RAG(检索增强生成)这个概念,说白了,就是给大语言模型配了个“外设知识库”。它通过动态调用外部数据,让模型回答更准、更新、更靠谱,有效解决了大模型满嘴跑火车(即“幻觉”)和知识陈旧的问题。下面我们先拆解一下它的核心。
技术原理与流程
RAG的工作流程很清晰,拆开来看就是三步走:
- 检索(Retrieval):根据用户的问题,从一个事先建好的知识库(比如用向量数据库)里,把相关的文档片段捞出来。这就像汽车客服系统里存了车型参数手册,你的问题来了,它就去手册里找最匹配的章节。
- 增强(Augmentation):把检索到的信息作为上下文,和原始问题打包,一起喂给生成模型。这一步相当于给模型的“记忆”做了个外部扩展,让它能基于最新、最专有的数据来思考。比如在医疗诊断中,RAG可以实时拉取最新的医学论文,帮助生成诊断建议。
- 生成(Generation):大语言模型结合上下文和问题,生成最终的回答。因为有检索到的事实信息兜底,模型输出不仅准确率大增,胡编乱造的概率也大幅降低。企业客服就是靠这个,一边引用内部文档生成合规回答,一边还能防止敏感数据外泄。
核心优势
那么,这套“外设”到底好在哪?几个核心优势很明显:
- 知识时效性:大模型训练数据有截止日期,但RAG可以动态调用外部知识库,实时抓取新闻、政策更新等,确保信息不过时。
- 领域适应性:通过定制一个专属知识库,比如法律条文库或医疗指南库,就能让通用的“万金油”模型,快速变成某个垂直领域的专家。
- 减少幻觉:回答是基于检索到的事实生成的,这从根本上降低了模型胡言乱语的风险,可信度自然就上去了。
- 成本效益:想扩展模型的知识范围?不用重新训练它,代价高昂的算力和时间成本都能省下来。
应用场景
道理讲完了,看看RAG在实际中都能干些什么:
- 智能客服:对接企业知识库,精准回答产品故障、政策咨询等问题。
- 医疗诊断:整合医学文献和患者数据,辅助医生做决策。
- 金融分析:调用实时市场数据生成投资报告,保证信息时效性。
- 教育问答:基于教材和学术资源,生成知识点解析。
之前一直没详细讲Dify的知识库检索,说实话,Dify在这块以前做得一般,跟同类的RAG方案比相对弱一些。考虑到这块知识确实有缺口,今天就来补上,重点看看在Dify的AI Agent和工作流里,怎么用好知识库。
先看AI Agent里的知识库检索。
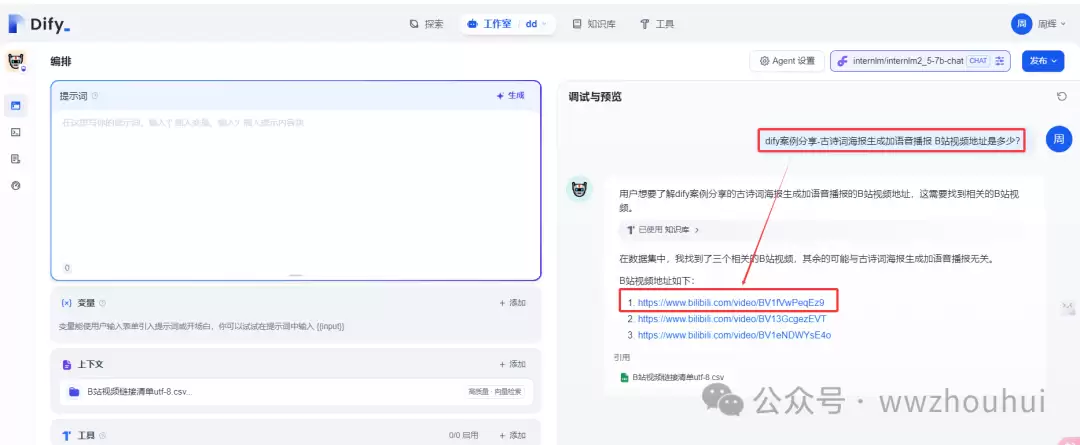
通过知识库检索到视频地址,我们打开验证,发现地址是对的。
接下来看看Dify知识库工作流。
