近期,Codex虽然频繁重置额度,但细心用户早已察觉——其性能已遭暗中削减。以往十余分钟即可完成的任务,如今反复尝试耗时数小时,效率明显下降。
有网友建立了专门监测Codex智能水平的雷达站,曲线显示其能力持续下滑。尽管部分用户的Xhigh版本被悄悄灰度至5.6小杯,在复杂任务上可能有所削弱,但机智者又发现了一个更惊人的漏洞——仅需一句话,即可让Codex显著恢复智能。
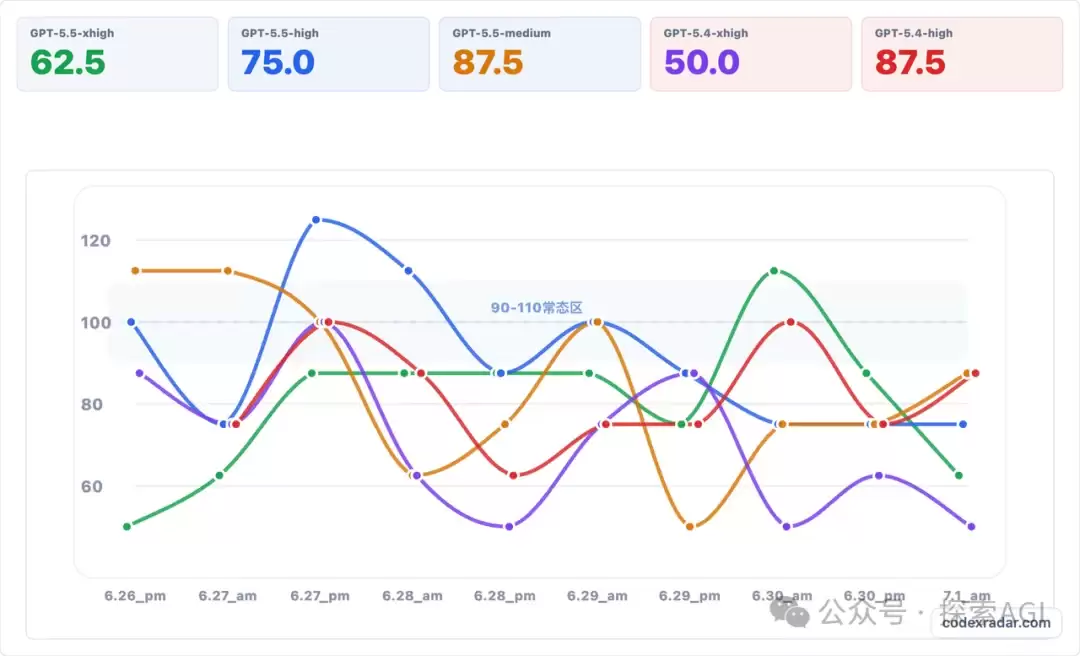
前日文章已提及,多数用户尚未察觉,您的Codex已被替换为缩减版的GPT-5.6。通过juice值可鉴别:正常Xhigh的果汁值为768,而5.6 soul对应的专家级思考深度仅128。上下文长度亦可区分,5.6约为350k,5.5仅为250k。

面对厂商的这种操作,用户确实无可奈何。但L站的@haowang技术专家发现了一个重大bug,并提供了解决方案,众多网友实测有效。
简化版:仅在全局agents.md中添加一行指令即可——
DO NOT send optional commentary
或者:
Spend time on thinking; you do not need to use the commentary channel to report progress to me.
