UI 自动化测试领域长期存在多项棘手难题。测试用例平台积累了大量描述性用例,却无法直接执行,QA 需要逐条手动翻译——理解业务逻辑、编写元素定位、调试执行路径,一个中等规模的模块可能就要耗费数人天。用例失败后的排查流程更是繁琐:查看截图、对比页面、判断原因、修改脚本、重新执行,若失败原因为弹窗遮挡或流程变更等非显性因素,调试成本会急剧上升。再加上 iOS、Android、HarmonyOS 三端各写一套脚本,UI 改版时三套同步失效,维护工作量直接翻倍。

从根本上看,传统方案假设“UI 不变”,因此需要人工维护定位器;而我们团队设计的 ai_uitester 则假设“UI 一定会变”,让 AI 去理解变化、适应变化。这不是工具层面的简单升级,而是测试范式的根本转变——从“代码驱动”转向“视觉驱动”,从“人工调试”转向“AI 自愈”,从“三端分离”转向“统一抽象”。
一、为什么需要 AI Native 的 UI 测试
传统方案的三大痛点
痛点一:用例迁移成本高昂。测试用例平台积累了大量描述性用例,但不可直接执行。QA 需要逐条手动翻译:理解业务逻辑、编写元素定位、调试执行路径。一个中等规模的模块,转化成本可能需要数人天。
痛点二:调试效率低,人工介入多。用例失败后的排查流程是:查看截图、对比页面、判断失败原因、修改脚本、重新执行。当失败原因为“弹窗遮挡”“流程变更”等非显性因素时,调试成本极高。
痛点三:三端各写一套,维护成本翻倍。iOS、Android、HarmonyOS 的元素定位方式完全不同,UI 改版时三套脚本同步失效。
AI Native 的解法
ai_uitester 提出的解决思路,不是给传统框架打补丁,而是重新设计执行模型。

二、能力一:用例平台数据自动转化
问题场景
内部测试用例平台导出的 JSON 是多层树形结构,包含目录节点和用例节点,每条用例携带面包屑路径、优先级、标签等字段。以某业务模块为例,这个结构包含数百个节点、上百条测试用例,最大深度十多层。传统方式下 QA 逐条手动翻译,完成上百条用例的转化需要耗费数人天。
