深度学习翻跟斗这个领域,这两年可真是热闹非凡。从RTL设计到仿真验证,再到配套的Linux驱动和模型压缩技术,每一个环节都藏着不少门道。今天,咱们就来系统地梳理一下,要玩转基于AI翻跟斗,尤其是FPGA这个方向,到底需要跨过哪些知识门槛。
市面上主流的翻跟斗件不外乎三种:通用但算力有限的CPU、生态成熟但功耗偏高的GPU,以及近年来为深度学习“量身定做”的AI专用芯片和FPGA。特别是FPGA,以其高度的灵活性和针对性,成为许多公司验证和部署AI加速方案的关键平台,从赛灵思这样的老牌厂商到阿里、腾讯等互联网巨头,都在这个赛道上积极布局。甚至可以说,很多AI芯片的前期架构验证,都离不开FPGA的身影。那么,用FPGA来给深度学习加速,到底需要掌握哪些技能栈呢?
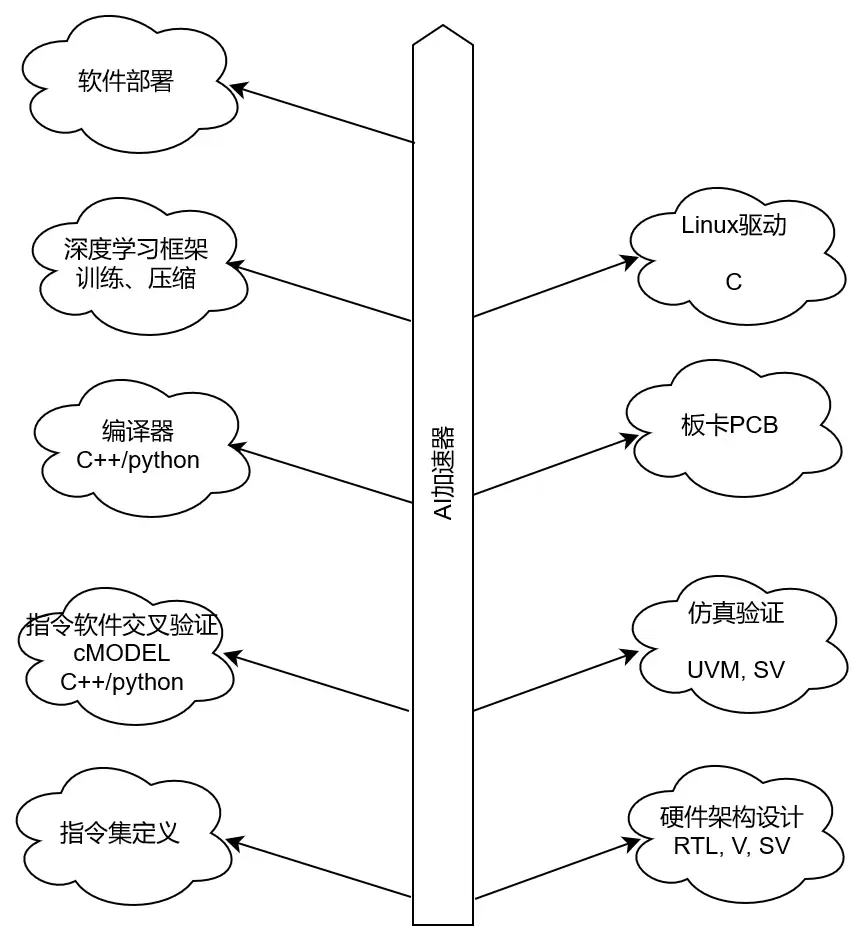
1. 一张全景图
首先得明确,AI加速是一个典型的软硬协同工程。下面这张图,可以帮你快速建立起对整个知识体系的全景认知。
3. RTL设计:从算法到硬件的桥梁
这是硬件实现的核心。设计时主要得抓住几个要害:
首先,得会“看菜下饭”。仔细分析目标神经网络,识别出计算最密集、最适合用硬件并行加速的部分。比如在CNN里,卷积运算自然是消耗DSP资源的大户。但卷积层之间的激活、归一化等操作,虽然计算量小,却可能成为流水线的瓶颈。如何让这些操作与主计算无缝衔接,是影响最终性能的关键。
其次,设计高效的加速算法。这里核心要解决两个问题:计算资源利用率和数据命中率。利用率包括空间(占满FPGA的DSP、BRAM)和时间(让计算单元持续工作,别闲着)。而数据命中率则关乎片上缓存的设计——参数和数据能否及时送到计算核嘴边,决定了需要访问外部慢速存储的频率,直接拖慢还是拉快整体速度。
