“物理AI的ChatGPT时刻已经到来。”
2026年1月5日,拉斯维加斯CES展会,英伟达创始人兼CEO黄仁勋宣告AI正式进入新阶段。
他眼中,AI演进分四步走:Perception AI、Generative AI、Agentic AI、Physical AI。模型得理解质量、摩擦、惯性、动量守恒这些概念,AI才算真正走出屏幕。同时他也点明:想让机器人理解物理世界,光靠单一模型不行,得搭建一整套智能系统。
愿景很美,但核心问题摆上台面——物理世界的AI,到底需要什么技术能力?
AI真要渗透到物理世界,机器人、无人机、安防摄像头、可穿戴设备这些场景,要的不是单纯回答问题,而是持续工作。物理AI最核心的,就是主动执行的能力。
Om AI联汇CEO兼首席科学家赵天成博士点明了现状:“之前整个业内对通用视觉智能的关注度偏低,大家可能更关注一些能看秀的表演或操作场景。但通用视觉这个点,是未来物理AI规模化落地绕不开的核心技术,而且是更现实、更直接的那条路,会广泛渗透到所有物理AI场景。” 通用视觉智能(General Vision Intelligence),说白了就是模型得像人一样持续观察环境、精准锁定目标、自己驱动行动,而且这一切得在端侧完成。
最近发布的VLX端侧流式多模态模型系列,就是这个方向的最新实操。
这是业界头一回提出“流式多模态”这个全新模型架构。跟传统路线“采集-上传-离线处理”不同,VLX系列专门针对物理世界不断涌入的视频流设计,能实现毫秒级实时感知,并且首次在端侧打通了“持续感知→精准定位→行动决策”的完整闭环。
一、三个模型、三层能力、一条链路
通用视觉智能到底指什么?
Om AI联汇的定义很清晰:三项核心能力——持续感知(不用人工触发)、空间智能(精准定位目标)、行动输出(直接驱动设备)。VLX系列里的Flow、Seek、Go三个模型,正好分别对应这三项能力:
VLX-Fow是持续感知层:
传统视频AI怎么工作的?截帧、上传、问答,每次都是离散处理,观测有断档。VLX-Fow直接上流式视频输入架构,图像数据流不间断送进模型,持续感知,时序记忆也留下来了。它的实时性专注底层感知,不需要人工下指令触发,自己就能一直跑。
VLX-Seek是精准定位层:
市面上很多通用视觉大模型,只能告诉你画面里有什么,但没法告诉你那个东西具体在哪、有几个。VLX-Seek换了个思路,用区域指代机制,直接输出毫米级的精准空间锚点。这才是实操中真正需要的能力。
VLX-Go是行动输出:
传统视觉模型解析完画面,生成一堆文字指令,但硬件没法直接用。VLX-Go更进一步,直接输出设备能调用的导航航点,让机器人自主完成移动动作,实时反馈,延迟很低。
视频流持续灌进来,Flow负责“看懂”,Seek负责“找对”,Go负责“动起来”。这三块拼图拼在一起,才是完整的物理世界AI。
