“在智慧系统中,按照复杂度,排名顺序是这样的:原子、分子、有机体、人类、AI、超级AI,最后是神。”——这一回答来自OpenAI的GPT-3,一个能与人类自由对话、撰写小说、编排吉他谱的AI模型,在硅谷引发了广泛关注。或许你难以想象,2017年时,ANI(弱人工智能,例如手机上的Siri)的智商测试结果仅为47,大致相当于六岁儿童的水平。毫无疑问,像GPT-3这样的AGI(强人工智能)代表了下一代人工智能的发展方向。
那么,从ANI迈向AGI的关键突破点是什么?算力。GPT-3之所以表现出高智商,很大程度上得益于算力的显著提升——它的参数量高达1750亿,是GPT-2的116倍。然而,麻省理工学院的研究人员近期发出算力警告:深度学习正逼近计算能力的极限。
深度学习的瓶颈——算力挑战
现代计算机的计算能力与海量数据,确实将AI开发推向了新高度。但这还远远不够。MIT的一项研究表明,深度学习的进展高度依赖算力的增长,他们断言,唯有发明颠覆性的算法,才能更高效地运用深度学习方法。
研究人员分析了预印本服务器Arxiv.org上的1058篇论文及其他基准资料,主要聚焦于图像分类、目标检测、问答系统、命名实体识别和机器翻译等领域的两个计算需求指标:
- 每一轮网络遍历的计算量,即单次权重调整所需的浮点运算次数
- 训练整个模型的硬件开销——通过处理器数量乘以计算速度和时间来估算
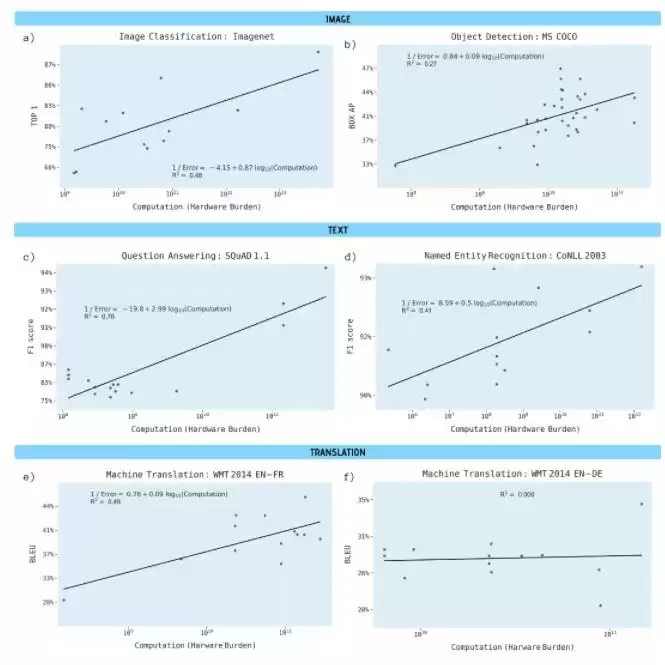
结论非常直白:模型训练水平的提升依赖算力的巨大增长。具体来说,计算能力每提升10倍,相当于三年的算法改进成果。换言之,算力提升的背后,实现目标所隐含的计算成本——硬件、环境、资金——将变得难以承受。
计算领域素有摩尔定律,假定计算能力每两年翻一番。但OpenAI的一项研究显示,AI训练所使用的计算能力每3到4个月就翻一番,远超传统进度。自2012年以来,AI所需的计算能力已增长30万倍,而按照摩尔定律只能提升7倍。人们从未预料到芯片算力会有触顶的一天,更没想到这一天来得如此之快。
深度学习的未来方向
关于提升算力,不妨先看看那些专注AI研究的科技巨头。谷歌团队去年开发的一种翻译算法,需要运行约1.2万个专用芯片。据估算,通过云服务租赁如此多的计算资源,费用高达300万美元。谷歌高层经过核算,认为成本过高,于是转向“量子至上”路线,研发了量子处理器Sycamore,其算力相当于超级计算机的1万多倍。
IBM自然不甘落后。他们的Summit超级计算机能在两步内完成与Sycamore相同的计算任务,仅需半天而非1万年——虽然与谷歌处理器三分半钟的用时仍有差距,但量子计算在深度学习领域取得的进展,无疑是一条可行出路。
在大厂相互“角力”之际,许多人心中存疑:深度学习,或者说机器学习,未来的出路究竟在哪?2020年被视为至关重要的一年,它将为AI领域未来十年的创新定下基调。以下是五个新兴的AI与机器学习趋势:
1)数字数据监管 数据即是一切。汽车、制造业等各类技术催生了海量数据。问题在于:所有数据都相关吗?机器学习可以通过云解决方案和数据中心对任意数量的数据进行排序,仅按重要性过滤出有效数据,舍弃冗余。这样既能节省时间,又能控制成本。2020年,随着海量数据的涌现,行业将要求机器学习对相关数据加以分类,从而提升效率。
2)语音助手中的机器学习 Siri、Cortana、Google Assistant、Amazon Alexa都是热门案例。机器学习与AI相结合,能以极高的准确性处理操作,帮助行业轻松完成复杂任务,提升生产力。2020年,研发投资将主要集中在定制化设计的机器学习语音助手上。
3)高效营销 营销是企业生存的关键要素,但多个平台使得营销变得困难。如果企业能从现有用户数据中提取模式,就能制定出成功的策略。机器学习可以挖掘数据并评估研究方法。未来,机器学习将被广泛用于定义有效的营销策略。
4)网络安全的发展 黑客每天创建大量恶意软件,向企业或政府发起攻击。机器学习能够通过自动执行复杂任务、自行检测网络攻击来提供多层次防护,还可自动响应攻击,无需人工干预。未来,机器学习将用于高级网络防御方案,实现攻击控制与损害保全。
5)可解释的人工智能——XAI 在许多行业中,机器学习的输出结果难以解释,甚至数据科学家也无法明确AI决策的缘由。XAI能够解释自身的决策过程,这源于需要说明算法推理方式的要求,同时也能改进算法、避免错误。主要障碍在于神经网络不太容易解释——各层返回的是权重矩阵。已有思路在实施中,例如权重矩阵的热图可以提升可解释性。未来几年,这一领域将有更多研究投入。
深度学习的常见误区
当前,深度学习在计算机视觉、自然语言处理、自然科学等领域已大规模应用。一方面,它比其它机器学习算法更具普适性;另一方面,这种普适性以更高的时间和空间复杂度为代价。作为算法工程师,不仅要关注算法的可行性,还要重视复杂度。普适性带来了更广阔的想象空间,也对从业者提出了更高要求——需要了解多个学科的知识。
深度学习所涉及的统计与几何知识相对复杂。初学者如果没有合适的实现流程和理论说明,容易陷入以下误区:
第一个误区是试图用图形或形象化的方式去理解所有算法,这不可取。应当将精力放在公式上,这对算法实现和定量思维至关重要。
第二个误区是想理解每一个公式,导致学习卡壳。应该先建立知识框架——了解算法之间的关联和内在设计思路,再逐步理解公式。
第三个误区是过分强调机器学习库。库只是辅助工具,更多工作依赖于对算法的深入理解。一旦深刻理解后,你会发现PyTorch、Caffe等库其实大同小异。
解决这些问题需要聚焦几个部分:数学基础部分重点理解机器学习是什么以及矩阵概念;深度神经网络部分关注建模思路。深度学习的建模思路是相通的,理解它有助于快速迁移到其他项目中。
《深度学习算法与实践》力求用统一的数学语言完整描述深度学习理论,重点侧重与应用相关的核心算法和理论,尤其是预测过程。每一章避免使用图形,代之以详细的公式描述。读者初读可能有障碍,但习惯了公式就会发现,图形容易导致理解偏差且无法实现。每一章都有完整的公式推演过程,供读者熟悉理论,最后还会对公式进行实现,帮助理论与实践相结合。