1. 特征提取 vs 特征选择
在机器学习领域提到“降维”时,通常会涉及两个紧密相关的概念:特征提取与特征选择。它们都能有效应对“维度灾难”——即当特征数量过多而样本稀疏时,模型容易过拟合或学习到大量噪声。然而,这两者的实现方式有本质区别,切勿混淆。
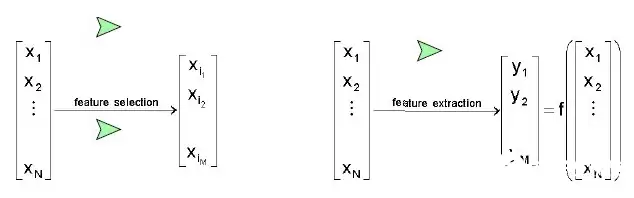
特征提取(Feature Extraction),通俗来说就是“创造新特征”。它通过对原始特征进行组合、变换或映射,生成一个全新的特征集合。这些新特征不再是你最初看到的那些变量,而是由它们经过某种运算得到的产物。例如,利用主成分分析(PCA)将原始的20维特征压缩成5个主成分,每个主成分都是原始变量的线性组合,保留了原始数据中的大部分信息。
特征选择(Feature Selection),则更像是“挑选精华”。它直接从原始特征中选出一个子集,只保留那些信息量最大、对分类或回归任务最有价值的特征。被选出的每个特征仍然是原始特征中的一员,没有经过任何数学变换。常见的方法包括卡方检验、互信息、递归特征消除(RFE)等。
简单来说:特征提取是“组合创新”,特征选择是“筛选保留”。两者目标都是降低维度,但路径截然不同。
2. PCA vs LDA
介绍完降维的两条主要路径后,我们来聚焦特征提取领域中最经典的两个算法:主成分分析(PCA)和线性判别分析(LDA)。它们都属于线性方法,但出发点与应用场景差异显著。
特征提取可以划分为两大任务类型:
(1)信号表示(Signal Representation)
这类任务的核心在于:在低维空间中尽可能准确地表示原始样本,使信息损失降到最低。换句话说,你希望降维后的数据能够较好地“还原”出原始数据。典型代表就是PCA——它找到的投影方向是协方差矩阵的特征向量,保证投影后数据的方差最大,从而保留最多信息。
(2)信号分类(Signal Classification)
这类任务的目标并非还原,而是“区分不同类别”。它要求降维后的新特征能够帮助分类器更容易地将不同类别的样本分开。线性方法中的代表是LDA——它寻找一个投影变换W,使得投影后不同类别的均值之差尽可能大(类间距离大),同时同一类别内部的方差尽可能小(类内距离小)。换言之,LDA旨在最大化类间散度与类内散度的比值。
因此,PCA与LDA的根本区别在于目标导向:PCA追求“信息保留”,LDA追求“类别可分”。这一差异也直接决定了它们的数学原理和适用场景。如果你的任务是无监督的(没有标签信息),请选择PCA;如果你有分类标签,且希望提升分类准确率,LDA通常更为合适。当然,非线性情况不在本文讨论范围内。