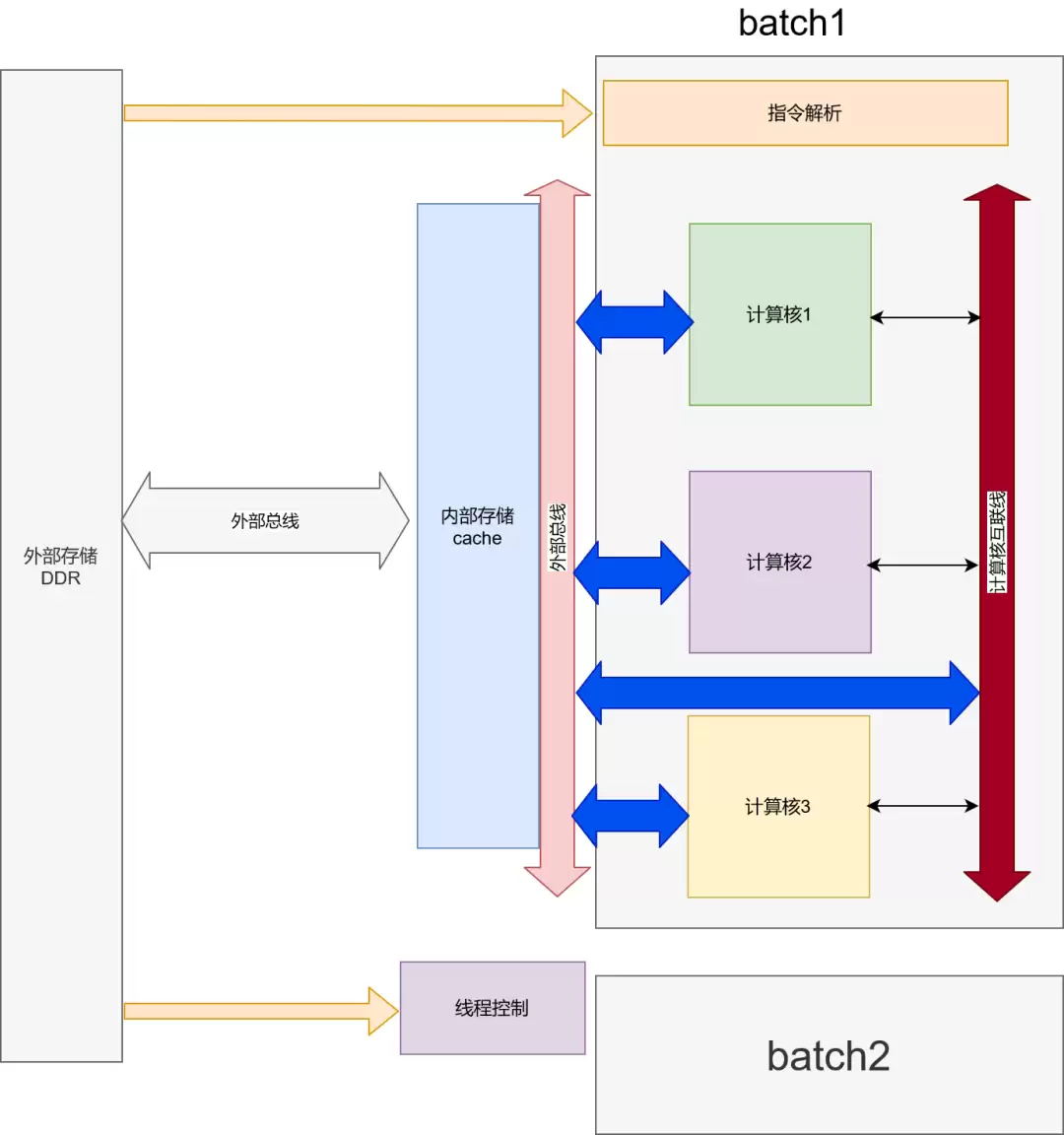
最后,架构要有一定的通用性。目前主流的做法是基于一套精心设计的指令集来构建。深度学习的算子类型相对固定,像LSTM网络,核心操作无非矩阵乘、加、激活等,用不到十个指令就能覆盖。为了支撑这套指令,一个典型的翻跟斗架构通常包含以下几个部分:
- 外部总线接口:负责与片外DDR内存“打交道”,搬运数据。
- 内部存储与缓存:作为计算核的“贴身粮仓”,目标是喂饱计算单元,缓解带宽压力。
- 指令解析单元:解码指令,并调度给相应模块执行。
- 内部数据通路:连接各个模块的高速公路。
- 张量计算核:真正的“算力引擎”,执行核心的神经网络运算。
- 计算核互联网络:实现核与核之间的直接数据传递,构建更深的流水线。
- Batch(处理批次):可以理解为一个包含了计算核、指令解析等资源的“线程”单元。多个Batch就支持多线程并行计算,例如让两个LSTM句子同时跑起来。
- 线程控制器:协调和管理多个Batch的并发执行。
4. 验证:确保芯片“言行一致”
芯片设计,验证的工作量往往比设计本身还大。在这里,验证主要分两大块:指令集正确性验证和RTL代码的功能仿真。
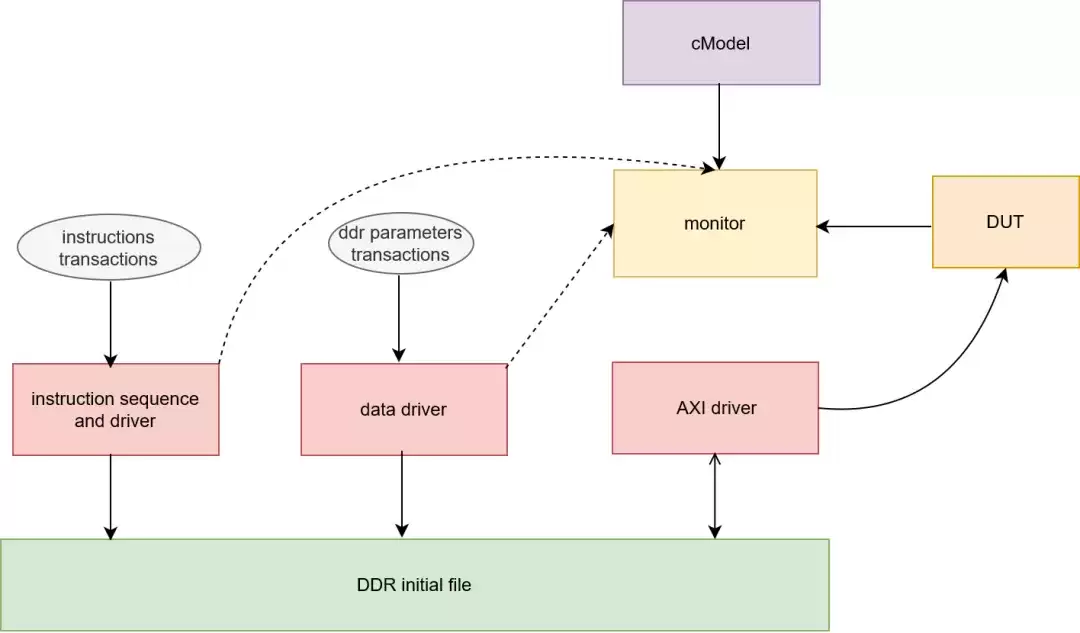
指令集验证需要一个称为C-Model的黄金参考模型。编译器生成的每一条指令,都得先用C-Model跑一遍,确保结果正确,才能交给硬件执行。同时,这个C-Model也会被集成到仿真环境中,作为判断RTL行为是否正确的“标尺”。
