当使用 DeepSeek R1 满血版时频繁遇到“访问受限”提示——不仅免费网页端受限,就连付费 API 的 deepseek-reasoner 模式,在相同的高并发压力下也常常响应卡顿。OpenAI 虽然开放了免注册的 Chatbox 入口,但依然存在地区访问限制。
这种“想用却用不了”的尴尬局面,让本地化部署成为越来越多用户的实际选择。目前主流部署方式包括 Ollama 和 vLLM 两种。本文将重点介绍 Ollama 下蒸馏模型(Distilled models)的部署流程,并评估其在单细胞注释任务中的实际效果。
01
背景
由于访问量过大,满血版 DeepSeek R1(深度思考模式)的使用频繁受限;付费 API 的 deepseek-reasoner 模式同样面临限制;OpenAI 开放了免注册的 Chatbox,但仍有地区使用限制。本地化部署大模型的方法主要有 Ollama 和 vLLM 等。本文主要介绍利用 Ollama 部署蒸馏模型(Distilled models)的具体操作与表现。
02
目的
评估本地化部署的 LLMs 在单细胞注释分析中的实际表现,为科研与工程应用提供参考。
03
方法
1. 下载 Ollama。直接从官网获取安装包,过程非常便捷。
ollama run deepseek-r1:7b
2. 加载模型。为适配不同用户的硬件配置,Ollama 提供了多种尺寸的蒸馏模型。其中 7b 蒸馏小模型对多数个人电脑(16GB 内存)较为友好。这里的“7b”代表 70 亿参数量。模型文件的大小主要受参数量和精度(precision)影响:参数量和精度越高,对硬件性能的要求也越高。为便于对比测试,本次本地化部署采用参数量 7b~9b、精度 4bit 的蒸馏模型。
3. 测试本地化蒸馏模型在单细胞注释中的效果。
# 调用本地模型之前运行: ollama serve
git clone https://github.com/Zhihao-Huang/scPioneer cd scPioneer Rscript ./result/annotation_locally_test.R
04
结果
基于 API 的满血版大模型结果如下:本地化蒸馏模型结果如下:
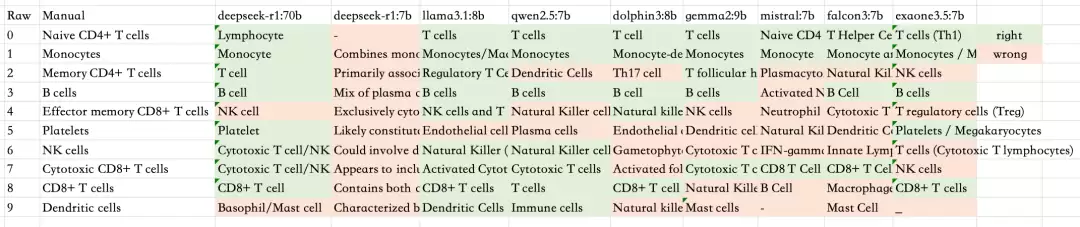
05
总结
1. 本地化部署的 DeepSeek R1 蒸馏版准确率明显低于满血版 DeepSeek。而通过 API 调用的 DeepSeek V3 与 DeepSeek R1 表现较为出色。
2. 在本地化模型中,llama3.1:8b 取得了最高的准确率;而 deepseek-r1 的两个蒸馏版本(70b 和 7b)表现均不理想。
3. 参数量 7b + 4bit 的本地化模型大约需要 5GB 内存。本次测试所用 CPU 型号为 Xeon(R) Gold 6238R CPU @ 2.20GHz,使用 50 个逻辑核心,运行时间约为 1 分钟。综合考虑,建议个人电脑选用约 7b 参数量的蒸馏模型。