先提出一个值得思考的问题:如果我们将支持向量机(SVM)的核心思路迁移到神经网络中,会碰撞出怎样的火花?这并非凭空想象,而是源自一篇蒙特利尔大学论文的启发——该论文作者在备考博士资格考试时复习SVM,突然灵光一闪,随后发现SVM、生成对抗网络(GAN)与Wasserstein距离之间竟隐藏着一条隐秘的关联线索。
SVM大家都不陌生:作为一种监督学习模型,它能够在二维或高维空间里为数据点绘制一条分界线,使正负样本尽可能远地分隔开。当数据线性可分时,它的操作非常简洁;遇到非线性数据时,则借助核技巧将数据映射到更高维空间再划分。这套逻辑干净利落,但它与神经网络之间究竟存在什么联系?

这篇论文将“最大间隔分类器”(MMC)的概念扩展到了任意范数和非线性函数上。换句话说,SVM只是MMC的一个特例——它能够最大化最小间隔,但MMC的定义范围更广。研究人员发现,MMC可以重新表述为“积分概率度量”(IPM)的形式,或者等价于某种带梯度范数惩罚的分类器。这一发现直接将梯度惩罚GAN的判别器拉到了同一框架下。
具体来看:Wasserstein GAN、标准GAN、最小二乘GAN、带梯度惩罚的Hinge GAN,它们的判别器本质上都属于MMC。这个发现解释了为什么“最大化间隔”在GAN中如此重要——它直接关联着生成图像的质量。进一步,论文假设采用L∞范数惩罚配合Hinge损失的效果会优于L2范数惩罚,并通过实验验证了这一假设。此外,还为Relativistic paired (Rp)和Relativistic average (Ra) GAN分别导出了各自的间隔定义。
整篇文章的结构清晰明了:第二章回顾了SVM和GAN;第三章定义了MMC;第四章阐述了MMC与GAN之间的桥梁——4.1节说明强制1-Lipschitz等价于假设梯度有界,这意味着Wasserstein距离可以用MMC公式近似;4.2节讨论了在GAN中使用MMC的好处;4.3节假设L1范数间隔能够构造更鲁棒的分类器;4.4节推导了两种Relativistic GAN的间隔。第五章通过实验支撑了所有假设。
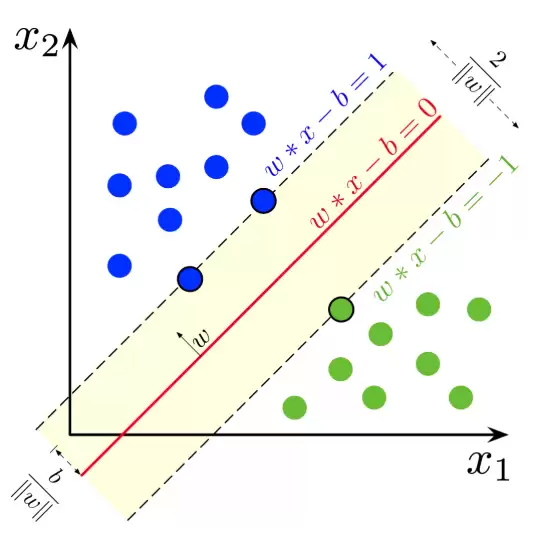
这里需要先厘清一个容易混淆的概念:到底什么是“间隔”?
通常有两种定义:(1)单个样本到决策边界的最短距离;(2)整个数据集中离边界最近的样本到边界的距离。SVM文献中常提到“函数间隔”和“几何间隔”,但它们其实都不够标准。更直观的理解方式是:将(1)称为“样本间隔”,将(2)称为“数据集最小间隔”。为避免混淆,论文把前者直接称为“间隔”(margin),后者称为“最小间隔”(minimum margin)。
Hard-SVM解决的是最大化最小间隔问题,而Soft-SVM换了一种更简洁的方式——最大化期望的soft-margin(即最小化期望Hinge损失)。Hinge损失非常巧妙:它让远离边界的样本不再过度干扰,否则会破坏Hard-SVM的效果。从这个角度出发,最大化期望间隔(而非最小间隔)依然能够得到最大间隔分类器,只不过如果不加入Hinge损失,分类器会被远处的点带偏。因此,最大化期望间隔,本质上是让所有数据点到决策边界的平均距离达到最大——这正是MMC的核心。
为了让框架足够通用,研究者设计了一套方法,可以从MMC推导出损失函数。他们发现,这个框架会自动产生带梯度惩罚的间隔目标函数(形式为F(yf(x)))。于是标准GAN、最小二乘GAN、WGAN、HingeGAN-GP全都成为了MMC——当它们使用L2梯度范数惩罚时,都是在最大化期望L2范数间隔。
更进一步,大多数使用Lipschitz-1判别器的GAN(比如谱归一化HingeGAN、WGAN、WGAN-GP)也都可以表示为MMC,因为假设1-Lipschitz本质上就是在假设梯度有界(这本身也是一种梯度惩罚形式)。这意味着,像BigGAN、StyleGAN这类当前最成功的GAN,其判别器都被视为MMC。过去大家认为Lipschitz-1判别器是搞好GAN的关键,但现在看来,真正起作用的可能是一个既能最大化间隔又具备“相对判别”机制的判别器。MMC判别器能为伪生成样本提供更强的梯度信号,这就是它的魔力所在。
看到这里你可能会问:不同间隔之间是否存在优劣之分?如果有,我们能否据此做出更好的GAN?答案都是肯定的。从统计学常识可知,最小化L1范数比L2范数对异常值更稳健。所以研究者推测:L1范数间隔能构造出更鲁棒的分类器,由此生成的GAN也可能比L2范数间隔更强。关键点在于:L1范数间隔对应L∞梯度范数惩罚,而L2对应L2梯度范数惩罚。实验果然证明,L∞梯度范数惩罚(因为采用了L1间隔)得到的GAN效果更优。
此外,实验还显示HingeGAN-GP通常优于WGAN-GP——这也合情合理,因为Hinge损失对远处的异常值不敏感。而且只惩罚梯度范数大于1的部分(而不是像WGAN-GP那样强制所有梯度范数都接近1)效果更好。尽管是理论研究,但这些发现对实际改进GAN具有重要启发意义。
最后,这套框架还能为Relativistic paired和Relativistic average GAN正确定义决策边界和间隔。大家一直困惑为什么RpGAN不如RaGAN,论文对此给出了清晰解释。使用L1范数间隔只是一个开端——这个框架还能通过设计更鲁棒的间隔,开发出更好的GAN(例如更优的梯度惩罚或谱归一化)。更重要的是,它第一次提供了明确的理论依据,说明为什么梯度惩罚或1-Lipschitz对不估计Wasserstein距离的GAN也有效。更多细节可以查阅原论文。