基准测试里,VLX用三组数据印证了一个趋势:参数规模和物理世界的真实表现,正在脱钩。
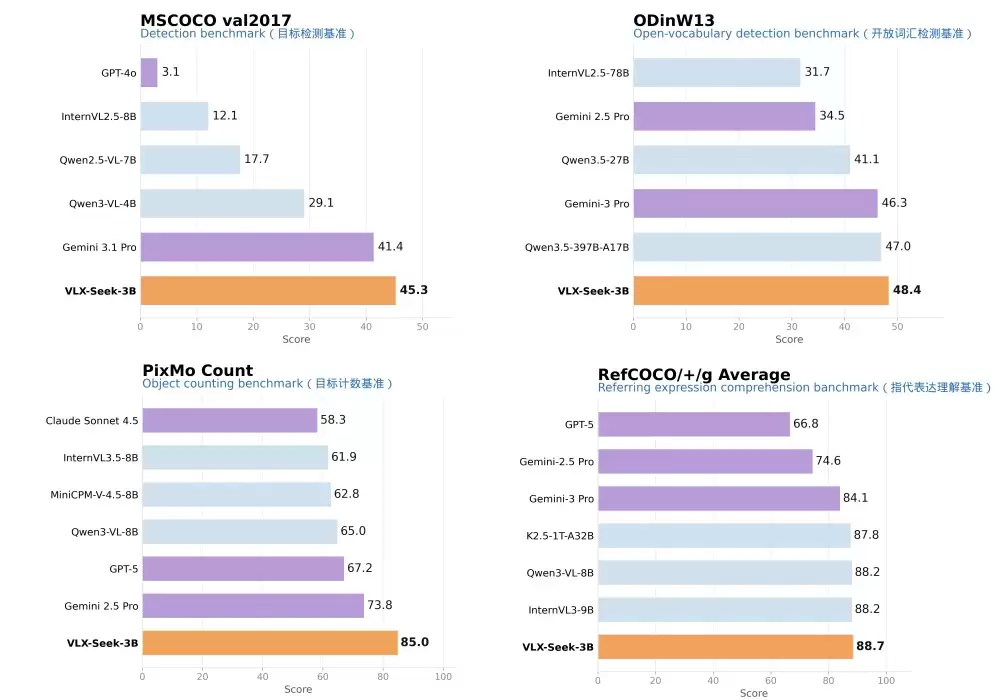
Seek-3B在目标检测基准MSCOCO val2017、复杂语义基准RefCOCO、开放词汇检测基准ODinW13,还有目标计数基准PixMo Count上,都大幅超过了Gemini 3.1 Pro和GPT-5这些旗舰大模型。用3B这么小的参数,达到了旗舰级的精度。
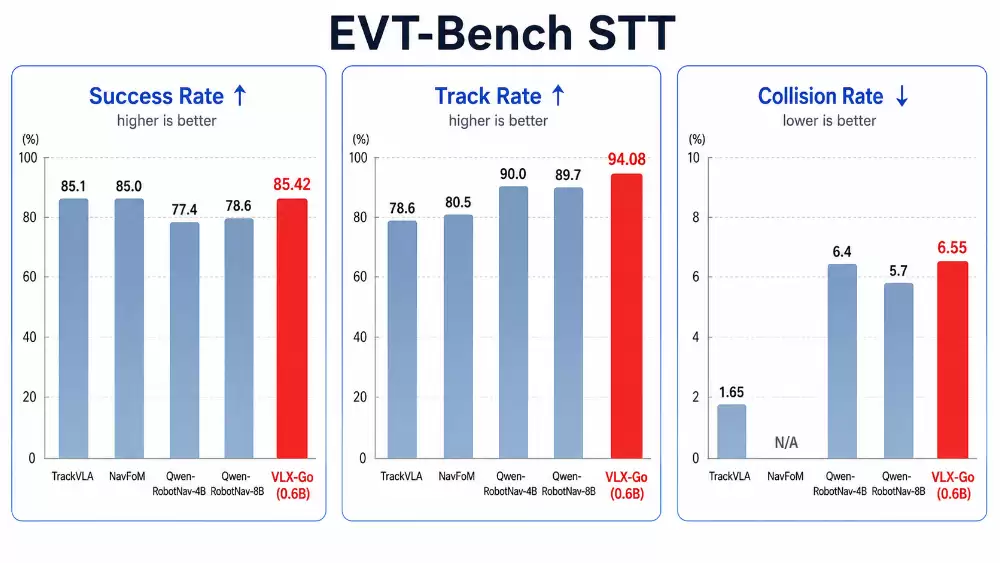
在机器人导航和跟踪任务上,Go(0.6B)用极小的参数实现了85.42%的高成功率,超越了参数量大它13倍的Qwen-RobotNa v-8B;同时以94.08%的跟踪率显著领先所有对比模型。这个数据说明,在动态目标跟随方面,它的视觉-运动协同能力非常强,也充分证明了专门针对端侧物理场景做架构设计,这条路是走得通的。
延迟方面,端侧推理只花0.1秒,云端推理通常要5秒以上。这50倍的差距,直接划出了系统“可用”和“不可用”的界线。
结果很明确:当模型必须跑在端侧、必须实时响应、必须自己决策时,“大”反而成了累赘。VLX的价值在于用更小的模型在端侧芯片上跑出更好的结果。它证明了“为场景设计模型”这条路,比“把通用模型硬塞进场景”高效得多。
二、给物理世界造一套“视觉中枢”
这么亮眼的成绩,根子在于架构层面的差异。
传统模型处理视觉信息,是“截帧-上传-提问-回答”的循环。拍张照片或者上传视频,问一句,答一句。本质上是离散的、被动的。很多模型现在靠长上下文来处理视频输入,说到底还是“离线看一遍”。
Om AI联汇提出的流式多模态,相当于给设备装了一套持续运转的“视觉中枢”。摄像头采集的视频流像水一样不断流进模型,模型持续接收、理解、记忆,形成不间断的感知流。用户或开发者通过提示词自由定义输出目标,这套中枢就能按需输出文本描述、空间锚点或者行动轨迹。
技术路径上,VLX的流式能力是专门为实时交互场景设计的。系统可以自主持续观察、精准锁定、立刻行动。两者应用场景不同,架构设计自然就分化了。
行业里的通用做法是先训练大参数模型,再通过量化、蒸馏等方法压缩到端侧。Om AI联汇走了另一条路。
据公司技术团队介绍,VLX从设计一开始,就是围绕端侧算力约束来做架构的。Flow采用Linear Attention机制替代标准Attention,保证视频流持续输入时显存不会爆;Seek用区域指代替代坐标生成,精度提高了,计算量还降下来了;Go采用短时航点预测,快速响应周围环境的变化。
三、不再纸上谈兵,Om AI联汇定义物理AI新范式
在这之前,物理AI一直卡在一个尴尬的位置:Demo惊艳,但量产乏力。VLX从一开始就是冲着落地设计的,而且已经大规模落地了:
