谈及DeepSeek-R1的本地部署,硬件配置始终是核心关注点。模型性能虽吸引人,但要在自己的设备上流畅运行,提前了解显存与算力门槛至关重要。接下来将详细解析,从基础模型到蒸馏版本,各自需要怎样的硬件配置才能实现稳定运行。
一、前言
DeepSeek-V3与R1的热度,推动了国内厂商争相接入与适配,生态繁荣令人欣喜。与此同时,越来越多个人和团队开始考虑在本地部署一套DeepSeek模型,无论是为了便捷体验,还是进行二次开发。但部署过程中,硬件准备不足往往是最大障碍。因此,本文系统梳理了DeepSeek-R1基础模型及其蒸馏版本的硬件要求,将底牌全面展示。
二、DeepSeek-R1基础模型本地部署配置要求
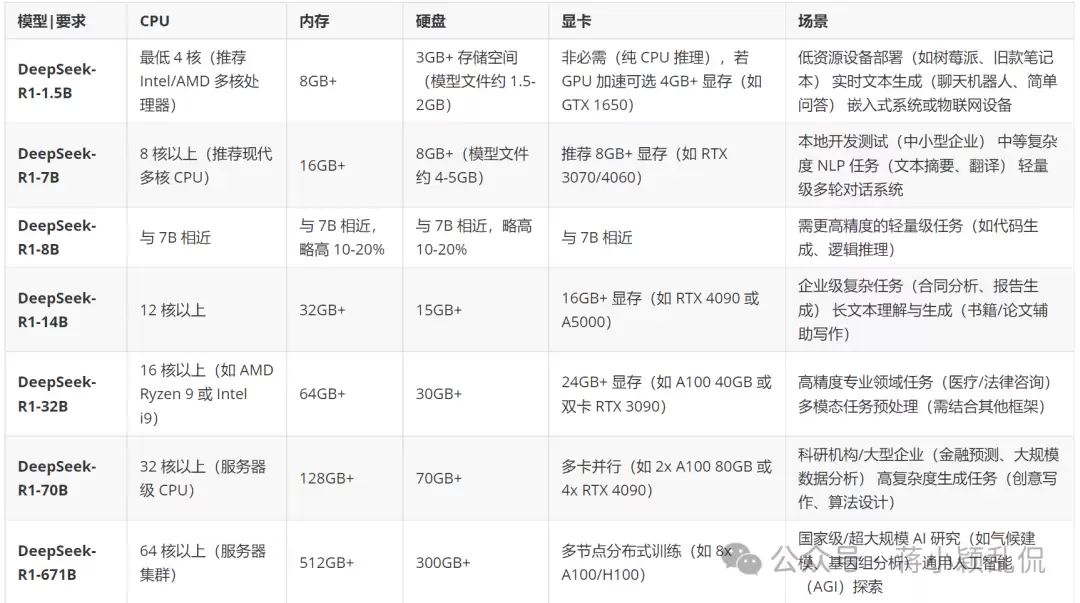
DeepSeek-R1本地部署与使用的通用建议
这里给出几条通用建议,对后续选择会有帮助:
- 量化优化:采用4-bit或8-bit量化技术,可降低显存占用30%至50%,性价比极高。
- 推理框架:搭配vLLM、TensorRT等推理加速库,可显著提升推理效率。
- 云部署:对于70B或671B等大参数模型,长期来看建议优先选择云服务,资源弹性扩展更为省心。
- 能耗注意:运行32B以上模型时,建议配备1000W以上电源,并做好散热措施。
三、DeepSeek-R1蒸馏模型及其量化版本本地部署配置要求
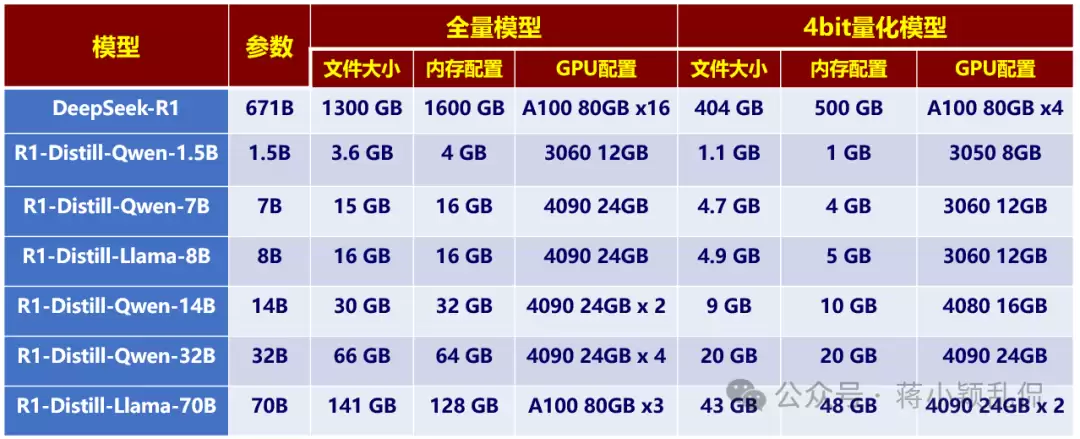
当切换到蒸馏模型时,CPU配置大致可参照同等参数规模的基础模型,甚至可略低。实际测试中,使用一张NVIDIA A40显卡成功运行了DeepSeek-R1-Distill-Llama-70B,无论是通过Ollama直接调用,还是通过Python程序提问,在普通问答场景下,响应速度和准确性均表现可接受。
此外,部署AI模型的最佳策略是按需选择。建议先从较小参数模型开始尝试,确认满足需求后再考虑升级至更大版本,既能节省资源,又能避免算力浪费,一举两得。