一提到RAG系统,很多人下意识会想:检索的文档越多、给模型的上下文越丰富,生成的答案不就越准吗?这个逻辑听上去天衣无缝,但实际情况可能要复杂得多。最近的一系列实验揭示了一个有些反直觉的现象:在某些情况下,给得越多,效果可能反而越差。这个关于“Top N”参数的微妙平衡,值得我们重新审视。
RAG 系统的背景与挑战
在自然语言处理领域,以GPT、BERT等为代表的大语言模型已经展现出令人惊叹的文本生成与理解能力。但光环之下,其固有的软肋也日益明显。
最突出的问题有三个:一是知识固化。模型训练完那一刻,其知识库就基本“冻结”了,难以吸收实时涌现的新信息,导致回答可能过时。二是所谓的“幻觉”问题——模型有时会自信地编造出看似合理、实则错误的回答。三是在垂直、专业的深水区,模型往往因缺乏足够深度的训练数据而显得力不从心。
正是为了补上这些短板,检索增强生成系统应运而生。它的核心思路很清晰:为模型配备一个动态的“外部知识库”检索器,让模型在回答时能够即时查询、引用最新、最相关的文档片段。这种模式在企业内部知识库问答、智能客服等场景中应用广泛,前景广阔。
然而,一个现实是,虽然RAG的应用铺得很快,但关于如何最佳配置它的研究却相对滞后。特别是几个关键旋钮——比如到底该检索多少篇文档(Top N),上下文多大合适,不同组件的选择有何影响——这些细节的拿捏,往往决定了系统最终是“神助攻”还是“猪队友”。
试验结果:更多不等于更好
一个典型的RAG系统由两大核心构成:负责从海量知识库中“大海捞针”的检索器,和基于检索结果“组织语言”的生成器。系统的整体表现,就取决于这两者以及它们之间传递的“上下文”质量。
实验首先聚焦于上下文数量的影响。结果很有意思:随着提供给生成器的文档片段数量增加,系统性能起初确实稳步提升,仿佛在验证“多多益善”的假设。但转折点出现在片段数量达到10到15个左右时,性能曲线开始走平,甚至在部分任务中间出现下滑。这显然是一个信号:过量的信息非但不是养分,反而可能成为干扰生成器专注思考的“噪音”,导致信息过载。
黄金片段测试:理想条件下的上限