解决方案:自动化 Pipeline
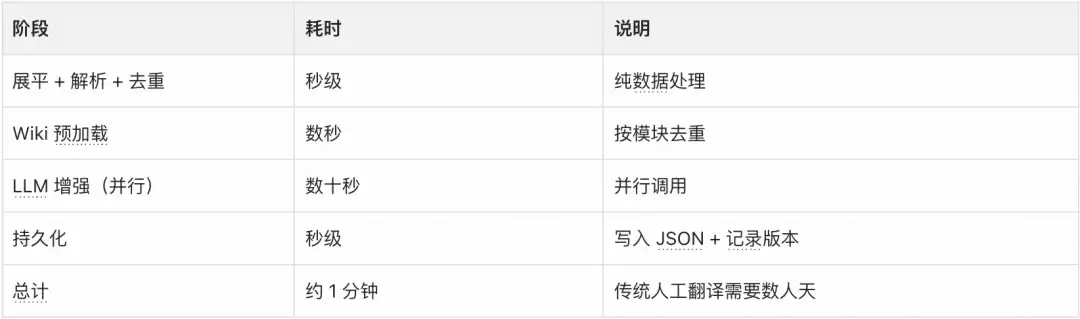
ai_uitester 设计了自动化 Pipeline,将用例平台 JSON 自动转化为可执行脚本。
平台JSON导出 ↓Phase1: 树结构展平 — 提取所有叶节点及面包屑路径 ↓Phase2: 用例解析 — 面包屑路径 → 结构化用例数据 ↓Phase3: 去重 — 与已有 suite 去重 ↓Phase4:LLM增强 — 生成可执行步骤 + 注入Wiki知识 ↓Phase5: 持久化 — 写入配置文件 ↓Phase6: 版本归档 — 记录版本历史
核心阶段:LLM 增强
LLM 增强模块负责将“描述性用例”转化为“可执行脚本”。输入是用例平台的 Checkpoint 描述,比如“某列表正常展示,可滑动查看更多”,输出是包含 App、Tap、Wait、Assertion、Swipe 等步骤类型的完整 JSON 脚本。
Prompt 工程:让 LLM 生成高质量步骤
StepGenerator 使用精心设计的 Prompt,关键约束包括步骤类型规范,每种类型都有严格的 Instruction 格式。
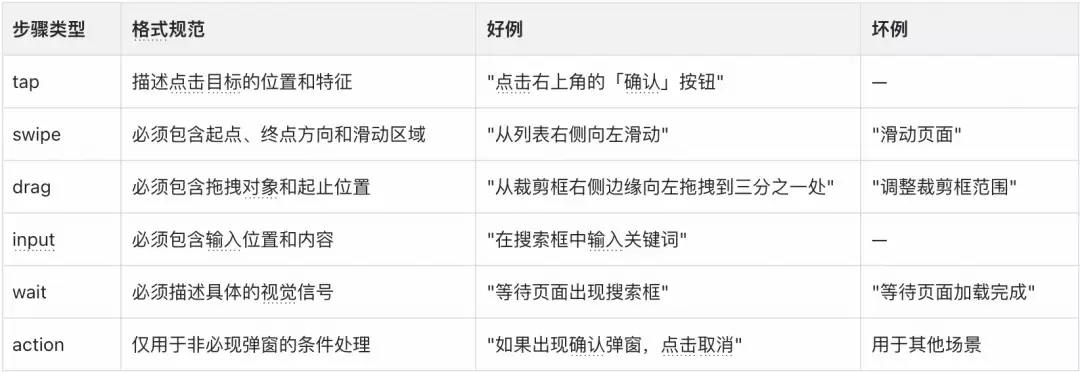
关键设计决策:条件弹窗用 Action 类型,弹窗存在时处理、不存在时自动跳过;不规范步骤自动降级,校验器会兜底,宁可修正也不丢弃;每个用例必须包含 App 步骤,否则校验直接报错。
并行增强与断点续传
LLM 增强支持高并发处理,并实现模块级 Wiki 预加载——同一模块的用例共享同一份 Wiki 内容,避免重复调用。Pipeline 每个阶段完成后写入检查点文件,中断后自动跳过已完成阶段。增强完全失败时,会构造 Fallback 用例,名称通过多级降级策略确定。
实际效果
Wiki 知识库:消费全景与核心原则
