大模型的热潮席卷而来,一个关键的技术组件——向量数据库——逐渐浮出水面。它解决了海量向量的存储和检索问题,但一个更底层的问题随之浮现:这些向量,究竟是怎么来的?答案指向一个不算新、但眼下空前重要的技术——Embedding。
Embedding这个概念的起源,可以追溯到Word Embedding,经过多年演进,早已今非昔比。从横向看,它从单纯的Word Embedding,拓展出Item Embedding、Entity Embedding、Graph Embedding、Position Embedding、Segment Embedding等;从纵向看,静态的Word Embedding又进化出ELMo、BERT、GPT等动态预训练模型。这意味着Embedding不再是固定的,而是能通过微调学到新语境下的语义,高效支撑分类、问答、摘要、阅读理解等下游任务,很多任务的完成效率甚至超过了人工平均水平。
Embedding 概述
在机器学习、深度学习领域,嵌入(Embedding)技术近年发展迅猛、遍地开花,已成为核心基础能力。
简单来说,Embedding就是用向量来表示一个物体。这个物体可以是一个单词、一句话、一个序列、一件商品、一个动作、一本书、一部电影……几乎覆盖了机器学习和深度学习的大部分核心对象。如何有效表示和学习这些对象,自然成了关键。特别是word2vec这类Word Embedding的广泛应用,更是把这项技术从最初的NLP领域,快速延伸到了传统机器学习、搜索排序、推荐、知识图谱等方向——Word Embedding映照出了Item Embedding、Graph Embedding、Categorical Variables Embedding等众多分支。
Embedding自身也在不断进化:从表现单一的静态形式,走向更丰富的动态形式。静态的Word Embedding延伸出了ELMo、Transformer、GPT、BERT、XLNet、ALBERT等动态预训练模型,这条路走得很快,也很深远,持续推动着NLP领域的发展。
总体来说,Embedding能做的事情包含但不限于:
- Word Embedding
- Item Embedding
- 用Embedding处理分类特征
- Graph Embedding
- Contextual Word Embedding
- 用Word Embedding实现中文自动摘要
篇幅有限,本文先挑与NLP和知识库问答相关的内容来展开讨论。
处理序列问题的一般步骤
序列问题无处不在——自然语言处理、网页浏览、时间序列……都离不开它。如何处理这些序列,挖掘其中隐含的规律和逻辑,是必须解决的核心问题。
以NLP为例。拿到一篇长文章或新闻材料,要求用NLP方法提炼摘要,你会怎么做?要考虑哪些要素?第一步做什么?
不管中文还是英文,首先需要做一些必要的清理:去掉特殊符号、格式转换、过滤停用词,接着分词、索引化,再通过模型或算法把单词、词等标识符向量化,最后输出给下游任务。
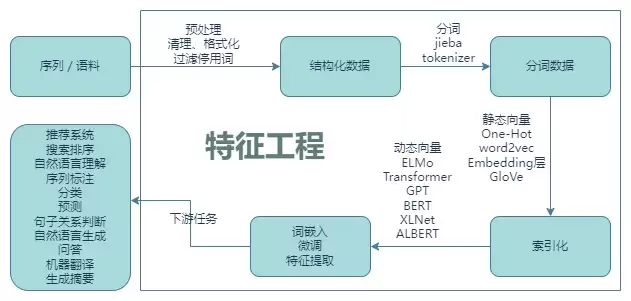
图中可以看出,词嵌入或预训练模型是整个流程的关键点。它们的质量直接决定了下游任务的效果。这个环节涉及的算法、模型很多,近年来也取得了重要突破——word2vec、Transformer、BERT、ALBERT等,屡屡刷新NLP、语音识别、推荐、搜索排序等任务的性能记录。
Word Embedding
机器不认识单词,这是一个大问题。最早的思路是用整数来表示各个标识符(token),简单,但不够灵活。
后来改成独热编码(One-hot Encoding),方法方便,但非常稀疏、属于硬编码,而且无法承载更多信息。
于是研究者转向用数值向量或标识符嵌入(Token Embedding)来表示,这就是通常说的词嵌入(Word Embedding),也叫分布式表示(Distributed Representation)。
这三种方式对比,可以直接看下面这张图(我就不画了,直接引用一张)。
独热编码是稀疏、高维的硬编码。如果语料有一万个不同的词,每个词就得用一万维的独热编码表示。而用向量或词嵌入表示,向量是低维、密集的,且这些向量值都是通过学习得来的,并非硬性给定,具备更强的表达能力。
Word Embedding 的学习方法
主要分两种:
- 利用平台的 Embedding 层学习 Word Embedding:在完成任务的同时学习词嵌入。例如把Embedding作为第一层,先随机初始化词向量,然后利用PyTorch、TensorFlow等平台不断学习(正向传播+反向传播),最终得到需要的词向量。
- 使用预训练模型:现在有不少在较大语料上预训练好的词嵌入或预训练模型,可以直接复用。在没有足够质量的自有语料之前,使用预训练模型的效果往往比自己训练的更好,能有效节省时间和资源。
