在图像处理领域,边缘检测与轮廓提取始终是极具挑战性的任务。微弱的纹理细节容易被过强的线条掩盖,而纹理本身又属于一种微弱的边缘模式,处理起来非常复杂。以往,多尺度空间表示是常用方法。回忆起早期开发移动端视觉平台时,为避免特征畸变,我们不得不手动关闭部分图像预处理功能。幸运的是,深度学习时代带来了转机——CNN模型提供了一种天然的特征描述机制,将图像预处理与视觉任务的特征学习融为一体,为这一难题提供了全新解决路径。
边缘提取
1. 整体嵌套边缘检测(HED)
HED是深度学习方法在边缘检测领域的经典之作。其核心亮点有二:第一,支持对整个图像进行端到端的训练与预测;第二,实现了多尺度、多层次的深度特征学习。该模型本质上是一个全卷积网络,通过侧面输出的深度监督机制,自动学习图像丰富而分层的表示。
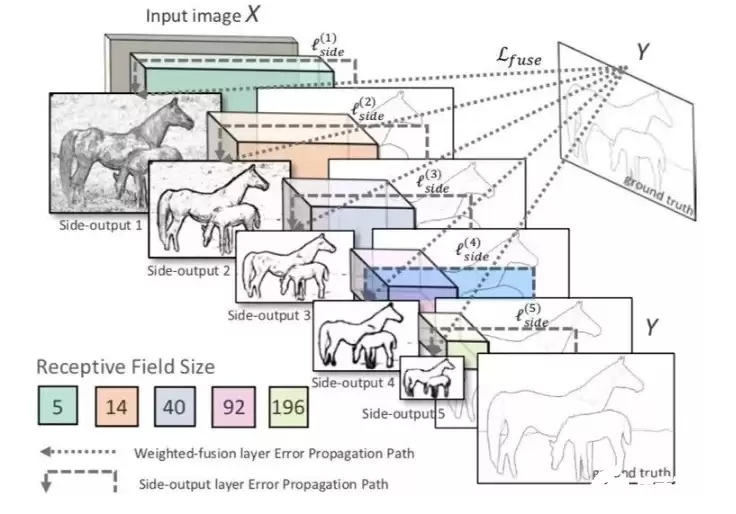
多尺度深度学习架构大致可划分为四类:多流学习、跳连网络学习、多尺度输入的单一模型以及独立网络训练。下图清晰展示了这些主流思路:(a) 多流架构;(b) 跳连架构;(c) 单模型处理多尺度输入;(d) 多个网络独立训练;(e) HED方案,它在单流网络中增加了多个侧面输出。

从模型复杂度与特征表示效率来看,前四种方法均存在一定冗余。HED作为一种相对简洁的变体,巧妙地在单一网络中通过多个侧面输出实现了多尺度预测。你可以将其理解为“独立网络”法的“集成嵌套”版——一个包含多个侧输出头的单一深度网络。这种对隐藏层施加监督的方式,已被证明能有效优化模型并提升泛化能力。如果需要整合输出,还能灵活地在融合层对多个侧输出进行加权组合。
具体来看HED的网络架构:它在卷积层后插入侧输出层,并对每个侧输出施加深度监督,引导其朝着边缘预测的目标优化。HED的输出是多尺度、多层级的:侧输出层的特征图尺寸越来越小,但感受野却越来越大。最终,一个加权融合层会自动学习如何最优地整合这些来自不同尺度的预测。整个网络通过多条误差传播路径(图中虚线所示)进行联合训练。
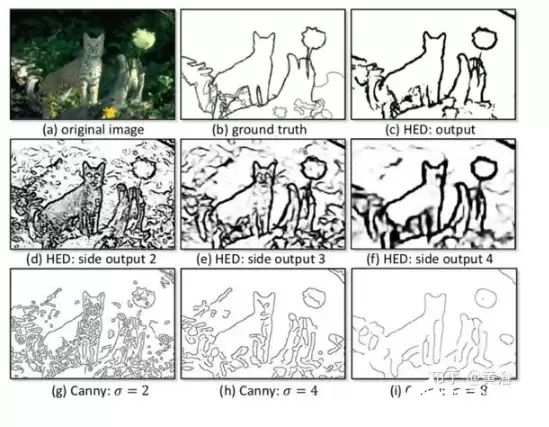
下面的实验对比结果能很好地说明问题。(a)是测试图像;(b)是人工标注的真实边缘;(c)是HED的检测结果;(d)、(e)、(f)分别是HED网络第2、3、4层的侧输出响应;(g)、(h)、(i)则是传统Canny边缘检测器在不同尺度参数(σ=2.0, 4.0, 8.0)下的边缘响应。对比可见,HED在边缘的一致性与完整性方面优势显著。