这个工作流检索的是《清华大学第一弹:DeepSeek从入门到精通.pdf》这份文档。
通过这两个案例,我们可以看到如何用Dify实现知识库增强检索。下面,我们逐一拆解。
2. 模型配置
关于模型配置,之前发现有些小伙伴对大语言模型、向量模型和重排模型的关系还有点懵。这里我们就重点演示一下后两者的配置。
什么是向量模型
向量模型是一种数学模型,它的核心是把文本、图片等数据“翻译”成一个高维空间里的向量,方便计算机去做分析和计算。在RAG的语境下,它的任务就是把知识库里的文档转成向量。
简单来说,我们需要先对知识库文本做向量化,这样后续才能做相似度检索。相似度越高,检索出来的内容就越精准。比如我们输入“Deepseek能够做什么?”,我们希望模型是基于知识库里的内容来回答,而不是胡诌。所以,我们得先把这句话也转成向量,再到向量化的知识库里做相似度匹配。匹配上最相关的上下文后,再发给大模型总结并返回给用户。这样一来,我们收到的信息就跟知识库里的内容高度相关了。
在Dify的模型厂商设置里,我们需要添加支持 TEXT EMBEDDING 的模型。以“标准OpenAI-API-compatible”为例来演示。
添加这一步完成后,Dify就有了向量模型。目前硅基流动、阿里、智谱、火山引擎、gitee ai都支持,国外的OpenAI、OpenRouter也有。只要模型中带有TEXT EMBEDDING字样,就表示支持向量化。
什么是Rerank 模型
Rerank模型,也叫重排模型。它的作用是“二次优化”。为什么要用它?因为向量模型检索总有不那么准的时候,特别是当文档内容高度相似时,排在第一位的很可能不是我们最想要的答案。
这时候,就需要Rerank模型出场了。它会对第一次检索出来的相似结果进行重新评分和排序,让最相关的内容优先展示,从而提升查询的准确性。当然,这俩模型组合起来也解决不了所有知识库的准确性问题,这里就先不展开了。
同样,我们以“标准OpenAI-API-compatible”为例,选择Rerank类型。
上面提到的那些模型厂商也都提供Rerank模型。具体怎么找呢?以硅基流动的模型市场为例。
进入硅基流动,选择“嵌入和重排”。
这里会显示出嵌入模型(也就是向量模型)和重排模型,大部分是免费的。大家可以根据自己的需求选择。免费模型一般会有限速,追求稳定的话,可以选收费的Pro模型。这两个模型对Token的消耗非常低,10块钱能用很久。
以上两个模型在Dify里设置好后,最好在“系统模型”里优先选定,方便后续使用。