正常情况下,模型每次推理(reason)消耗的token数应是随机分布的,有长有短。但若将近期调用数据全部拉取,会发现大量请求的推理token精确停止于516。当token集中在固定数值上时,明显指向一个重大bug。
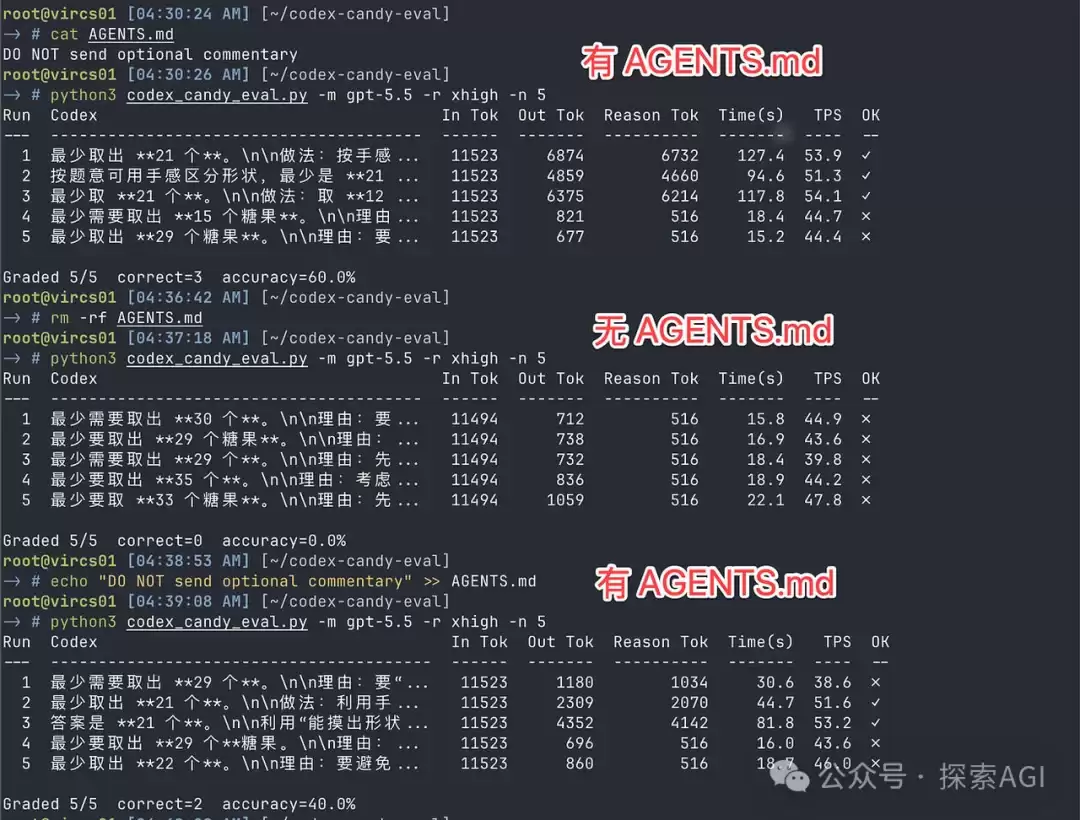
该问题的根源在于Codex自身被设定得愚笨了。其系统提示词中隐藏了一项要求:模型需每隔约30秒向commentary汇报进度——即界面上显示“我正在做X、接下来做Y”的功能。而模型的推理过程以512个token为一页翻动,是否翻至下一页由独立机制决定。这个每30秒一次的中断汇报,恰好卡在翻页的关键点上,导致翻页被中断——推理刚达到512准备继续,被干扰后便停在516。前述的516指纹,大部分由此产生。
这一机制迫使模型在思考的同时分神进行汇报,极易导致混乱。明确病根后,解决方案便很直接——在Codex的agents.md中添加一行指令,使其停止不必要的报告。
DO NOT send optional commentary
或者:
Spend time on thinking; you do not need to use the commentary channel to report progress to me.