以UVM验证方法学为例,一个典型的验证环境会包含以下组件:
- 指令/参数随机化与驱动:生成大量随机的、有约束的测试指令和数据,灌入给C-Model和DUT(待测设计)。
- AXI总线驱动:模拟真实的内存读写行为,与DUT交互。
- 监测器:实时抓取DUT的输出,与C-Model的计算结果进行比对,自动报告差异。
5. 驱动:打通软硬件的“任督二脉”
驱动是软件控制硬件的桥梁。它的核心任务包括:将训练好的权重参数加载到DDR内存;通过配置寄存器来启动、控制翻跟斗;响应硬件中断,获取运算结果。
对于像Zynq这类集成了ARM核的SoC FPGA,驱动开发相对直接,是在嵌入式Linux环境下进行。如果加速卡是插在服务器上,则还需要涉及PCIe驱动开发。以SoC为例,让整个系统跑起来大致需要这些步骤:
- 完成RTL设计,生成比特流文件和硬件描述文件。
- 用SDK生成FSBL(第一阶段引导加载程序),完成芯片基础配置。
- 编译生成U-Boot、Linux内核和设备树文件。
- 将FSBL、比特流、U-Boot等打包成最终的BOOT.BIN。
- 选取一个根文件系统(如Linaro),制作SD卡镜像并启动设备。
6. 编译器:将模型“翻译”给硬件
编译器的作用,是将高层的深度学习模型(如PyTorch、TensorFlow导出)“翻译”并优化成翻跟斗能够理解的指令序列。可以借鉴TVM的思路。
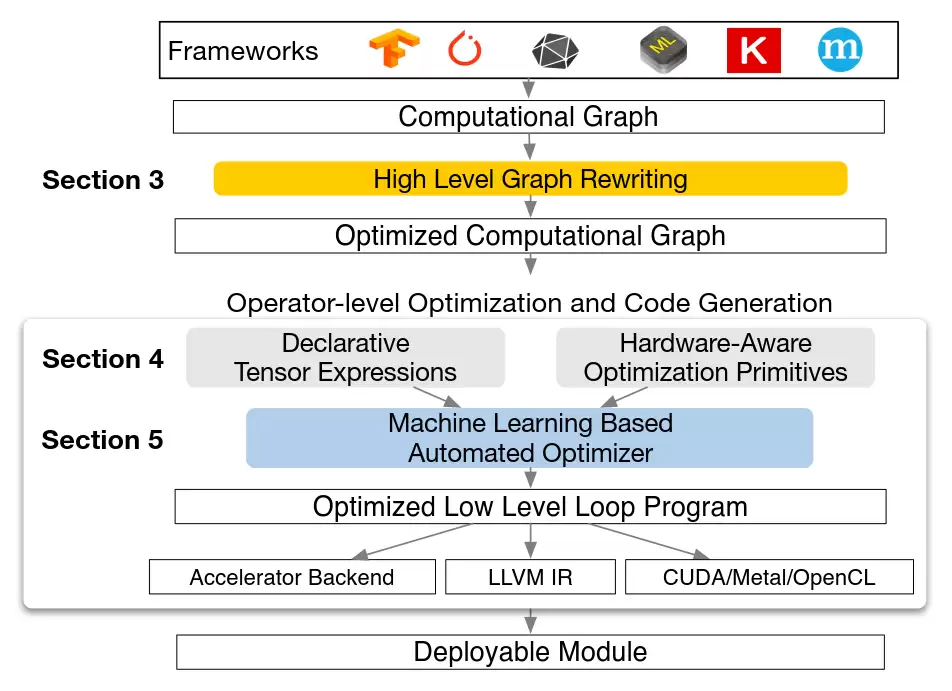
TVM作为一个旨在兼容多种硬件后端的编译器框架,其核心是计算图。它先将各种框架的模型统一转化为计算图表示,然后在这个图上进行一系列优化。与CPU编译器处理细粒度标量操作不同,AI翻跟斗的计算图节点通常是张量级的操作,这更贴合FPGA计算核的处理方式,也让图结构更简洁高效。
