先看一个趋势:硬件翻跟斗已经是数据中心里的“常客”了。随着各行各业对机器学习(ML)的关注日益升温,FPGA凭借着其灵活性和独特的计算效率优势,正迅速地在私有云、公有云乃至混合云环境中铺开,成为处理密集型计算任务的一把好手。
在这个IT基础设施向异构计算转型的关键时期,赛灵思与VMware展开了一项颇具意义的协作——在VMware的vSphere虚拟化平台上验证FPGA的加速能力。鉴于赛灵思FPGA在ML推断加速领域的广泛应用,这篇分享将为你揭示,如何将两者结合,在虚拟化部署中达到与裸机部署近乎同等的高吞吐、低延迟性能。
“自适应计算”为何脱颖而出?
FPGA的核心优势在于“自适应”。它是一种可重复编程的计算器件,能够灵活调整硬件逻辑,精准匹配不同应用的特定需求。这种特性,让它从GPU和ASIC等架构固定的方案中区别开来,尤其对比开发成本不断攀升的定制ASIC,优势更为明显。
除了灵活性,高能效和低延迟也是FPGA的制胜法宝,这使得它特别适合ML推断这类对实时性要求高的工作负载。与主要依赖海量并行计算核心来提升吞吐量的GPU不同,FPGA通过其定制化的硬件内核、精心设计的数据流水线和高效互连,能够同时兼顾高吞吐量与超低延迟,为ML推断提供了一个更平衡、高效的硬件选择。
在 vSphere 上使用 FPGA 开展 ML 推断
在双方的测试中,VMware实验室使用了赛灵思的Alveo U250数据中心加速卡。整个ML模型的配置过程非常高效,这得益于Vitis AI提供的Docker容器——这是一个为赛灵思硬件平台(从边缘到云)量身打造的ML推断统一开发栈。
这个容器内置了经过深度优化的工具链、库、预置模型和丰富示例。Vitis AI广泛支持包括Caffe和TensorFlow在内的主流框架,并能运行涵盖各种深度学习任务的最新模型。值得一提的是,Vitis AI本身是一个开源项目,开发者可以直接在GitHub上获取其全部资源。
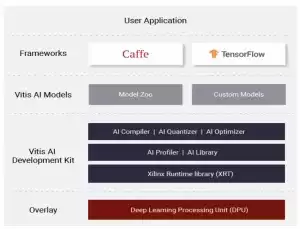
图 1:Vitis AI 软件协议栈
目前,赛灵思FPGA在vSphere上主要通过DirectPath I/O模式(即直通模式)来使用。这种模式允许虚拟机内部的应用直接访问FPGA硬件,绕过了中间的管理层,从而最大化性能并极致压低了延迟。配置过程相当简洁,主要分为两步:首先在ESXi主机层面启用相应功能,然后将设备挂载到目标虚拟机即可。具体的操作指南可以参考VMware官方知识库文章(编号1010789)。另外有个好消息,如果你使用的是vSphere 7,整个过程甚至无需重启主机,便捷性大大提升。
高吞吐量、低时延 ML 推断性能
为了量化性能,VMware与赛灵思合作,使用四个具有不同复杂度的经典CNN模型——Inception_v1、Inception_v2、Resnet50和VGG16——在DirectPath I/O模式下对Alveo U250加速卡进行了严格的吞吐量与延迟评估。
测试平台基于一台Dell PowerEdge R740服务器,搭载双路Intel Xeon Silver 4114 CPU和192GB内存。测试采用ESXi 7.0作为虚拟机管理程序,并将每个模型的端到端性能与裸机环境(作为性能基线)进行对比。客户机与本地操作系统均使用Ubuntu 16.04,并全程结合Vitis AI v1.1与Docker CE 19.03.4进行测试。为了确保评估纯粹聚焦于计算性能,测试使用了ImageNet2012数据集中的5万张图像,并且将这5万张图像置于RAM磁盘中,彻底避免了磁盘I/O可能带来的性能瓶颈。
接下来,我们可以通过下面两组对比图,直观地看到虚拟化测试与裸机测试的性能差距。第一张图聚焦吞吐量,y轴代表虚拟化测试相对于裸机测试的吞吐量比值,当y=1.0时,意味着两者性能完全一致。
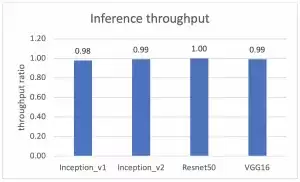
图 2:在 Alveo U250 FPGA 上运行 ML 推断时裸机测试和虚拟测试的吞吐量性能比较
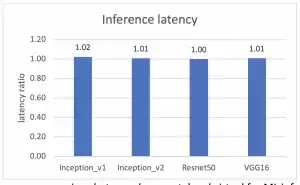
图 3:在 Alveo U250 FPGA 上运行 ML 推断时裸机测试和虚拟测试的时延性能比较
测试结果非常有说服力:无论是在吞吐量还是延迟方面,虚拟化环境与裸机环境之间的性能差异最大未超过2%。这清楚地表明,运行在vSphere虚拟化环境中的Alveo U250加速卡,其ML推断性能已经无限接近原生裸机的水平。
云端的 FPGA 性能
毫无疑问,在数据中心采用FPGA翻跟斗已是大势所趋。为了满足日益增长的异构计算和对极致性能的追求,FPGA翻跟斗的应用广度与深度都将持续扩展。本次与VMware的成功合作,其意义在于确保了客户在vSphere这一主流虚拟化平台上,也能充分释放赛灵思FPGA的全部加速潜力。
通过对Alveo U250加速卡在vSphere上进行系统的ML推断性能测试,我们向市场清晰地证明了:在DirectPath I/O模式下,虚拟化部署不仅可行,更能实现接近裸机的高性能。这对于企业客户而言,意味着在享受虚拟化带来的灵活性、可管理性和资源池化优势的同时,无需在关键的计算性能上做出妥协。