AI存储一直是算力竞赛之外的另一个瓶颈——数据加载速度跟不上GPU的胃口,再强的模型训练效率也要打折扣。最近DeepSeek开源的分布式文件系统3FS(Fire-Flyer File System)给出了一组令人振奋的数字:6.6 TiB/s的吞吐量、30分钟排序110.5 TiB的数据,这些性能指标足以让整个行业多看一眼。今天我们就来拆解这套系统到底凭什么这么强,以及它在AI全生命周期中能带来哪些实实在在的改变。
“今天,deepseek-ai开源了分布式文件系统3FS(Fire-Flyer File System)强势登场,号称要用6.6 TiB/s的吞吐量和30分钟排序110.5 TiB的惊人性能,彻底解决AI存储瓶颈。”
3FS官方仓库地址:
https://github.com/deepseek-ai/3fs

3FS的核心秘密——技术解构
3FS最大的杀手锏在于它的分离式架构以及对现代硬件的极致利用。它把数千块SSD的吞吐能力与RDMA网络的高带宽拧在一起,构建出一个没有位置限制的共享存储层。简单说,无论你的数据躺在哪个节点上,访问速度都跟本地盘一样快,完全打破了传统分布式存储的本地性束缚。
- 强一致性:通过CRAQ(Chain Replication with Apportioned Queries)实现,在分布式环境下也能保证数据不乱序、不丢失。
- 无状态元数据:基于FoundationDB的事务型键值存储,开发者无需学习新API,接入成本几乎为零——原有代码稍加修改就能跑起来。
- 多场景适配:从数据准备、训练样本随机访问,到高吞吐量检查点(Checkpoint)以及推理KVCache,3FS几乎覆盖了AI训练推理的全流程。
这种设计让3FS不仅仅是一个文件系统,更像是一个为AI量身定制的“数据翻跟斗”。
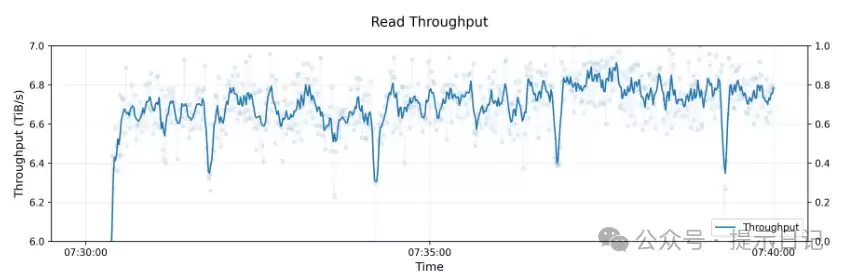
3FS硬核性能
接下来看看3FS的硬核数据——怎么说,确实有点惊人:
- 峰值吞吐量:180个存储节点加上500多个客户端,聚合读吞吐量高达6.6 TiB/s,而且即便有背景流量也不掉速。
- GraySort测试:25个存储节点加上50个计算节点,30分钟14秒排完了110.5 TiB的数据,平均每分钟处理3.66 TiB,这个成绩在分布式排序领域堪称“速度之王”。
- KVCache推理:峰值读吞吐量达到40 GiB/s,相比传统DRAM缓存方案,成本更低、容量更大,用在推理场景中简直是降维打击。
这些数字背后,是3FS对AI工作负载的深刻理解——它不仅反赌,而且能稳定应对高并发和复杂任务,这才是关键。
3FS的野心与潜力
说完了性能,再聊聊3FS的野心。很明显,它不只想做一个“反赌”的文件系统。通过统一的共享存储层,它要简化分布式AI应用的开发流程。想象一下:无需费劲预取数据、无需手动洗牌样本、检查点秒级完成、推理缓存成本直接腰斩——对AI工程师来说,这几乎是“梦中情盘”。
更关键的是,3FS是开源的,开发者可以按需定制、自由改造。它很可能成为AI基础设施中的一块重要拼图,甚至撼动现有分布式文件系统的格局。