Wiki 知识库不是独立的文档集合,而是嵌入 ai_uitester 多个核心模块的基础设施层。它被 5 大场景消费:
- 用例增强阶段:将 Wiki 知识注入用例生成,使生成步骤更精确;
- 自愈诊断阶段:按模块加载 Wiki,辅助 LLM 区分“UI 变更”和“用例描述错误”;
- 运行时执行阶段:每次操作时注入索引,LLM 遇到盲区时按需加载对应页面;
- 技能消费:多个下游技能读取 Wiki 作为背景知识;
- 反馈闭环:每次执行后记录查找日志,持续优化匹配策略。
Wiki 质量直接影响三个核心指标。

“宁缺毋滥”原则贯穿始终——五层降级匹配(精确匹配→去除优先级后缀→去除括号→LLM 语义匹配→跳过并缓存)确保注入 Prompt 的知识准确可靠,因为错误知识比无知识更有害。
三、能力二:AI 智能调试与用例自愈
传统调试的困境
用例失败后的排查循环:失败→查看截图→判断原因→修改脚本→重新执行→又失败……,一个用例可能需要多次调试才能通过。
AI 智能调试模式
ai_uitester 内置了 AI 智能调试模式,实现自动诊断和自愈修复。
用例执行(while循环,支持动态步骤变更) ↓ 步骤失败失败分类器(规则引擎) ├─ device /timeout/ network → 自动换机或重试 └─ business → 进入 AI 诊断 ↓AI 诊断(VLM) ├─ 输入:✓✗○ 标注的步骤 + 错误信息 + 失败截图 + Wiki 知识 └─ 输出:diagnosis + confidence + complete_steps + resume_from_index ↓┌──────────────────────────────────────────────┐│ 置信度 >= 阈值 │ 置信度 < 阈值 ││ → 自动应用修复 │ → 弹出人工审核││ → 替换执行步骤 │ → 展示步骤 diff ││ → 从 resume_from_index│ → 