最近关注到一件颇具启发性的案例。一家位于旧金山的几十人创业公司,每月支付给AI厂商的费用竟然超过了员工薪资总额。CEO的应对策略十分果断:全面替换Claude模型。
事情的起因是Lindy的创始人Flo Crivello在X平台发布了一张截图,上面赫然写着:“今天果断行动,将Lindy 100%的流量切换至DeepSeek v4。”随后补充道:此举可节省数百万美元,并且在多个核心业务场景中,性能反而有所提升。
这支几十人的团队,将原本完全依赖Claude运行的业务,彻底迁移到了DeepSeek。原因直截了当:AI账单过高,甚至超过了全体员工的总薪酬。
这一事件发生在大约一个月前,但到6月底才真正显现出后续影响。6月27日,DeepSeek开源了DSpark投机解码框架,生成速度提升了60%到85%。紧接着,他们又更新了Wayfinder Router——一个完全离线的模型路由工具,能够在微秒级决定调用本地模型还是云端API。
Lindy率先迈出了这一步,配套工具也随之跟上。这个信号再清晰不过:当企业难以承受“大脑”的高昂溢价时,自然会寻找“肌肉”来承担实际工作。
账单超过工资
Lindy的这次切换并非一时冲动。Crivello早在四月份就公开透露,公司的推理成本已经超过了工资总额。团队为此评估了六到九个月,期间还考察过Kimi K2.5和GLM-5.1,最终才选定DeepSeek v4。
迁移的工作量远超预期。Crivello的原话是:“工作量比我们想象的多100倍。”大量在线评估、离线测试、逐步灰度上线,观察对用户留存的影响,再针对性地调整提示词——整套流程走下来,仅迁移本身就需要投入巨大成本。但真正让他下定决心的,是实际测试的结果。
在邮件分类、根据用户语气预写回复等Lindy的核心场景中,DeepSeek的表现超出了预期。不过Crivello也并未夸大其词:在复杂的自动化流程上,Claude依然更胜一筹。
切换之后,成本曲线呈现出“断崖式下跌”。Crivello用了一个形象的比喻:“你应该看看我们的AI成本曲线,它就像一道悬崖。”
很多人会问:Claude公认是行业第一梯队模型,换成更便宜的DeepSeek,性能反而提升,这怎么可能?答案其实并不复杂。对于邮件分类、日程管理、高频自动化这类企业日常场景,模型参数过度冗余反而会增加延迟与成本。DeepSeek在这些特定任务上进行了速度和实用性的优化,没有单纯堆砌参数,因此在大量实际业务中实现了“更便宜、更快、更稳定”的效果。
Lindy的个案能否代表全行业?坦白说,很难一概而论。它做的是AI原生应用,成本结构与大型企业完全不同。但关键在于,6月底更新的Wayfinder Router,做的正是同一件事:帮助企业在本地模型和托管API之间自动选择最便宜的路线,微秒级决策,完全离线。如果这只是Lindy一家遇到的痛点,这种工具不会在这个时间节点出现。
速度提升六成
DeepSeek开源的DSpark,并没有发布新模型。它是在V4现有权重基础上,附加了一个草稿模块,通过半自回归生成实现无损加速。在生产环境下,V4-Flash和V4-Pro的每用户生成速度分别提升了60%到85%、57%到78%。离线测试中,接受长度比Eagle3高出26%到31%。