2. CASENet
如果说HED解决了“是否为边缘”的问题,那么CASENet的目标则更进一步:回答“这是哪一类物体的边缘”。它将每个边缘像素与一个或多个语义类别关联起来,是一种基于ResNet的端到端深度语义边缘检测架构。它同样采用跳连结构,让底层特征与顶层的类别激活图进行融合,并通过精心设计的融合层产生最终的多标签预测。
下图(a)-(c)对比了三种相关的CNN架构。图中的实心矩形代表卷积块的组合,宽度变窄表示特征图空间分辨率下降一倍。箭头旁边的数字是输出特征的通道数。其中,蓝色块是ResNet残差块,紫色块是分类模块,红色虚线框表示该输出会受到损失函数监督,灰色块是侧面特征提取模块,深绿色块是执行分组1×1卷积的融合分类模块。图(d)-(h)则是对图(a)-(c)中关键模块的细节展开。
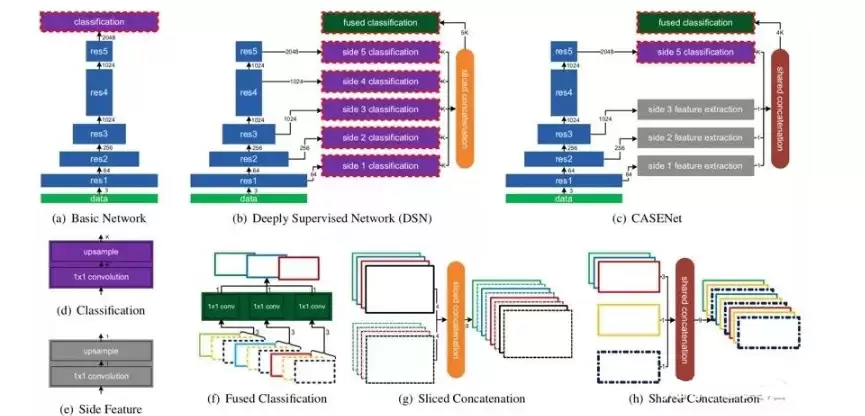
图(a)是基础网络。它以全卷积网络为框架,基于ResNet-101,移除了平均池化和全连接层,只保留底部卷积块。同时,将第一个和第五个卷积块(“res1”和“res5”)的步长从2改为1,并在后续卷积层中引入空洞卷积以保持原有感受野。在网络的顶端,添加了一个分类模块(见图(d)),它由一个1×1卷积层和双线性上采样层构成,最终产生K个与输入图像同尺寸的激活图 {A1, ..., AK}。每个激活图经过sigmoid函数后,就建模了像素属于第k类边缘的概率。
回顾一下HED,它的精髓在于除了顶层的损失外,还对底层的卷积侧输出施加监督,并通过线性融合各侧输出来得到最终边缘图。但HED仅仅做二值边缘检测。深度监督网络(DSN)对此进行了扩展,使侧输出和最终输出都具备K个通道,如图(b)所示。这个网络将分类模块连接到每个残差块的输出,产生了5个各有K个通道的侧分类激活图 {A(1), ..., A(5)}。然后,通过一个切片连接层(图(g)中颜色代表通道索引)将这5个激活图融合成一个5K通道的特征图Af:
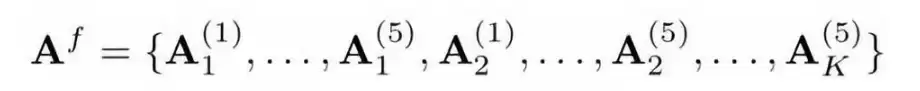
