深度学习,尤其是以卷积神经网络为代表的算法,这几年在各个计算机视觉任务上可以说是一路高歌猛进——图像分类、目标检测、画质增强,样样都拿手。不过话说回来,识别率上去了,代价也不小:计算复杂度爆炸式增长,内存需求也跟着水涨船高。传统的通用处理器,现在基本扛不住这活儿了。
怎么解决?主流思路是上硬件翻跟斗,比如GPU、ASIC或者FPGA。先说GPU,它走的是单指令流多数据流路线,想榨干它的性能得靠大批量数据,而且功耗高,用在那些对功耗敏感的场景里基本没戏。ASIC呢,针对特定应用确实能拿到最好的性能和能效,但研发周期太长,市场预判稍有偏差就可能白忙一场。这样一来,FPGA反而成为一个很有意思的选择——它是可编程的,功耗低,性能也不错,延时比GPU小,很适合小批量的流式应用;而且跟ASIC比起来,它还能随时通过配置改电路结构,给特定应用定制硬件。对于深度学习这种日新月异的领域,这简直就是量身定做的。
本文要做的就是:先介绍YOLOv2-Tiny这个目标检测算法,然后基于FPGA设计对应的硬件翻跟斗,顺便对各模块的处理时延建个简单的模型,再把卷积模块的详细设计给出来。最后,我们在Xilinx的Zedboard开发板上跑了个评估。
1 YOLOv2-Tiny模型简介
YOLOv2-Tiny目标检测算法的流程,大致可以拆成三步:
(1)任意分辨率的RGB图像进来,先把每个像素值除以255,压缩到[0,1]区间。然后按原图的长宽比缩放到416×416,空出来的地方用0.5填上。
(2)把上一步得到的416×416×3数组扔进YOLOv2-Tiny网络,检测完输出一个13×13×425的数组。这个数组怎么理解?简单说就是把416×416的图像切成13×13的网格,每个网格预测5个边框,每个边框又包含85维特征——80类物体的概率、边框中心的相对偏移和长宽比预测(4维)、还有边框是否包含物体的可信度(1维)。5乘以85,正好425维。
(3)拿到13×13×425的数组后,从中提取出边框的中心和长宽。然后根据覆盖度、可信度和物体预测概率这些指标,把13×13×5个边框筛一遍,找出最有可能包含物体的那个。最后再根据原图的长宽比调整回原始尺寸,位置和类别信息就出来了。
整个YOLOv2-Tiny网络一共16层,包括9层卷积、6层最大池化,外加最后一层检测层。卷积层负责特征提取,池化层负责降采样缩小特征图规模。步骤(1)通常叫做图像预处理,步骤(3)则是后处理(包含检测层的活儿)。
1.1 卷积层
卷积层的作用,就是用卷积核对输入特征图做卷积来提取特征。伪代码长这样:
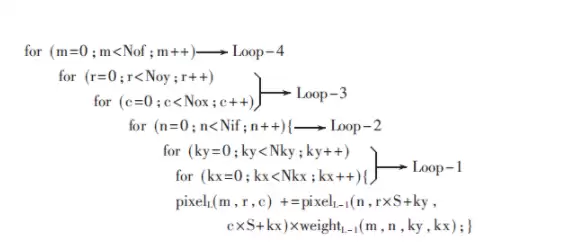
这里的Noy、Nox、Nof、Nif、Nky、Nkx、S分别代表输出特征图的大小、输出特征图数量、输入特征图数量、卷积核大小和步长。pixelL(m,r,c)则是输出特征图m中第r行第c列的像素。