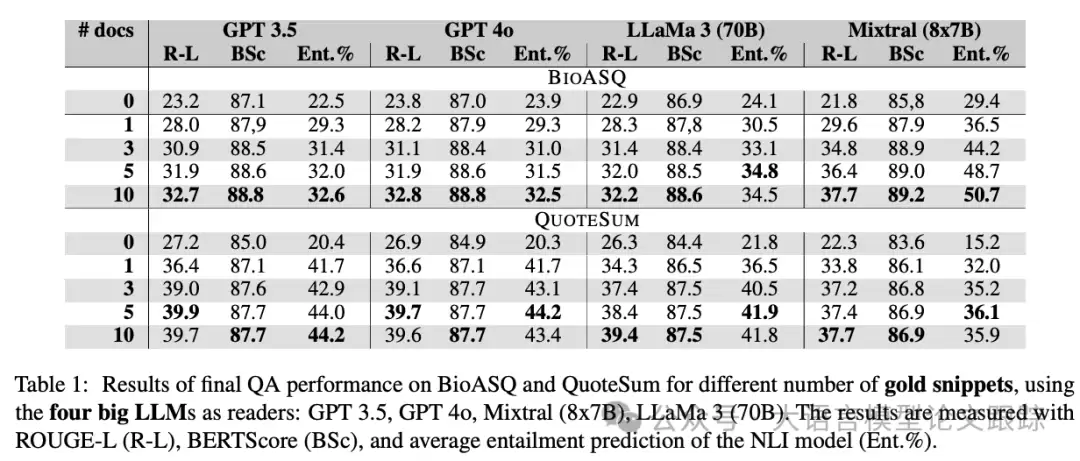
上图展示了GPT-3.5、GPT-4o、Llama 3 70B、Mixtral等几个主流大模型,在直接使用“黄金答案”片段时的表现。这个测试可以看作是在理想检索条件下的性能上限探究。
所有模型都呈现出高度一致的模式:从零样本(不提供任何上下文)的起点开始,仅仅加入一个相关片段,性能就能获得显著跃升。之后,随着片段数量的增加,在多个评估指标上,模型性能都呈现出稳步且持续的改善。这说明在信息绝对精准的前提下,更多的上下文确实能更好地支撑模型进行推理和生成。
封闭式测试:小型知识库的验证
接下来,实验转入更贴近实际但依然受控的“封闭式”环境——使用一个包含八千篇生物医学文献的小型知识库进行检索。
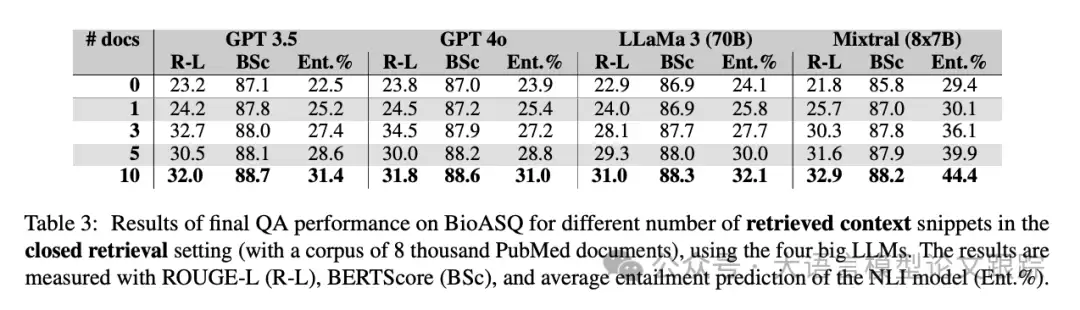
如上表结果所示,与使用黄金片段相比,模型性能出现了预期中的下降。毕竟,检索器可能无法每次都命中最佳答案。但一个清晰的趋势仍然存在:随着Top K(即检索并返回的片段数量)的增加,性能总体上仍在逐步提升。特别是在Top-10的设置下,效果提升较为明显。这背后的逻辑很直观:检索的候选池越大,命中那篇关键“黄金证据”的概率自然就越高。
开放式测试:真实世界的挑战
最严峻的考验来自“开放式”测试。实验将知识库扩大到约1000万篇文献,试图模拟真实、复杂的应用环境。此测试有两个主要目的:一是观察在“大海捞针”的开放环境下,性能与受控的封闭测试差距有多大;二是比较不同检索技术(如关键词匹配的BM25与语义搜索)的表现差异。
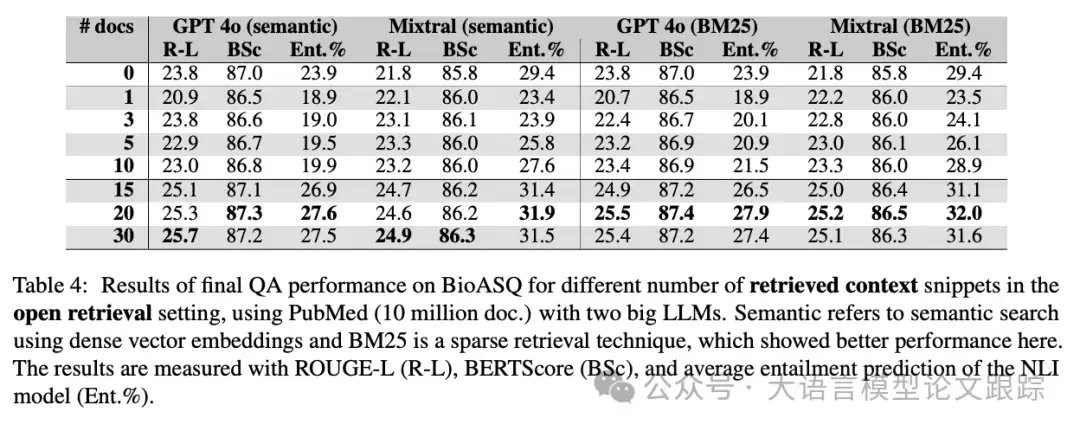
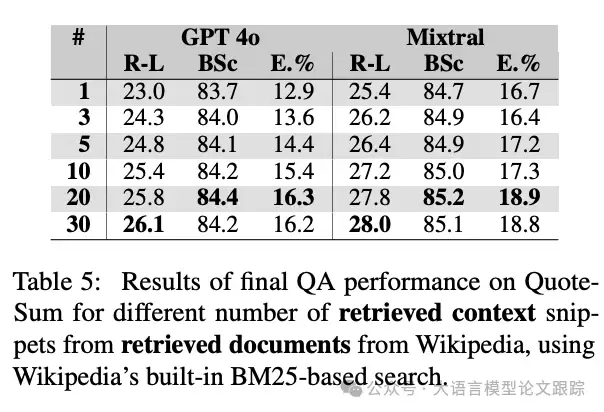
结果如上表所示,不出所料,开放式检索是所有设置中挑战性最高的,平均得分最低。一个值得注意的发现是,基于关键词匹配的经典算法BM25,其最终表现竟然略优于更“智能”的语义搜索。这在某种程度上碘伏了人们对于“语义理解一定更优”的固有认知。
核心发现与深度分析
检索技术:精度优于广度?
