单帧彩色图像中恢复多人三维姿态,究竟有多难?难度确实不小。这不仅是技术层面的挑战,更是对"景深"与"尺度"这两个在成像瞬间丢失的关键维度的重新捕捉与还原。在ECCV2020上,商汤科技与浙江大学联合实验室提出了一种单步解法,令人眼前一亮。他们设计了一个名为SMAP的网络,搭配一种全新的2.5D人体姿态表示方法,再通过一个深度已知的关键点匹配算法,最终稳定地计算出绝对三维人体姿态。其核心在于全局特征与局部特征的融合——这样一来,不同人物之间的前后遮挡关系变得清晰可辨,人与相机之间的距离也不再是未知数。在CMU Panoptic和MuPoTS-3D这些权威的多人三维人体姿态估计基准数据集上,该方法均达到了SOTA(state-of-the-art)水平,更令人惊喜的是,它在从未见过的场景中也展现出优秀的泛化能力。
论文名称:SMAP: Single-Shot Multi-Person Absolute 3D Pose Estimation

研究动机
基于单帧图像的人体绝对三维姿态估计,应用前景十分广阔,例如混合现实、视频内容分析、人机交互等场景。近年来,学术界更多聚焦于相对三维姿态估计,也取得了显著进展。然而,当任务转向多人场景下的绝对三维姿态估计时,情况变得复杂许多——除了要估算出人体相对的三维姿态,更核心的目标是确定每个人相对于相机的绝对空间位置。
目前多数方法采用何种策略?它们通常先将检测到的人体区域裁剪出来,再分别估计每个个体的绝对位置。部分方法利用检测框大小作为人体尺寸的先验信息,通过回归网络预测深度。这种做法的明显缺陷在于:忽视了图像的全局上下文信息。另一些方法则基于某些假设(如地面约束),通过后处理来推算人体深度。但这类方法受限于姿态估计的精度,且不少假设在实际场景中难以成立——举例来说,当人物的脚部被遮挡时,该如何处理?
一个合理的判断是:要准确估计人体的绝对三维位置,必须充分利用图像中所有与深度相关的线索——人体自身的尺度、前后遮挡关系、人物在场景中的相对位置等。近年来,不少工作尝试用卷积神经网络直接回归场景的深度信息,这给了我们一个重要启发:为何不让网络在推理阶段直接估算所有人的深度,而非要等到后处理环节才弥补这个缺口?
基于这一思路,我们提出了一种全新的单步自底向上方法。该方法在一次网络推理后,即可同时输出所有人的绝对位置信息和三维姿态信息。此外,我们还设计了一个基于深度信息的人体关键点匹配算法,其中包含"深度优先匹配"和"自适应骨骼长度约束"两个关键要点,进一步提升了关键点匹配的准确度。
方法详解