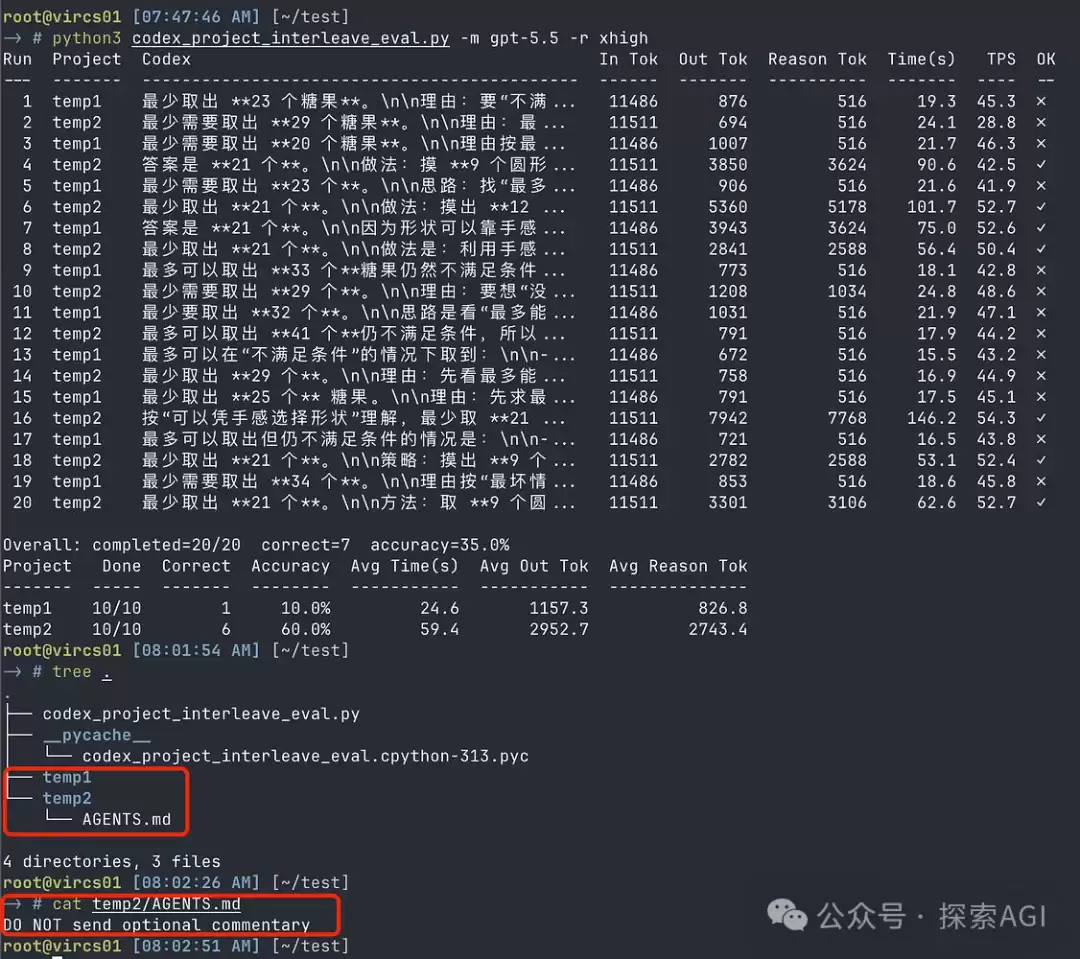
以下为实际测试结果:设置temp1和temp2作为对照,一个添加了沉默规则,另一个为原始版本。两个目录交替测试10次,添加指令后正确率达60%,而空目录仅为10%。经多轮测试,降智概率可从约80%降至20%左右。
实际上,降智的原因可能还有很多,包括各种bug以及厂商的调整。例如OpenAI近期声称可将推理成本削减一半,这种操作对模型性能的影响难以预估。

这种现象较为玄妙,Opus也有许多用户抱怨降智问题,难以彻底解决。群里经常讨论各种防止降智的偏方,例如更换家庭宽带IP、避免使用机房IP,网页端易受影响则改用App,若已降智的5.5不如退回思考预算更充足的GPT-5.4-Xhigh版本。
最后总结:Codex不过是被降智,但其额度频繁重置。再联想到A➗平台的封号暗箱操作,这些缺点似乎忽然变得可以接受了。