1.2 池化层
池化层跟在卷积层后面,主要负责对输入特征图降采样,把规模压下来。YOLOv2-Tiny用的是最大池化,伪代码如下:
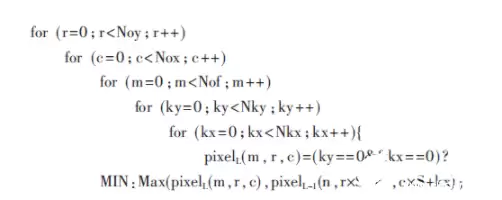
Max函数返回两者中较大的那个,MIN是个很小的常量,其他参数和卷积层差不多。说起来,池化层和卷积层结构其实挺像的,区别主要在于把乘加运算换成了比较运算。而且,卷积层的计算量通常占到整个网络的90%以上,所以下面重点讨论卷积模块的设计。
2 基于FPGA的YOLOv2-Tiny翻跟斗设计
2.1 翻跟斗架构介绍
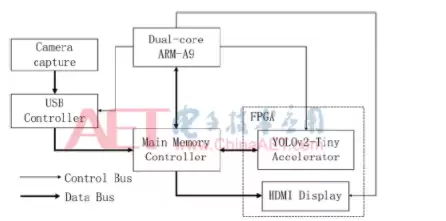
如图1所示,翻跟斗用的是三层存储架构:片外存储、片上缓存,以及处理单元里的局部寄存器。具体来说,先从片外存储里把卷积核权重和输入特征图像素读到FPGA的片上缓存,然后尽量多次复用缓存里的数据,减少访存次数和数据量。中间计算结果都留在片上输出缓存或者局部寄存器里,直到最终结果算出来再写回片外存储。
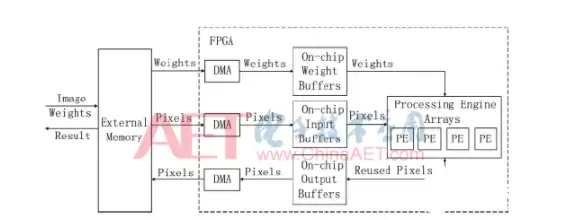
从这个架构可以看出,翻跟斗的时延主要来自三部分:访存时延、片上传输时延和计算时延。拆解开来看,可以分成四个模块:输入读取模块、权重读取模块、计算模块和输出写回模块。
对应的数据流伪代码如下:

2.2 卷积模块
卷积模块的设计思路是:把卷积循环里的输出特征图数和输入特征图数两维展开,形成Tof×Tif个并行乘法单元和Tof个深度的加法树,用流水线方式处理乘加计算。以Tof=2、Tif=3为例,具体结构见图2。
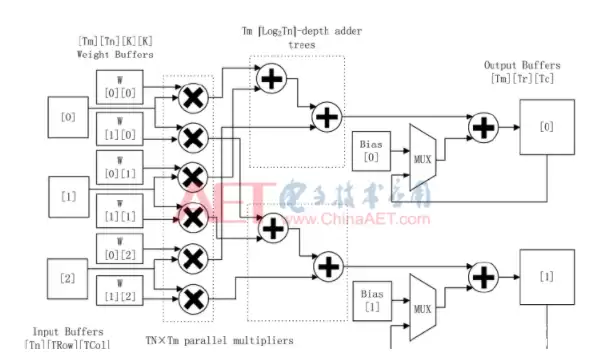
流水线填满之后,每个时钟从Tif个输入缓存里读入Tif个像素,从Tof×Tif个权重缓存里读入相同位置的参数,Tof×Tif个并行乘法单元复用Tif个输入像素做乘法。然后Tof个加法树把乘积两两相加,结果和中间结果累加后,写回对应的输出缓存。卷积模块的处理时延为:
其中Const是流水线初始化之类的额外时钟开销,Freq是翻跟斗的工作时钟频率。
2.3 各模块的时延建模
这一节主要是给另外三个模块——输入读取模块、权重读取模块和输出写回模块——建立时延模型。先约定一下:MM(Data Length, Burst Lengthmax)表示以最大突发长度Burst Lengthmax去读或写Data Length长度的连续数据需要的访存时延。
2.3.1 输入读取模块
输入读取模块的时延LatencyLoad IFM由两部分组成:
(1)通过DMA从片外读取Tif张输入特征图中Tiy×Tix大小的像素块到片上:
(2)把像素块传输到片上缓存:
一般这两个过程会乒乓起来,所以输入读取模块的时延是:
2.3.2 权重读取模块
权重读取模块的时延LatencyLoad W同样由两部分组成:
(1)通过DMA从片外读取Tof个卷积核里对应Tif张输入特征图的Nky×Nkx个权重:
(2)把权重参数传输到片上缓存:

2.3.3 输出写回模块
输出写回模块的时延LatencyStore也由两部分组成:
(1)把输出特征图像素块传输到DMA:
(2)通过DMA将Tof张输出特征图中Toy×Tox大小的像素块写回片外:

通过乒乓缓冲设计,可以让输入读取、卷积计算、输出写回这几个模块的时延相互掩盖,从而把总时延降下来。
3 实验评估
3.1 实验环境
实验平台是Xilinx的Zedboard开发板,集成了双核ARM-A9和FPGA。FPGA的资源情况:BRAM_18Kb有280个,DSP48E有220个,FF有106400个,LUT有53200个。双核ARM-A9的时钟频率667 MHz,内存512 MB。摄像头用的是Logitech C210,最大分辨率640×480,最高30帧每秒。当前目标检测系统的FPGA资源消耗如表1所示。
对比的CPU平台是服务器级别的Intel Xeon E5-2620 v4(8核),工作频率2.1 GHz,内存256 GB。
3.2 总体架构
整个系统的流程如图3所示:USB摄像头采集图像,存到内存里,ARM负责预处理,然后交给FPGA端的YOLOv2-Tiny翻跟斗做目标检测,检测完的数据还放回内存。ARM做完后处理后,把带有检测类别和位置的图像写回内存的某个地址,最后FPGA端的HDMI控制器把它显示到屏幕上。
显示屏上的检测结果见图4。用COCO数据集里的图片做的验证结果见图5。
3.3 性能评估
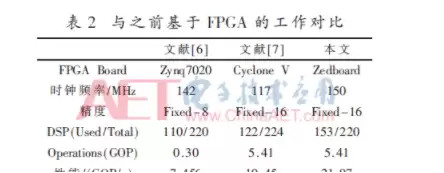
从表2可以看出,当前的设计在性能上超过了之前的一些工作。文献[6]的做法是把简化后的整个YOLOv2-Tiny网络按层全部映射到FPGA上,但因为各层之间没有用乒乓缓冲,访存和数据传输时延无法和计算时延重叠。文献[7]则是把卷积运算转成通用矩阵乘法,再用矩阵分块的方式并行计算,但每次计算前都要对卷积核参数做复制和重排序,增加了额外的时延和复杂度。
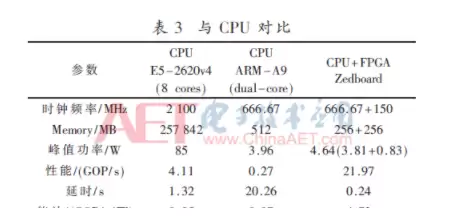
再来看表3的数据:CPU+FPGA的异构系统,能效是双核ARM-A9的67.5倍,是Xeon的94.6倍;速度是双核ARM-A9的84.4倍,大概是Xeon的5.5倍。这个提升还是很可观的。
4 结论
基于深度学习的目标检测算法,在准确度上确实已经超过了传统方法。但准确度提高的同时,计算复杂度和内存需求也跟着猛涨,通用处理器已经很难满足需求。本文设计并实现了一个基于FPGA的深度学习目标检测系统,核心是YOLOv2-Tiny硬件翻跟斗,给出了各模块的处理时延模型和卷积模块的详细设计。从实验结果看,最终实现的性能超过了当前的一些工作,说明FPGA这条路是走得通的。