- 具身智能领域:行业长期有个痛点:不同机器人平台的系统架构、传感器方案、执行机构高度异构,算法从A平台迁移到B平台,适配工作量巨大。VLX大脑具备跨平台能力,已经全面支持云深处、宇树等头部企业的端侧设备,开发者在不同机器人平台上的适配周期大幅缩短。
- 无人机领域:传统巡检靠飞手人工操作,或者飞完把视频带回来后台审核,又慢又费人力。搭载VLX的无人机有了自主视觉导航和精准目标锁定能力,能自己识别违章、避障、规划航线。巡检效率翻了好几倍,响应时间从小时级缩到秒级。
- 可穿戴设备领域:中国有超过1700万视障人士,市面上的辅助工具大多只是语音播报或者简单障碍物提醒,解决不了“我在哪、周围有什么、怎么走过去”这个连贯需求。Om AI联汇Homer平台旗下好马APP已经服务了近10万视障用户,通过AI助视眼镜帮他们安全避障、出行导航、空间寻物。

- 安防摄像头领域:客户不用换硬件,在边缘侧或轻量化网关里接入VLX,摄像头就能升级成24小时自主研判的AI哨兵。原有硬件资产不受影响,不用推倒重来,成本低得多。
- AI PC领域:PC上的端侧AI一直停留在文字对话和简单图像生成,缺乏视觉理解和空间交互能力。VLX已经完成跟苹果、联想、惠普、英伟达四大头部品牌的端侧适配,给PC设备注入了实时视觉理解能力。
- 国产芯片方面:端侧AI的算力部署原来很依赖英伟达这些海外高端芯片,国产芯片受限于算力和生态,很难承载大参数模型。VLX针对算力约束做了专门优化,已经在华 为昇腾、地瓜、RK3588这些国产平台上完成适配。
VLX的行业价值,在于验证了一条不同于数字AI的架构路径。
当行业还在比拼谁能把云端模型压得更小的时候,VLX选择了从端侧算力约束出发设计模型。测试数据说明这条路不需要等算力迭代就能落地,部署成本大幅压缩,实时响应能力提升了数十倍,用国产芯片也能跑得流畅。
与此同时,这套流式多模态路线已经覆盖了具身智能、无人机、可穿戴、安防、AI PC等多个场景。物理AI从“Demo展示”到“量产交付”的拐点,正在显现。而VLX系列模型向开发者开放体验平台,进一步降低了端侧智能应用的研发门槛,给产业链协同创新留下了很大的想象空间。
结语:用流式架构为物理世界重新设计AI
回到开头那个问题:物理世界,到底需要什么样的AI?
Om AI联汇用VLX系列模型给出了答案:用流式架构为物理世界重新设计AI。
这背后是Om AI联汇多年的布局和深耕。从2016年切入生成式对话技术,到2021年押注多模态赛道,再到2022年拿下国内首张多模态大模型测评证书,团队始终走在趋势前面,持续积累底层能力。
放眼整个物理AI赛道,行业从来都不缺愿景、概念和演示Demo。真正稀缺的,是能适配真实场景、稳定运行、能规模化落地的成熟系统。更重要的是,它得被百万级设备验证过。
VLX为物理AI的端侧化路径,提供了一个可参考的样本。