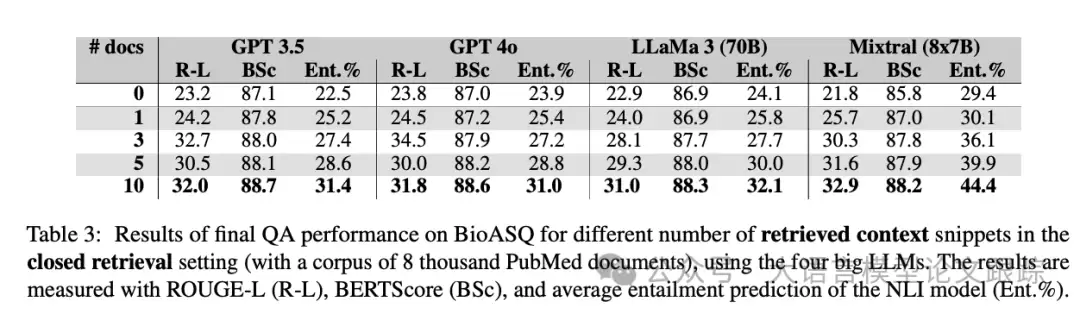
上表的数据清晰表明,在本次实验的生物医学问答背景下,BM25的整体性能更具优势。原因在于,BM25本质上是基于关键词匹配的算法,它优化的是检索结果的“精确度”——确保返回的文档高度聚焦于查询中的核心概念。相比之下,语义搜索虽然致力于理解深层含义,追求更高的“召回率”(尽可能不遗漏相关文档),但可能在精确度上有所牺牲。
对于生物医学这类对准确性要求极高的领域,确保返回的“每一篇”文档都高度相关,远比返回一堆可能相关但夹杂噪音的文档来得重要。精准命中的几篇高质量文档,往往比大量模糊相关的文档更能帮助模型生成稳健、正确的答案。这意味着,在某些严肃的应用场景中,“少而精”的检索策略可能比“大而全”更为有效。
这里简单解释一下评估指标:ROUGE-L关注生成答案与标准答案在字面上的最长匹配序列,侧重于“召回”;BERTScore则借助预训练模型从语义层面衡量相似度;而Ent.%是基于自然语言推理模型,判断生成答案是否在逻辑上“蕴含”了标准答案的信息,对答案的准确性与完整性要求更高。
内部知识与外部知识的冲突
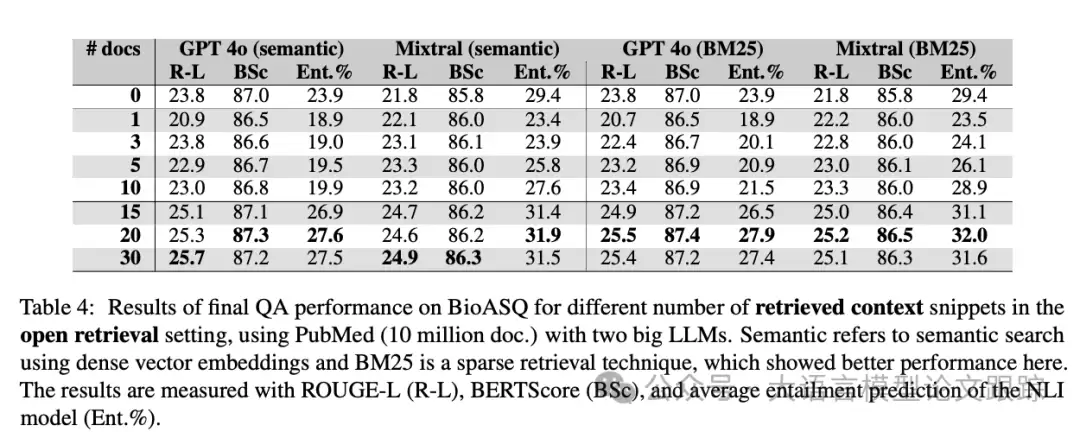
实验中观察到一个非常有趣的现象:在开放式检索设置下,像GPT、Mixtral这样的模型,其“零样本”答案(即不提供任何检索上下文,仅凭模型自身知识回答)的得分,有时竟高于提供了多达10个上下文片段后的RAG答案。
这该如何解释?一个合理的推测是:检索器虽然找到了语义上看似相关的片段,但这些片段可能并未包含回答问题所需的全部关键信息,甚至可能不够精准。此时,如果强行要求模型“仅依据提供的片段作答”,就束缚了它的手脚。