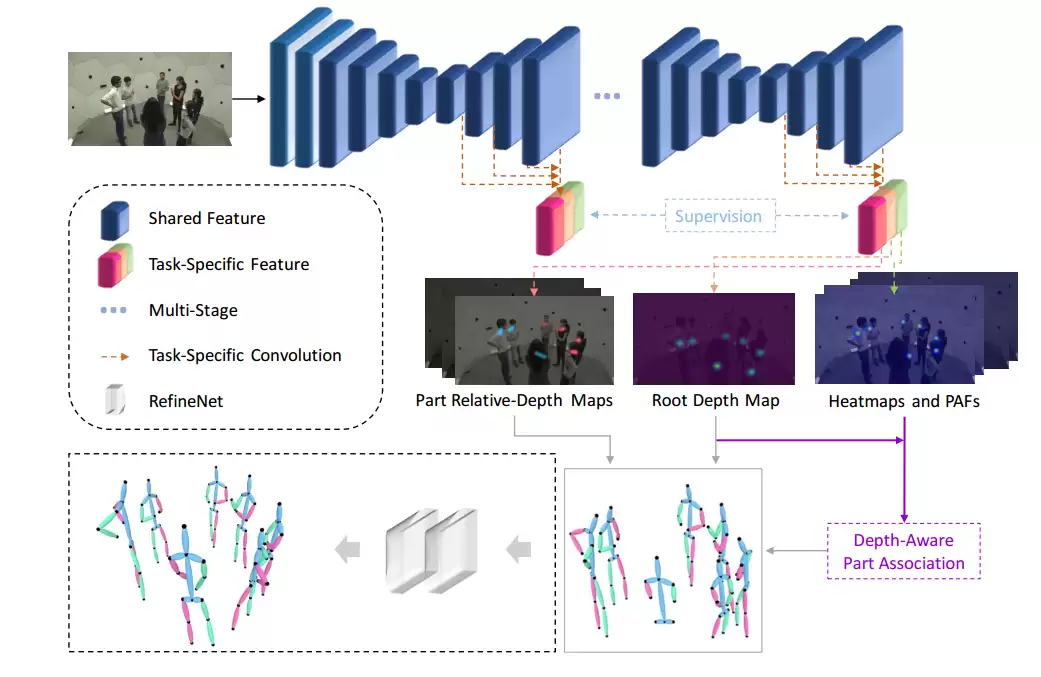
上图展示了所提方法的完整流程,包括SMAP网络、基于深度的关键点匹配(Depth-Aware Part Association),以及一个可选的微型优化网络(RefineNet)。输入一张彩色图像,SMAP网络同时输出四类信息:人体根节点深度图(Root Depth Map)、二维关键点热力图(Heatmaps)、关键点连接向量场(PAFs),以及骨骼相对深度图(Part Relative-Depth Maps)。借助这些2.5D特征表示,再执行关键点匹配,并结合相机模型,即可得到人体绝对三维关键点坐标。若需进一步优化与补全,可引入微型优化网络RefineNet。
2.1 2.5D特征表示方式
2.1.1 人体根节点深度图(Root Depth Map)
图像中的人数并不固定,因此我们设计了人体根节点深度图来表示每个人的绝对深度。在该图中,每个人根节点(例如脖子或腰部)位置的数值即为其绝对深度。训练时,我们仅对根节点位置进行监督。这种做法的优势显而易见:不受图中人数限制,且仅需三维人体姿态数据即可训练,无需整张图像的深度信息。
需要注意一个细节:对于同一深度下的同一个人,如果相机内参(FoV,视场角)不同,生成的二维图像会有所差异。这会对建立二维信息(如人体尺寸)与绝对深度之间的映射关系造成不利影响。因此,需要在输入网络前,利用FoV对深度进行归一化处理:
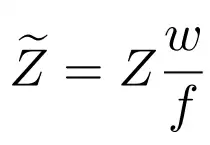

2.1.2 Heatmaps 和 PAFs
对于二维信息,我们沿用了OpenPose的表示方式。关键点热力图(Heatmaps)用于表示关键点位于某个像素的概率,关键点连接向量场(PAFs)则用于表示关键点之间相连的方向与概率。
2.1.3 骨骼相对深度图(Part Relative-Depth Maps)
骨骼相对深度图的生成方式与PAFs相同,区别在于它反映的是关键点之间的深度差值。
2.2 基于深度的关键点匹配算法
从关键点热力图(Heatmap)获取人体根节点位置后,即可从根节点深度图(Root Depth Map)中读取每个人的深度信息。我们利用这些深度信息来优化人体关键点匹配算法,旨在解决二维关键点匹配中常见的歧义性问题。