超时倒计时 ││重新执行 │ → Accept/Reject ││ → 执行通过 → 固化用例 │ → 超时自动 Reject││ → 执行失败 → 回退原用例││└──────────────────────────────────────────────┘
失败分类器:先过滤,再诊断
不是所有失败都需要 AI 诊断。系统通过规则引擎过滤设备故障、超时、网络问题等非业务失败,自动重试;只有业务逻辑失败才进入 AI 诊断流程。
五类根因诊断
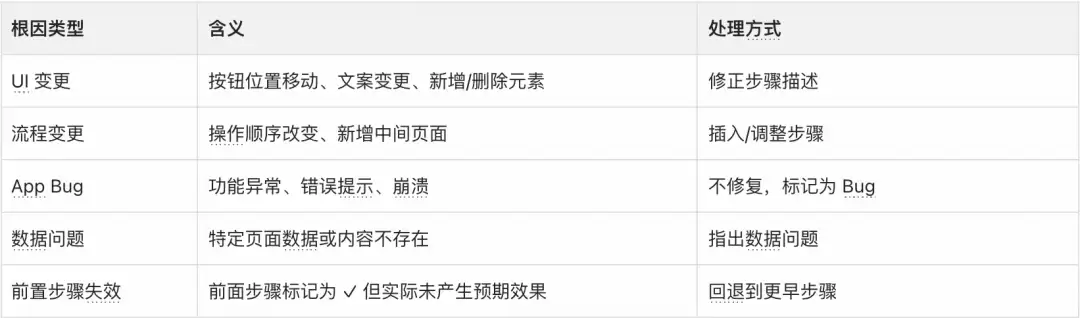
三个真实自愈案例
案例一:UI 变更——功能按钮位置移动(Confidence: 0.9)
原始:[tap]点击底部工具栏的某功能按钮 → 失败:找不到按钮修复:[tap]点击页面顶部功能菜单栏的对应按钮
案例二:UI 变更——进入页面需要额外操作(Confidence: 0.8)
原始:[tap]点击入口 → 失败:点击后未进入目标页面修复:在步骤后插入等待,然后重新点击[tap]点击入口[wait]等待目标页面加载完成 ← 新增[tap]再次点击入口按钮← 新增
案例三:前置步骤失效——弹窗遮挡导致后续步骤全部失效(Confidence: 0.9)
冷启动 App 后弹出确认弹窗,遮挡了首页。AI 诊断洞察到中间步骤虽标记为 ✓ 但实际未产生预期效果,诊断结果为“前置步骤失效”,将执行指针回退到步骤 2,并在启动 App 后插入条件 Action 处理弹窗。
置信度机制:宁可漏点,不可误点
在自动化测试中,“点错位置”比“没有点”危害大得多。
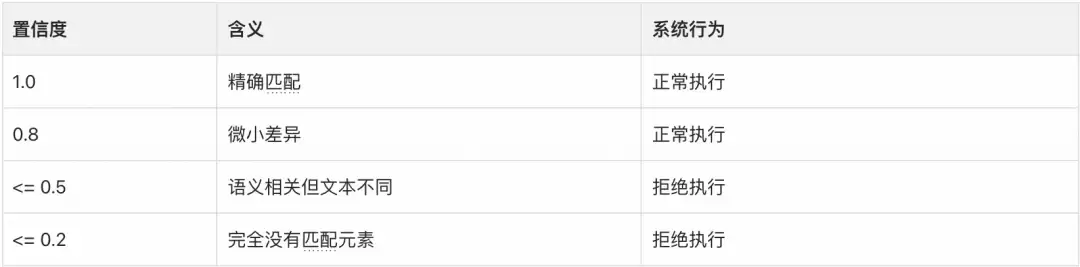
两条铁律:(1) MatchedText 必须从截图中逐字符复制,不允许脑补;(2) 宁可不点击,也不点错。
四、能力三:VLM 驱动的跨平台统一
VLM 方案的革命性