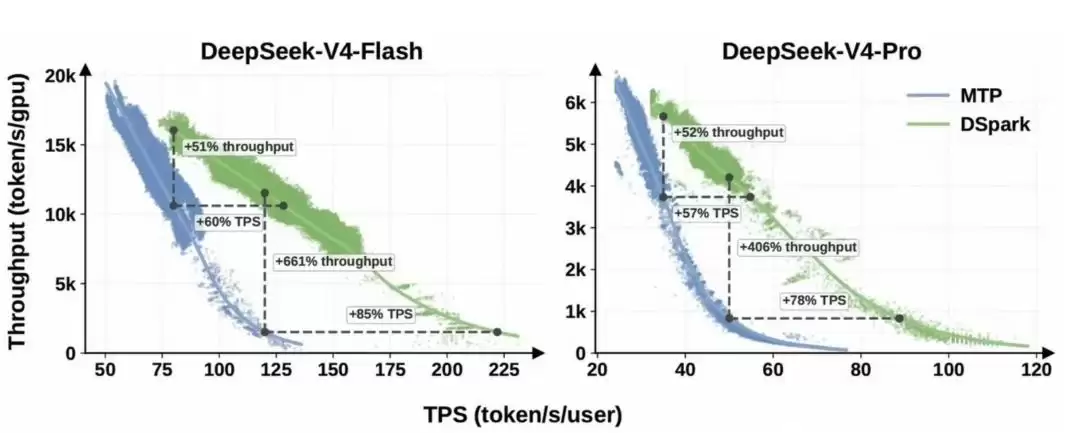
简而言之,它没有让模型变得更聪明,只是让同样的模型运行得更快、更省资源。对企业而言,这意味着用相同的硬件就能处理更多业务量——成本敏感型公司恰恰需要这个。
Wayfinder Router的逻辑更加直接。它通过分析提示词的结构特征——长度、标题、代码块——在微秒级决定采用本地模型还是云端API,完全不需要调用其他模型进行判断。以前企业需要人工或外部服务来“选模型”,现在一个离线工具就能搞定。

两个工具在6月底相继出现,一个负责“跑得更快”,一个负责“花得更少”。它们都不追求“最强智商”,只追求“够用且便宜”。

当行业不再为“参数翻倍”而集体狂欢,转而开始为“速度提升60%”、“成本降低一半”而欢呼时,AI就真正从实验室走进了商业应用场景。
各司其职
Anthropic的Claude当然非常强大。代码能力、推理深度、安全性,都属于第一梯队。Lindy自己也承认,在复杂的工作流自动化方面,Sonnet仍然更好。
但像Lindy这样用Claude来写邮件、管理日程、处理自动化工作流的企业,所支付的账单中,有一部分是在为“用不到的能力”买单。
5月份,Vercel的AI Gateway数据显示了一个耐人寻味的现象:DeepSeek的token流量占比从不足1%跃升至17%,但收入占比几乎没变。这说明它承接的全是低价高频的“体力活”。企业并没有放弃Claude来执行最难的推理任务,只是把“下面的事情”交给了更便宜的模型。
企业在算完账后,开始分层使用模型:高难度推理、复杂自动化、合规敏感场景,继续用Claude;高频低复杂度、对延迟敏感、成本压力大的任务,交给DeepSeek。两种模型各司其职,谁也不替代谁。
这种分层背后,是两条路线的分化。美国企业继续往“更聪明”的方向走,Claude、GPT在顶尖推理上持续投入。中国企业在做另一件事:把价格打下来,让中小企业用得起。DeepSeek的路线很明确,不在“大脑”上硬碰硬,而是在“肌肉”上做到极致。Lindy能够切换过来,靠的是中国在基础设施层面铺就的道路。
DeepSeek的出现,说明了一个道理:并非所有企业都需要顶级模型来处理所有任务。当Lindy发现切换后核心场景性能反而提升,成本断崖式下跌时,那些只需要“够用”的企业就会重新算账。
结尾
过去,企业选用DeepSeek往往带有“降级备选”的无奈;如今,Lindy的主动切换宣告了一个新现实:当开源模型的速度追上闭源,价格却仅为几分之一时,“性价比”本身就是最核心的竞争力。
Lindy后台那条断崖式下跌的成本曲线,记录的不仅是供应商的更换,更是一家美国公司在算完账后,对中国基础设施的真实选择。
AI的世界正在裂变为两条赛道:美国在往上走,打磨Claude和GPT的“大脑”,追求极致的智力上限;中国在往下扎,铺平DeepSeek的“道路”,拉齐全球的准入门槛。这两条路没有输赢,只有分工。对于企业而言,在这个从狂热回归理性的下半场,让每一份算力都花在刀刃上,比拥有最聪明的模型更重要。