Af被送入融合分类层(执行K组1×1卷积,见图(f)),得到最终的K通道激活图A(6)。整个网络在{A(1), ..., A(6)}这6个激活图上计算损失,实现深度监督。
这种设计隐含地约束了每个侧输出激活图的每个通道,使其只携带与该类别最相关的信息。由于采用了切片连接和分组卷积,像素p的融合激活值由下式给出:
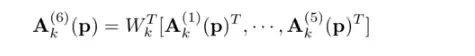
CASENet则在嵌套架构上做了关键改进:
① 将底部的分类模块替换为特征提取模块,只输出单通道特征图,而非K类激活。
② 只在网络顶部放置一个分类模块,并仅在此处施加监督。
③ 采用共享串联(图(h))代替切片连接。
具体来说,共享串联会复制底层的侧面特征F = {F(1), F(2), F(3)},分别与顶层的K个激活图中的每一个相连接:
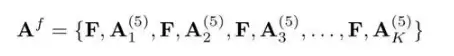
连接后得到的激活图,再送入执行分组卷积的融合分类层,最终生成K通道激活图A(6)。
简单来说,CASENet是一个联合进行边缘检测和语义分类的网络。它通过跳连结构,让具有丰富细节的低级特征参与到高级的语义分类决策中,从而提升了在复杂场景下的语义边缘检测质量。
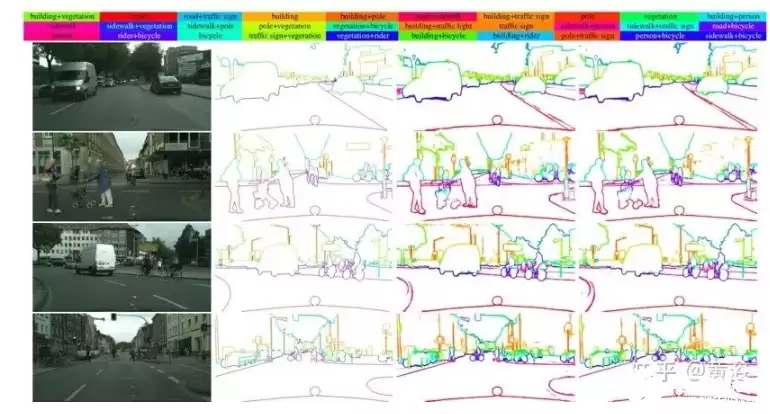
下图对比了CASENet和DSN的效果,从左到右分别是:输入图像、真实标注、DSN结果、CASENet结果。可以明显看到,在面对诸如自行车辐条这类具有挑战性的细长目标时,CASENet的检测质量更优,而DSN则在非边缘区域产生了更多误报。
轮廓提取
1. DeepEdge
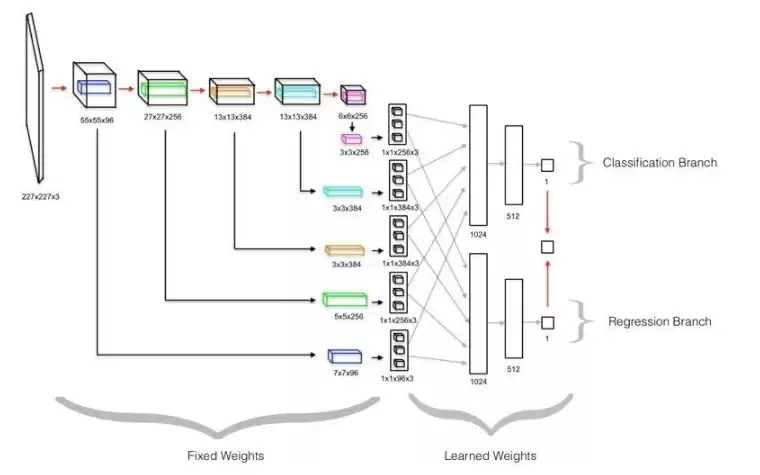
传统的轮廓检测大多依赖纹理、显著性等低级特征。DeepEdge的思路不同,它尝试利用与目标相关的高级语义特征作为检测轮廓的线索。其网络是一个多层级的深度模型,包含五个卷积层和一个分叉的全连接子网络。前五个卷积层使用预训练好的模型(如KNet),并同时处理输入图像的四个不同尺度版本。这四个并行的数据流,最终汇聚到两个独立训练的分支:一个分支学习预测轮廓存在的似然(分类任务),另一个分支则学习在给定点处轮廓的强度(回归任务)。
下图展示了DeepEdge的架构流程:首先,用Canny边缘检测器提取出候选轮廓点;然后,在每个候选点周围,裁剪出四个不同尺度的图像块;这些图像块分别通过同一个预训练好的KNet的五个卷积层。