ai_uitester 的核心执行模型是“截图→理解→执行”闭环。VLM 看到的是像素级截图,而非 DOM 结构。这意味着:跨平台天然统一(同一套指令三端通用)、天然免疫 UI 变更(按钮移位照样能找到)、所见即所得(测试逻辑与人类看到的界面完全一致)。
统一 API 接口
执行引擎提供涵盖操作、断言、查询、等待等类别的统一 API,屏蔽底层平台差异。
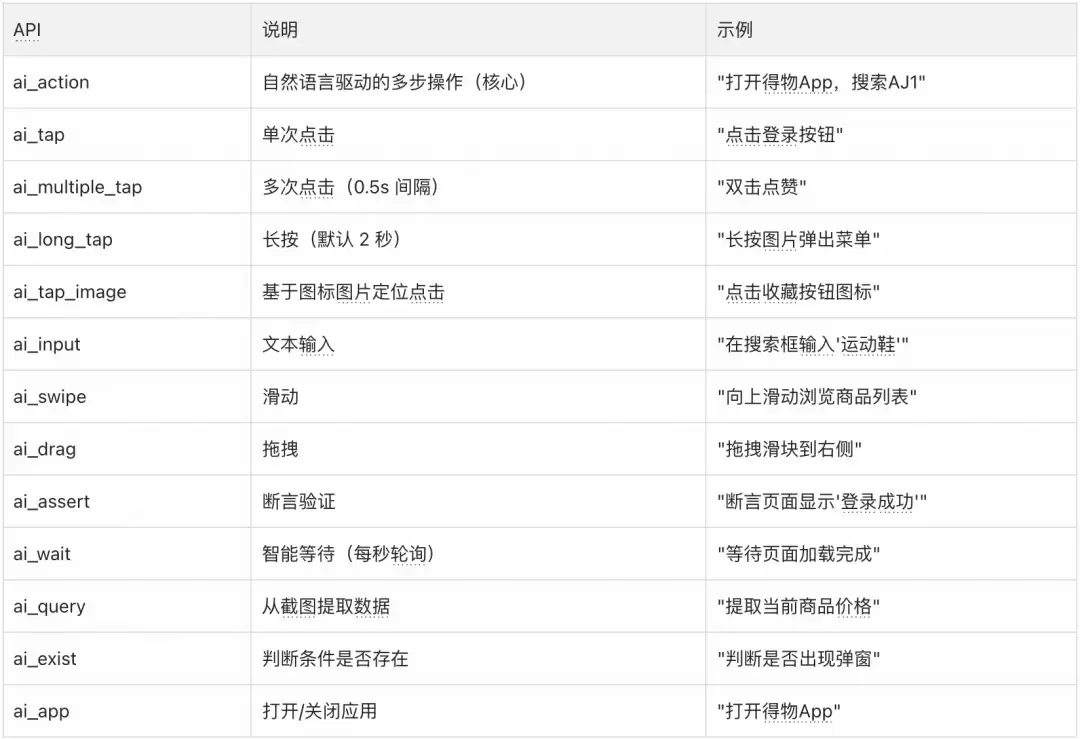
同一条 JSON 脚本在 Android、iOS、HarmonyOS 上都能执行,无需任何修改。
底层驱动自动选择
根据设备类型自动选择对应的底层驱动框架,上层代码完全无感知。
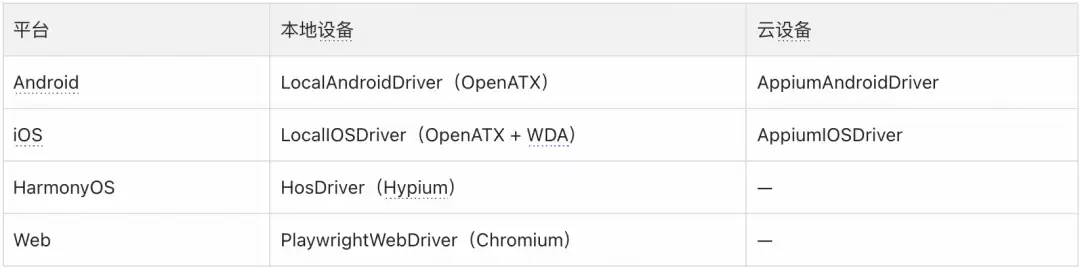
核心执行引擎:BaseAIDriver
BaseAIDriver 作为全平台驱动的抽象基类,实现了“截图→大模型解析→决策执行→记录日志→重新截图”的感知-决策核心循环,该循环最多执行 20 轮,点击操作配套置信度校验机制,查询知识库后还会强制继续运行。
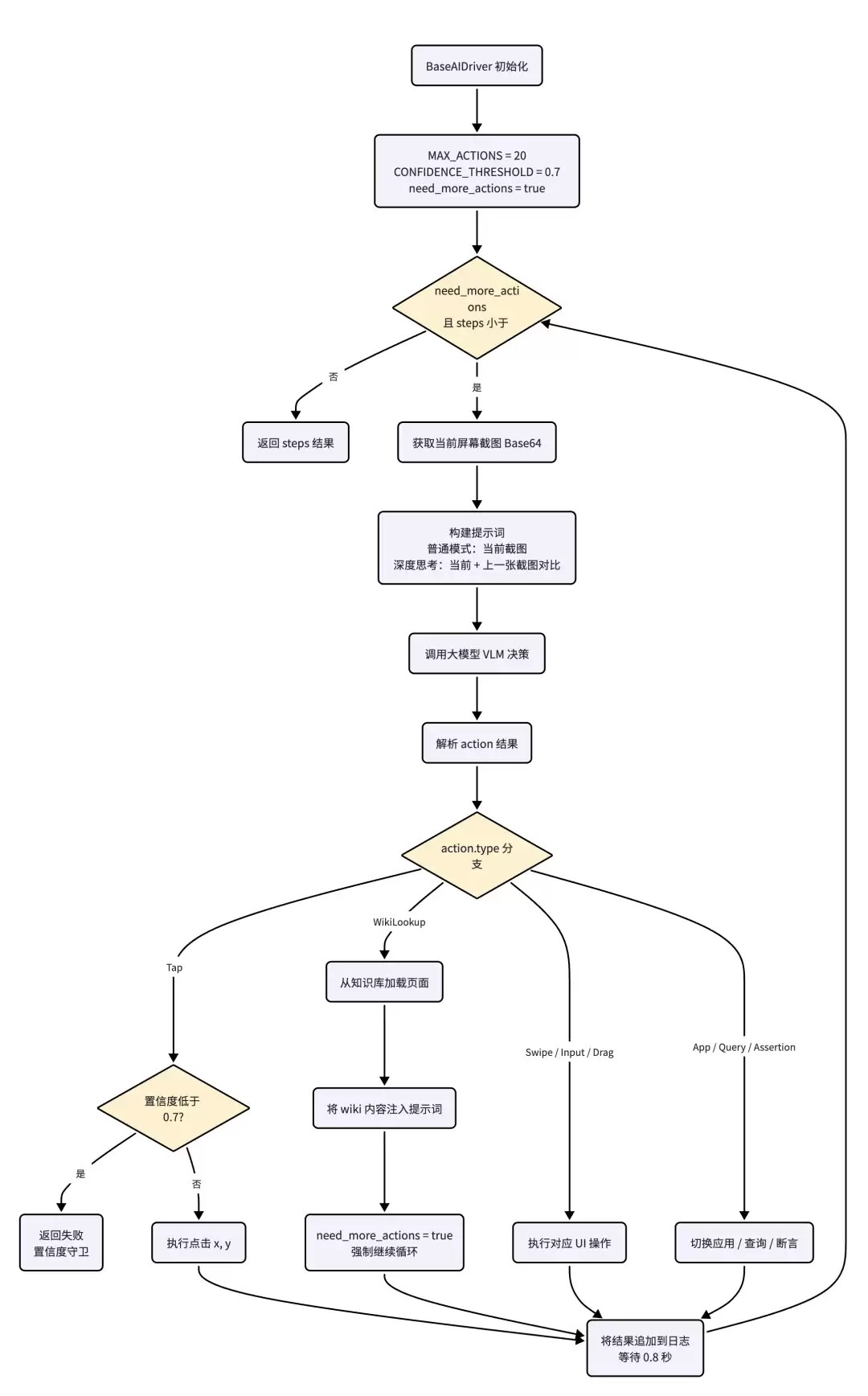

Prompt 工程的四大约束
- 约束一:每次只做一个动作。每步操作后屏幕状态变化,逐步执行确保每步决策基于最新画面。
- 约束二:元素匹配的严格规则。MatchedText 必须从截图逐字符复制,Confidence <= 0.5 时必须返回 Action: Null。
- 约束三:高优先级知识自动注入。弹窗、权限、登录页等无需在用例中显式编写,VLM 自动处理。
- 约束四:平台差异化适配。Prompt 根据平台自动切换系统操作指令,上层代码无感知。
深度思考模式
开启深度思考模式后,模型获得子目标分解、进度跟踪(✓/→/○ 可视化)、前后截图对比三项能力,适用于复杂业务流程。
五、架构设计取舍
为什么“逐步执行”而非“一次规划”?UI 测试的核心挑战是状态不确定性——每步操作后屏幕变化,预先规划可能基于过时信息。代价是单次操作可能多轮 LLM 调用(最多 20 轮),通过深度思考子目标分解来平衡。
