化的方法。这种根据某种性能指标,自动为给定模型找到最佳超参数集的过程,就叫优化策略。
典型的优化流程会先定义一组可能的超参数取值范围,再定一个要最大化或最小化的指标。实际操作中,它通常遵循下面几步:
- 把数据分成训练集和测试集。
- 不断重复优化循环——可以固定次数,也可以直到满足条件才停。每次循环里,先选一组新超参数,然后用它在训练集上训练模型,在测试集上做预测,再拿一个合适的评分标准(比如准确率或平均绝对误差)来评估,把指标值和对应的超参数记下来。
- 等所有循环结束,比较所有指标值,挑出那个表现最好的超参数集。
问题的关键就在于:怎么从第二步的d小步跳回到a小步,从而开启下一次迭代?换句话说,怎么保证下一组超参数确实比上一组更好?我们希望优化循环能一步步逼近合理解——就算不是全局最优,也得往那个方向走。也就是要有把握地说,下一组比上一组有进步。
大多数优化过程都把机器学习模型当成一个黑箱。每次迭代,我们只关心模型在选定超参数下的表现(用指标衡量),而不需要(也不想)知道黑箱里面发生了什么。我们只需要迭代、评估、再迭代,如此反复。
不同优化策略的真正区别,就在于“如何根据前一次迭代的指标输出,来挑选下一组超参数”。为了把这个问题研究清楚,我们可以做一个简化实验:跳过训练和测试那一步,只专注于“指标计算”这个环节,并用一个普通的数学函数来代替指标,用函数参数来代替超参数。这样一来,优化循环跑得更快,也更容易推广。再进一步,我们只用只有一个参数的函数,方便可视化。
下面就是用来演示四种策略的函数(当然,换成别的函数也一样):
f(x) = sin(x/2) + 0.5·sin(2·x) + 0.25·cos(4.5·x)
这个简化设置让我们能在简单的xy图上画出一个超参数的值和对应的函数值。x轴是超参数值,y轴是函数输出。点从白到红渐变色,白点代表较早产生的超参数值,红点代表较晚产生的。这样就能直观看出不同策略的搜索路径差异。简化后的目标就是:找到一个能让函数值最大的超参数。
好,开始看看四种常见的优化策略。
网格搜索
这是最基础也最暴力的方法:如果你不知道试哪些值,那就都试一遍。在固定步长下,把取值范围内的所有可能值都拿来算一遍。比如范围[0,10],步长0.1,那就得到0、0.1、0.2……一直到10。网格越细,离最优值越近,但计算量也成正比增长。
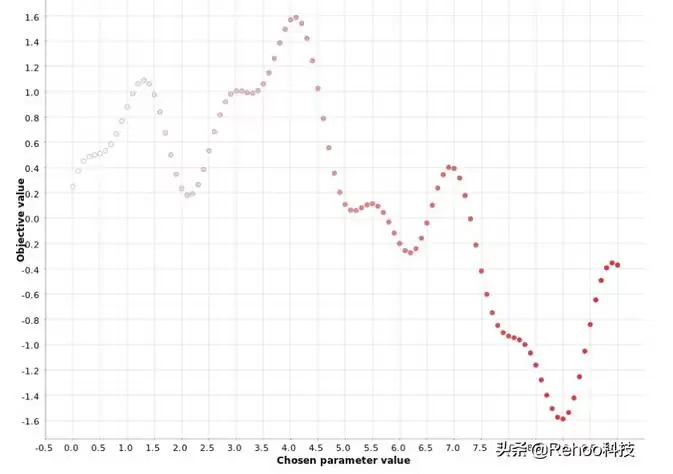
从图上看,网格搜索会从小到大地扫描整个区间。单个参数时效果不错,但一旦需要同时优化多个参数,网格搜索的效率就会急剧下降,因为候选组合数量会爆炸。
随机搜索