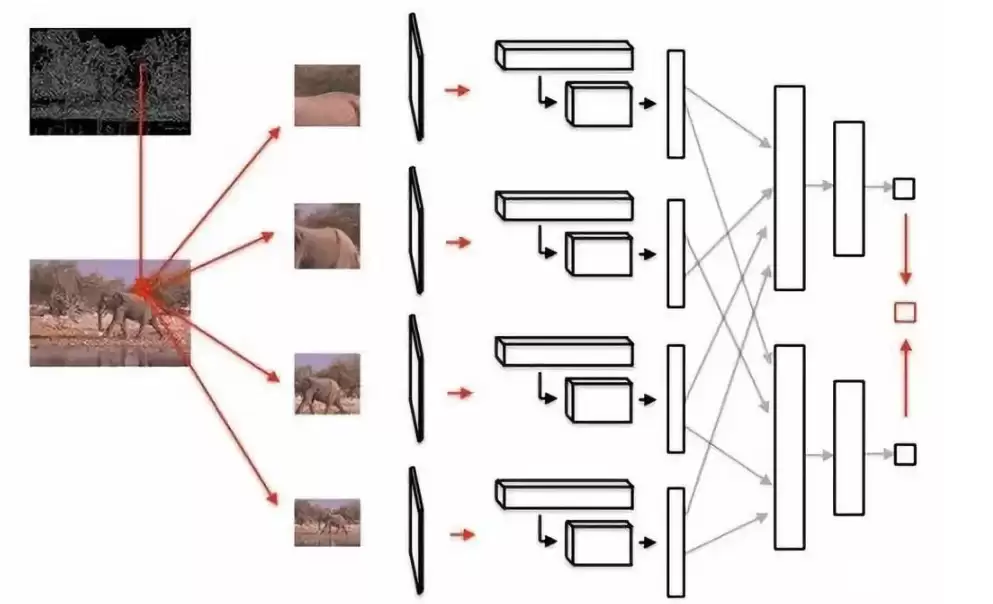
下图是一个单尺度的架构示意图,便于理解:以候选点为中心的图像块输入后,经过KNet的五个卷积层。为了提取高级特征,在每个卷积层的特征图上,围绕中心点取一个小子空间,并在该子空间上执行最大池化、平均池化和中心点池化。这些池化后的值被送入分叉子网络。在测试时,将两个分支输出的标量结果进行平均,得到最终的轮廓预测概率。
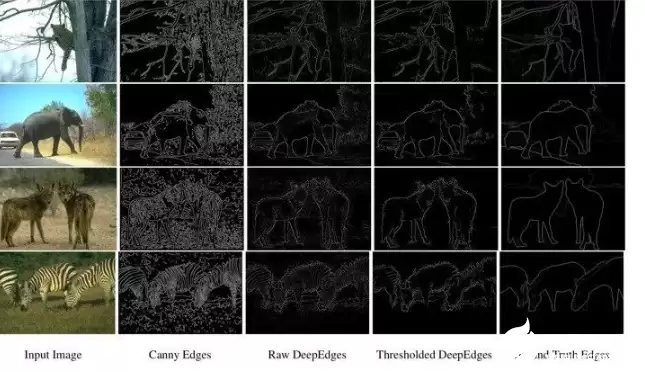
部分实验结果如下图所示,从左到右依次为:输入图像、Canny检测器生成的候选点集合、未经阈值化的预测概率图、阈值化(设阈值为0.5)后的二值轮廓图,以及真实标注的基础事实图。
2. 全卷积编码器-解码器网络(CEDN)
另一种思路是采用全卷积的编码器-解码器网络进行轮廓检测。CEDN就是一个典型的例子,它能够进行端到端训练,其数据来源于对PASCAL VOC数据集中不够精确的多边形标注进行修正后得到的轮廓图。其网络架构如下图所示。

该方法的实验效果如下图所示。从左到右依次是:(a) 输入图像;(b) 真实轮廓标注(GT);(c) 使用预训练CEDN模型的检测结果;(d) 使用经过精细调优后的CEDN模型的检测结果。经过微调,模型的轮廓检测能力有明显提升。

参考文献
1. G Bertasius, J Shi, L Torresani,“DeepEdge: A Multi-Scale Bifurcated Deep Network for Top-Down Contour Detection”, CVPR, 2015
2. S Xie, Z Tu,“Holistically-Nested Edge Detection”, ICCV 2015
3. W Shen et al.,“DeepContour: A Deep Convolutional Feature Learned by Positive-sharing Loss for Contour Detection”, CVPR 2015
4. Z Yu et al.,“CASENet: Deep Category-Aware Semantic Edge Detection”, CVPR 2017