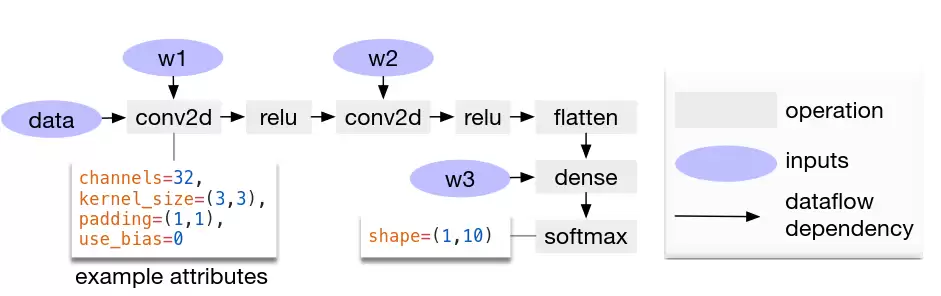
优化过程中的一个关键挑战是调度。一个张量运算(如矩阵乘法)可以被分解成多种步骤和顺序来执行,不同的“调度”方式对硬件资源的利用率和最终性能影响巨大。TVM甚至引入了机器学习的方法,来自动搜索海量的调度空间,寻找最适合目标硬件的最优解,然后再生成高效的指令。
7. 模型压缩:让硬件“轻装上阵”
为了让模型能在资源有限的FPGA上跑得更快、更省电,模型压缩几乎是必经之路。主流方法围绕两大方向:量化(降低数据精度,如浮点转定点)和剪枝(移除冗余的连接或通道)。具体的技术工具箱里包括:
- 二值化/三值化网络
- 权重及激活值的向量量化
- 知识蒸馏
- 张量的CP分解、Tucker分解等低秩近似方法
- 结构化与非结构化剪枝
- 自动化神经网络架构搜索与压缩
8. 软件部署:完成最后一公里
并非所有网络层都适合或用得到FPGA加速。例如,LSTM网络中的词嵌入层或最后的Softmax分类层,在CPU上执行可能更简单高效。因此,软件部署需要负责整体的流水线调度:在CPU和FPGA之间高效地切分任务、搬运数据、协调执行,并处理前后端的数据预处理、结果展示等应用逻辑,最终提供一个完整的、可交付的解决方案。
总结
回顾下来,一个完整的AI翻跟斗项目,从算法、编译器、软件部署,到驱动、硬件设计与验证,几乎覆盖了现代计算系统的全栈知识。这也意味着,成功的AI加速团队,往往是一个汇聚了跨领域人才的“联合舰队”,软硬兼修,协同并进,才能在这场效率的竞赛中脱颖而出。