而在零样本情况下,模型调用的是其预训练得来的、经过海量数据洗礼的“内部知识”。这份内部知识库虽然可能不够新、不够专,但在整体结构和逻辑上更为完整。因此,当外部检索质量不佳时,模型自身的见识反而可能更靠谱。

上表中的第一个例子就很典型:Mixtral凭借内部知识生成的答案提到了“纯化”和“IgG”,这与标准答案一致;而基于检索到的Top-3片段生成的答案却是不完整的。瓶颈往往出在检索环节——对于BioASQ中那些复杂的专业问题,检索到的片段有时根本文不对题。
这揭示了RAG系统一个深层次的、已知的挑战:当模型强大的内部知识与外部提供的、可能有噪声的上下文知识发生冲突时,模型应该如何抉择?这不仅是一个工程优化问题,也是一个值得深入研究的学术方向。
上下文饱和:性能存在天花板
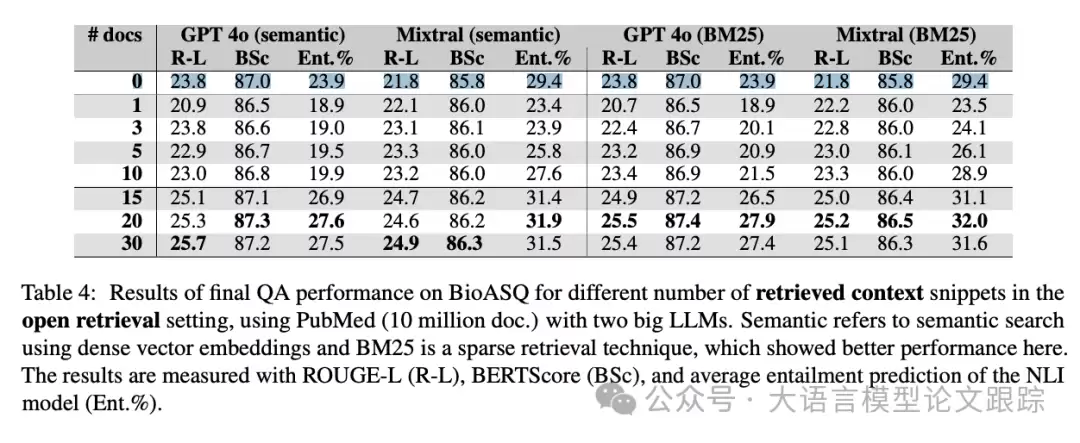
实验的另一个关键发现是,性能提升存在明显的“天花板效应”。随着上下文片段数量不断累加,增加到20个左右时,性能增长几乎停滞;当增加到30个时,部分指标甚至出现了轻微下滑。
这证实了“过犹不及”。一旦超过某个饱和点,继续堆叠上下文就像在会议上让过多的人同时发言——只会带来更多的噪音和混淆,让模型难以抓住重点。学术上也有类似发现,即在过长的提示中,处于中间位置的信息容易被模型“忽视”,也就是所谓的“迷失在中间”现象。
所以说,在配置RAG系统时,盲目调大Top N参数并非良策。找到一个既能提供足够支撑、又不会造成信息过载的“甜蜜点”,才是平衡艺术的关键。这个点根据具体任务、模型能力和检索质量的不同而动态变化,需要精心调试与验证。