模型配置完成后,我们就可以开始创建知识库了。
3. 知识库创建
点击Dify最上方的“知识库”,然后“创建知识库”。
进入创建页面后,选择数据源。目前支持三种方式:1. 导入已有文本、2. 同步自Notion内容、3. 同步自Web站点。因为我们导入的是私有化知识,所以选“导入已有文本”。支持的格式很丰富,包括TXT、Markdown、PDF、Excel、Word等。
选择文件后,点击下一步。
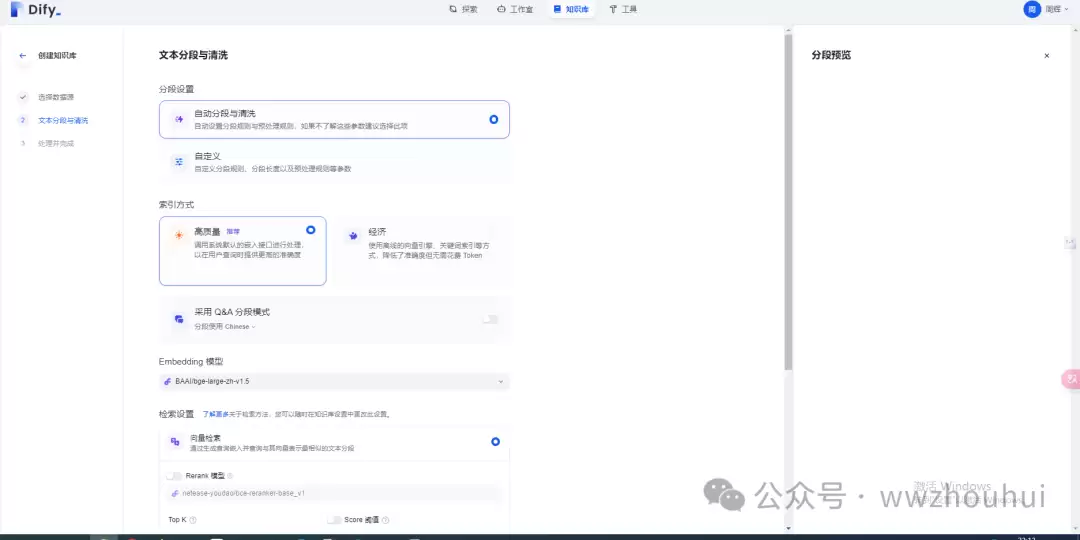
接下来会出现“文本分段与清洗”的设置界面。这里可以配置:
- 分段设置:可以选择自动分段和清洗,也可以自定义。
- 索引方式:有高质量、经济型、以及采用Q&A分段模式。
- Embedding 模型:选择之前系统设定好的向量模型。
- Rerank 模型:可以开启或关闭。
- 检索设置:包括向量检索、全文检索、混合检索。Dify新增的“父子检索”其实就是混合检索,效果会更好。如果不熟悉,点默认设置就行。
设置完成后,点击“保存并处理”。
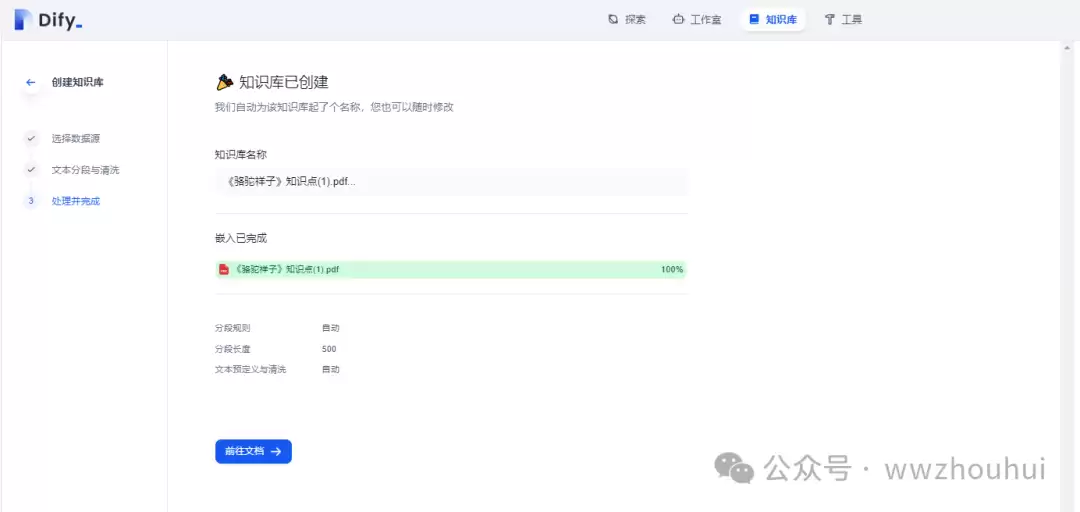
当画面出现“嵌入完成”,就表示文档向量化成功了,知识库已经就绪。
4. AI Agent 知识库
回到工作室,点击“创建空白页面”,选择“Agent”,给它起个名字。
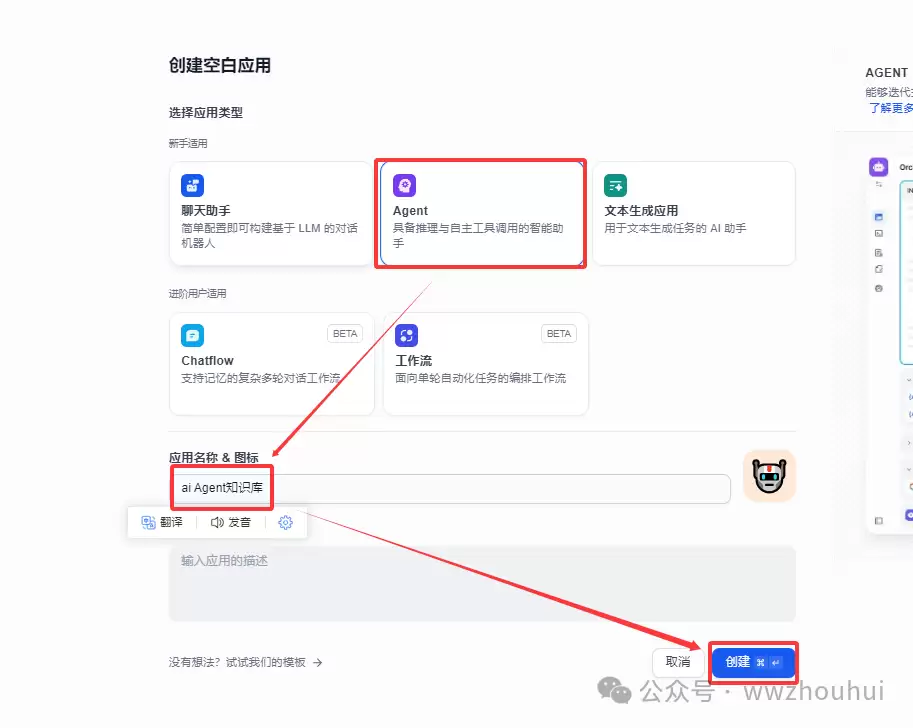
进入AI Agent的配置页面。
这里我们需要用到知识库,所以在“上下文”里添加我们刚建好的知识库。
添加完成后,就可以针对这个知识库进行对话了。
5. 知识库工作流
工作流搭建
回到工作室,点击“创建空白页面”,选择“Chatflow”,给它起个名字。
进入工作流编辑界面,我们可以在大语言模型节点中间添加一个“知识检索”节点。
打开知识检索节点,点击“知识库”添加我们刚建好的知识库。
添加完成后,下一个节点我们对接大语言模型(LLM)。
在LLM节点的“上下文”中,选择“知识检索”的 `result` 输出。
在“系统提示词”里,输入类似这样的提示词:
请根据文本内容{{#context#}}回答
其他设置可以保持默认,最后连接一个“直接回复”节点。
这样,一个简单的知识库工作流就搭建完成了。这个工作流相对简单,主要是为了演示知识库的原理和知识检索工作流组件的用法。其他组件的用法,可以参考之前的文章,这里就不展开了。
工作流测试
通过以上两种方式,我们完成了知识库在Dify中的两种主要用法:AI Agent和工作流。