举个例子:当两个人之间存在遮挡时,如果某个关键点重叠,仅依赖二维信息的匹配方式无法判定该关键点究竟属于谁。这种情况极易导致大部分关键点被错误地连接在一起。而一个关键的观察是——重叠的关键点在绝大多数场景中应属于离相机更近的那个人。因此,基于网络推断出的深度信息,我们赋予离相机更近的人更高的连接优先级。这正是深度优先匹配的核心思想。此外,我们还引入了自适应骨骼长度距离约束。在二维匹配算法中,通常的做法是将图像宽度的一半设为关键点匹配的距离上限。但这忽略了一个事实:人与相机距离不同,在二维图像中呈现的尺寸也各不相同。固定约束无法适应这种变化。针对每个骨骼,我们使用训练集中该骨骼的平均长度作为其实际长度,然后利用网络输出的深度来计算它在二维图像中的最大长度:
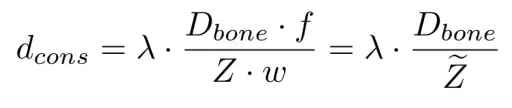

2.3 绝对三维姿态恢复
通过基于深度的匹配算法获得人体关键点匹配结果后,即可根据根节点绝对深度和骨骼相对深度计算出每个关键点的绝对深度。然后,利用以下公式进行反投影,即可得到人体关键点的绝对三维坐标:
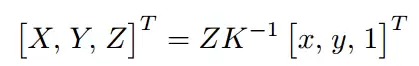
其中K是相机内参矩阵,在绝大多数应用中已知,即使未知,也可使用估计值替代。
由上述步骤恢复出的结果可能引入两种误差。第一,骨架以级联方式表示,因此在恢复末端关节点深度时会产生累计误差。第二,严重的遮挡和图像截断可能导致人体某些关键点缺失。针对这些问题,我们提出了微型补全网络RefineNet。它输入估计的相对二维和三维关键点坐标,输出优化与补全后的相对三维关键点坐标。需要注意的是,RefineNet不会对人体根节点绝对深度进行优化。
实验结果
我们的方法在CMU Panoptic和MuPoTS-3D这两个多人三维人体姿态估计数据集上均达到了SOTA水平。效果有多好?请见下图所示:
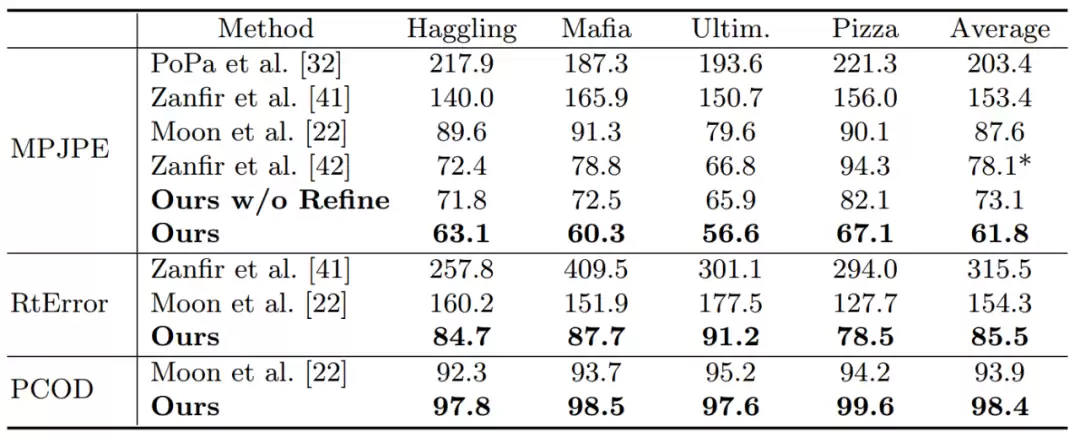
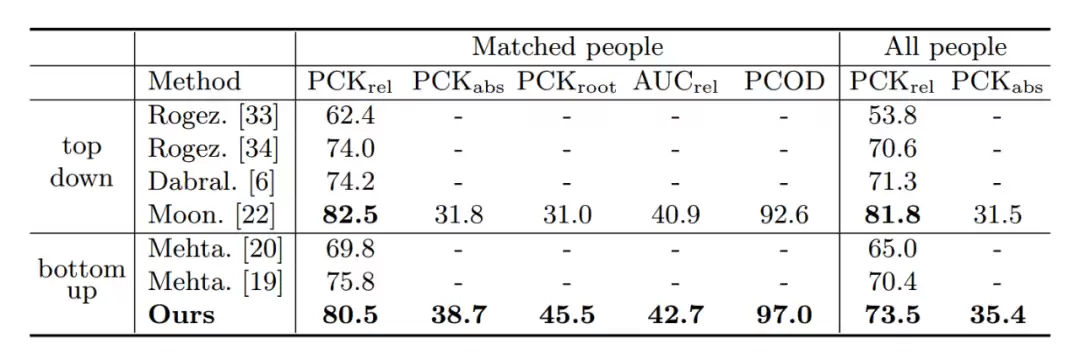
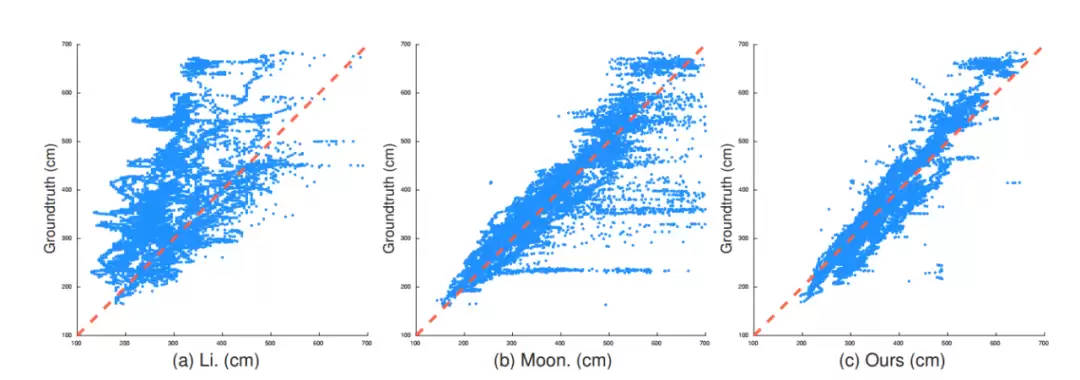
我们还对比了多种不同的深度估计方法。第一种是回归全图像的深度,第二种是根据检测框尺寸回归人体深度。从散点图可以直观地看出(横坐标是人体深度估计值,纵坐标是实际值,散点越靠近x=y直线代表深度回归越准确),我们提出的方法(Root Depth Map)在深度一致性以及泛化能力上均明显更优。
为了体现单步自底向上网络相较于自顶向下网络的优势,我们进行了定性分析。图中左侧是自顶向下网络的结果,可以看出它容易受到姿态变化、人体遮挡以及人体截断的影响。而我们提出的自底向上方法,由于能够利用全局信息,可以很好地缓解这些问题。