随机搜索顾名思义,就是随机选超参数值。在处理多个参数时,它通常比网格搜索更受青睐,尤其是当某些参数对最终指标的影响明显大于其他参数时,效果会更明显。你只要设定好要尝试的候选个数N,就可以控制优化的持续时间和速度。N越大,找到最优的可能性越高,当然计算开销也越大。
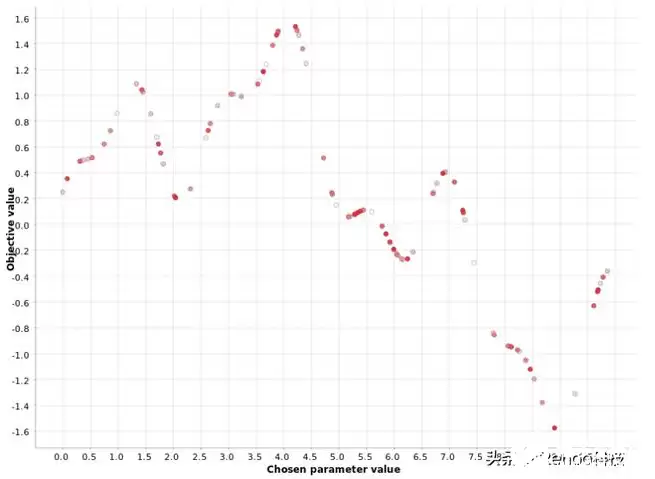
图中白点和红点随机混合,完全看不出任何顺序,这正是随机搜索的特点。
爬山
爬山策略每次迭代都会朝超参数空间中能让指标改善最快的方向前进。如果相邻方向都没有改进,优化就停下来。注意,这和网格、随机搜索有本质区别:爬山在选择下一组超参数时,会参考之前迭代的结果。
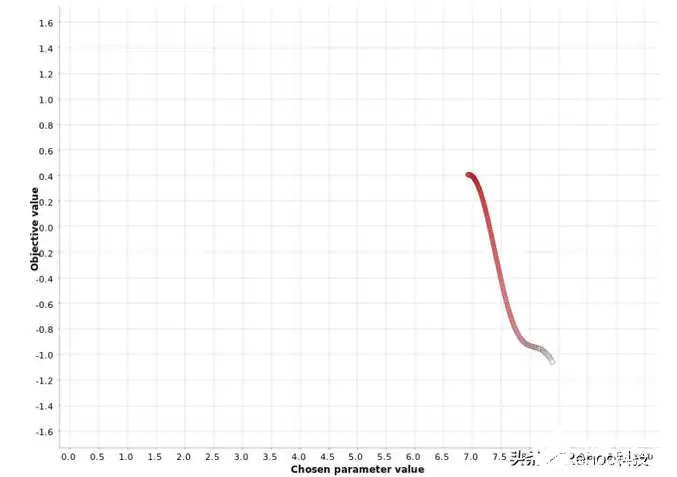
上图展示了一个具体的例子:爬山从x=8.4出发,然后朝着x=6.9方向移动,因为那里函数值达到了0.4。一旦到达这个峰值,再往相邻方向走指标都不会增加,搜索就结束了。但问题是,这个峰值只是个局部最大值。从整体看,全局最大值在x=4.0附近,指标值1.6,远高于局部。爬山很容易困在局部最优里。一个实用的经验法则是:用不同的起始值多跑几次,看看算法是否都收敛到同一个最大值。
贝叶斯优化
贝叶斯优化也基于之前迭代的结果来选择下一组超参数,但它不像爬山那样只看最后一次,而是全局地审视所有过去的迭代。
整个过程通常分两个阶段:
- 预热阶段:先随机生成一批超参数值(用户指定数量N)。
- 第二阶段:每次迭代时,会估计一个“替代模型”,描述输出值在已知超参数下的条件概率,即P(输出|过去超参数)。这个替代模型比原始函数更容易优化。算法会直接优化替代模型,把替代模型最大值处的超参数作为原始函数的推荐值。此外,还会用一小部分迭代去探索最优区域之外的地方,防止陷入局部最优。
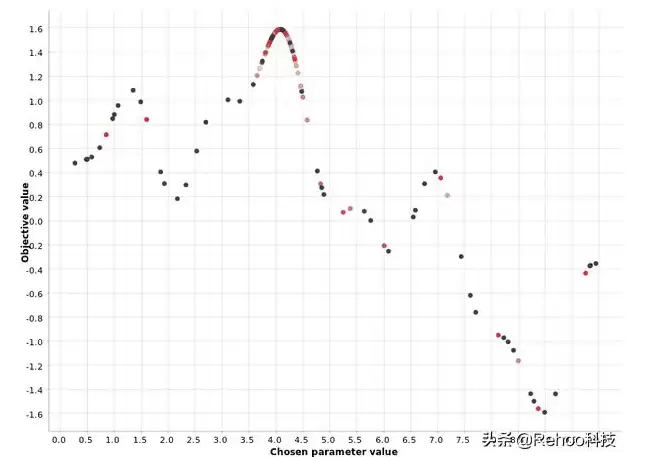
从图中的白红渐变可以看出,贝叶斯优化先用预热阶段锁定最有希望的区域,然后集中精力在这个区域里挑选更优的值。密集的红点聚集在接近最大值的位置,而淡红和白点则分散在外围。这说明第二阶段每一次迭代都在精确定位最佳区域。
总结
超参数优化对训练机器学习模型有多重要,相信不需要多说了。手动调参既慢又依赖专家知识,所以我们详细了解了四种常见的自动化方法。它们都遵循一个迭代流程:每次选一组新超参数,训练模型,评估指标,最后挑出指标最高的参数组合。区别就在于如何选下一组,才能保证比上一组更好。
网格搜索、随机搜索、爬山、贝叶斯优化,各有利弊。我们用简化的例子展示了它们的工作机制和差异。现在,你可以把这些方法用到真实的机器学习问题中去,亲自试试身手了。