Item Embedding
Embedding是一种优秀的思想,不只限于NLP领域,还能应用到其他很多场景。
微软团队写过一篇论文《Item2Vec:Neural Item Embedding for Collaborative Filtering》,实用性极强,极大拓展了word2vec的应用范围,把NLP领域的技术直接移植到了推荐、广告、搜索排序等任何可以生成序列的领域,成为协同过滤的重要工具。
处理分类特征
传统机器学习里,输入数据常包含分类特征,这些特征的处理是特征工程的重要环节。分类特征也叫离散特征,数据类型通常是object。但大多数机器学习模型只能处理数值型数据,因此需要把分类数据转换为数值数据。
Categorical特征可以分为有序(Ordinal)和无序(Nominal)两类。这两类数据可以通过不同方法转为数字。对于Nominal类型,常用独热编码。但遇到大规模数据时——比如某一特征有几百、几千甚至更多类别——独热编码会使特征维度急剧膨胀,产生庞大的特征矩阵。而且独热编码只能把类别数据转为0或1,无法准确表达类别之间的潜在规则或分布特性。举个例子:一个地址特征包含北京、上海、杭州、纽约、华盛顿、洛杉矶、东京、大阪等地,这些地理位置之间存在空间关系——北京、上海、杭州较近,上海与纽约相距遥远——但独热编码根本反映不了这些地理分布的规律,造成信息丢失。
近年来,神经网络和深度学习在计算机视觉、NLP、时间序列预测等领域的应用日益普及。在深度学习中,Embedding作为一种将离散变量转化为连续向量的技术,极大促进了传统机器学习和神经网络的发展。目前,Embedding技术主要有两种应用:一是NLP中的Word Embedding,二是用于类别数据的Entity Embedding。简单来说,Embedding就是用低维向量表示一个对象——一个词、一个类别特征(商品、电影、物品等)、或时间序列特征。通过学习,Embedding向量能更精确地捕捉特征的内在含义,从而使几何上距离较近的向量所代表的对象具有相似的语义,有助于提升模型精度。
Graph Embedding
前面提到的Word Embedding和Item Embedding,都依赖序列特征。但事实上,可以应用Embedding的领域远不止这些。有些场景乍看之下与序列无关,经过适当调整和变化后,同样可以运用这些技术。
Graph Embedding与Word Embedding类似,目标是用低维、密集、实值的向量来表示网络中的节点。如今,Graph Embedding在推荐系统、搜索排序、广告投放等多个领域广受欢迎,实际表现也很亮眼,成为图数据表示学习的重要方法。
图(Graph)是一种“二维”关系表达,而序列(Sequence)则体现一种“一维”关系。因此,将图转换为Graph Embedding时,通常需要先借助特定算法把图结构转化为序列形式,再通过相关模型将序列进一步转化为Embedding向量。
常用方法包括(篇幅所限,这里不展开):
- DeepWalk
- LINE
- node2vec
举个推荐系统中的应用实例。近年来,众多研究者尝试将知识图谱融入推荐系统,以应对稀疏性与冷启动难题。目前,将知识图谱特征学习应用于推荐系统的方法大致有三种:依次学习(独立学习知识图谱与推荐模型)、联合学习(同时优化知识图谱与推荐系统)、交替学习(交替迭代优化知识图谱与推荐模型)。每种方法都有其适用场景和优劣。
Contextual Word Embedding
之前说的Word Embedding,因为word2vec的流行而广受关注。相比离散的独热编码,它优势明显:降低了数据维度,能捕捉语义空间中的线性关系(比如“国王 - 王后 ≈ 男 - 女”)。因此,word2vec及其类似方法几乎成了所有深度学习模型的标配。但这种表示方法也有局限性——它基于语料库生成固定字典,每个单词对应一个固定长度的向量。遇到一词多义的情况,就很难准确区分不同语义,导致歧义问题。
怎么解决一词多义?
word2vec生成的词嵌入是固定不变的,所以被称为静态词嵌入。它不考虑上下文环境,无论单词出现在什么语境,向量表示都保持一致。如果上下文有影响,就不能依赖静态词嵌入,而应采用动态词嵌入方法,或者结合预训练模型与微调来处理。比如ELMo、GPT、GPT-2、BERT、ERNIE、XLNet、ALBERT等,都属于动态词嵌入的范畴。这些方法在上下文中动态生成词向量,极大提升了NLP领域的性能,而且至今仍在快速演进中,成为当前NLP任务的主流选择。
小结
Embedding几乎无处不在。无论是传统机器学习、推荐系统,还是深度学习中的NLP,甚至是图像处理,都绕不开Embedding技术。从某种意义上讲,把Embedding做好了,整个项目的关键难题就攻克了一半。掌握好Embedding的原理与应用,将对AI项目的成功起到决定性作用。