为什么置信度阈值设为0.5?经过大量实测调优,在准确率和覆盖率之间取得平衡——阈值过高则大量操作被拒绝、执行效率低,阈值过低则误点风险上升。当前阈值确保“通过即正确”的高可信度。
为什么自愈返回完整步骤列表而非增量 Diff?增量 Diff 在多次修复后索引容易偏移,完整列表更直观可靠。Token 消耗更大,但避免了“修复引入新 Bug”。
六、行业对比:为什么是"新范式"
目前业界 UI 自动化测试主要有三条技术路线,我们从核心技术栈、跨平台能力、维护成本、自愈能力四个维度做一次系统对比。
传统方案:Appium / Selenium / XCUITest
核心原理:基于元素定位——通过 ID、XPath、Accessibility ID、Class Name 等定位器找到 UI 元素,再执行 Click/Input/Swipe 等操作。底层通过各平台的 Accessibility API 或 UIAutomator 获取 View Tree/DOM 结构。
典型代码:
# Android(Appium)driver.find_element(By.ID,'com.example.app:id/btn_login').click()# iOS(XCUITest)app.buttons['登录'].tap()# HarmonyOS(Hypium)driver.find_component('登录').click()
优势:执行速度快(单步操作毫秒级),社区成熟,CI/CD 集成方案完善,断言能力丰富。
劣势:
- 跨平台重复建设:同一功能三套脚本,三套定位器。一个按钮,Android 用 resource-id,iOS 用 accessibilityLabel,HarmonyOS 用 componentId,三端定位器完全不同;
- UI 变更即失效:按钮文案从“下一步”改为“确认”,定位器失效;页面改版增加一层嵌套,XPath 断裂。一个中等规模 App 每次版本迭代约 15-30% 的用例需要修改;
- 维护成本线性增长:用例数越多,维护成本越高。大规模用例集的回归,一次 UI 改版可能需要数周的修复时间;
- 无自愈能力:失败即停,需要人工介入判断原因并修改脚本。
AI 辅助方案:Test.ai / Applitools
核心原理:该方案在传统自动化框架基础上叠加 AI 能力,主要分为两大实现方向。AI 元素定位(Test.ai)依靠 CV 或 NLP 模型替代硬编码的 ID/XPath,可通过截图区域视觉特征匹配元素,或是以自然语言描述替代定位器;AI 视觉对比(Applitools)借助 VLM 对比截图 Diff,自动判断“是否视觉回归”,但不会替代底层执行引擎。
优势:降低了定位器维护成本,自然语言描述比 ID 更具可读性,视觉回归测试能发现传统断言遗漏的 UI 问题。
劣势:
- 本质仍是元素定位:虽然用 AI 做了"柔性匹配",但执行模型没变——仍然需要找到元素、点击元素。当元素不存在(UI 真的变了),AI 定位也找不到;
- 跨平台仍需适配:Android 和 iOS 的截图分辨率、字体渲染、组件样式不同,AI 模型需要平台特异性的训练或适配;
- 自愈仅限于重定位:如果按钮从底部移到顶部,AI 定位能找到它;但如果交互流程变了(新增中间页面、操作顺序改变),AI 定位毫无办法。这是"元素级自愈",不是"流程级自愈";
- 无业务理解:不知道业务规则,不知道为什么某个步骤失败,只能报告"找不到元素"。
AI Native 方案:本文 ai_uitester
核心原理:以 VLM 为执行引擎,以“截图→理解→执行”闭环替代元素定位。VLM 不仅识别 UI 元素,还理解页面语义、业务流程和上下文。知识库(Wiki)将业务规则与测试执行解耦。
典型代码:
{"steps":[ {"type":"tap","instruction":"点击底部导航栏第一个Tab「社区」"}, {"type":"tap","instruction":"点击页面右上角的发布按钮"}, {"type":"assertion","instruction":"断言页面出现功能入口"}]}
同一段 JSON 脚本,Android、iOS、HarmonyOS 三端通用,无需任何修改。
与传统方案和 AI 辅助方案的核心差异:
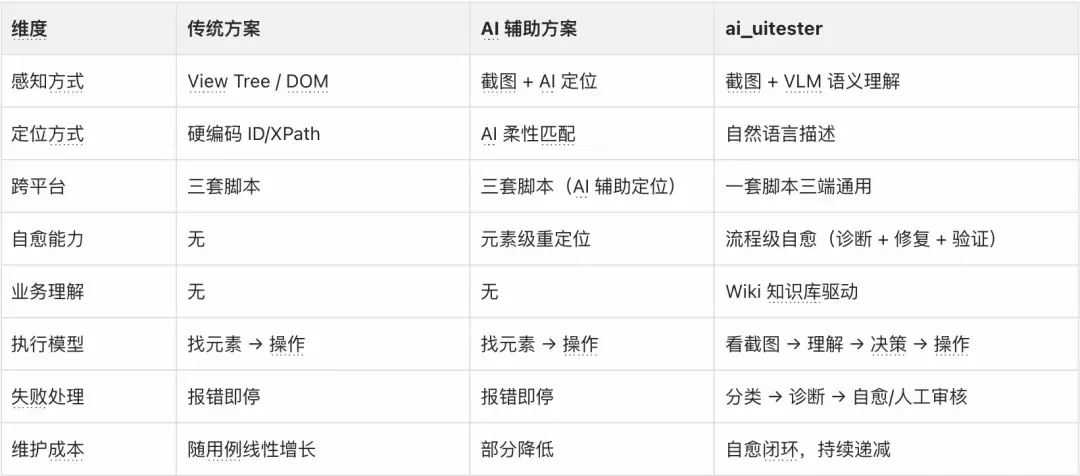
三条路线的演进关系
三者的关系不是替代,而是能力维度的跃迁:
传统方案(Appium) └─ 解决"能不能测"→ 提供基础执行能力 └─AI辅助方案(Test.ai)└─ 优化"好不好测"→ 降低定位器维护成本└─AINative方案(ai_uitester) └─ 重新定义"谁来测"→ 从人驱动变为AI驱动
关键差异一句话总结:传统方案和 AI 辅助方案的假设是“UI 不变”,所以需要人维护定位器;AI Native 方案的假设是“UI 一定会变”,所以让 AI 理解变化并适应变化。这是测试哲学的根本转变——从“抵抗变化”到“拥抱变化”。
七、业务成果数据
ai_uitester 在得物 App 客户端测试中已落地运行,核心指标如下:
核心效率指标
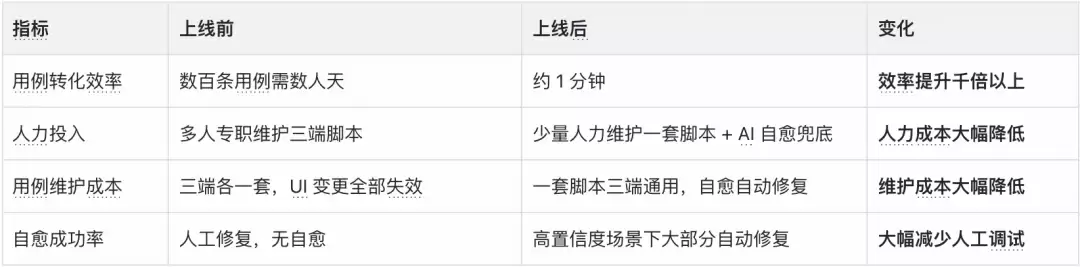
质量提升指标
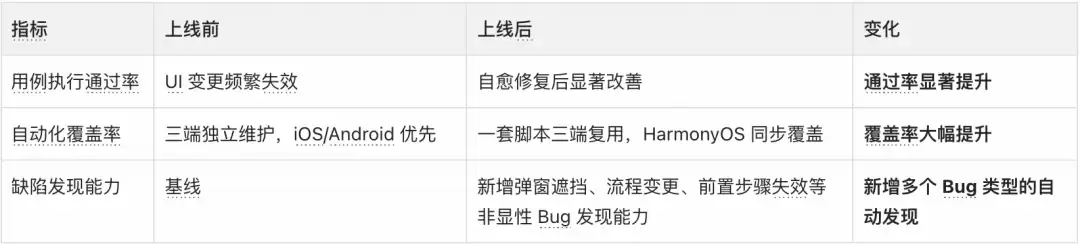
注:自愈成功率受知识库质量和执行场景影响,复杂流程变更仍需人工确认。以上数据基于多个核心业务模块的实测均值。
八、总结
ai_uitester 代表了 AI Native 的 UI 自动化测试新范式。

这不仅是工具的升级,而是测试范式的转变——从“代码驱动”转向“视觉驱动”,从“人工调试”转向“AI 自愈”,从“三端分离”转向“统一抽象”。Wiki 知识库的闭环设计确保了这不是一次性工具,而是越用越智能的测试基础设施。