智能体质量飞轮由编码智能体驱动的方法
类型:热点整理2026-07-01
让Agent质量可度量,而不是凭感觉 你刚把一个Agent上线了,跑得挺顺。然后你改了一版prompt,专门解决某个用户反馈的问题,在三个测试样本上看起来效果确实不错。但真正让你睡不踏实的是:这一改,会不会顺手破坏掉其他十个功能? 这种“在几个例子上看着变好了”和“在生产环境中真正变好了”之间的鸿沟
让Agent质量可度量,而不是凭感觉
你刚把一个Agent上线了,跑得挺顺。然后你改了一版prompt,专门解决某个用户反馈的问题,在三个测试样本上看起来效果确实不错。但真正让你睡不踏实的是:这一改,会不会顺手破坏掉其他十个功能?
这种“在几个例子上看着变好了”和“在生产环境中真正变好了”之间的鸿沟,恰恰是今天做Agent开发每天要面对的现实。绝大多数团队都有评估用例,绝大多数团队也都在改prompt。但能把这两个动作串起来,并且严谨地判断“这次改动到底是提升了指标,还是只提升了感觉”的团队,少之又少。
最可怕的失败往往不是那种轰轰烈烈的崩溃,而是那些看起来一切正常的沉默型错误——Agent给出自信的回答,生成的计划读起来也合理,却在安静地理解错用户真正的意图。在Cloud Next '26大会上,我们把Agent质量问题描述为一个三轮飞轮:**Build & Test → Ship & Monitor → Learn & Refine**,并给出了一系列支撑模块。今天要发布的,是面向开发者的战术入口:一个由你的编码Agent安装并直接驱动的技能包。
这个飞轮的方法论,以及作为其核心的AutoRaters评估器,底层逻辑跟我们用来评估和优化自家模型及第一方Agent的体系是同一套。AutoRaters正是与Google DeepMind团队紧密合作的产物。
拆解飞轮的内部机制
这个技能包的核心环节是 **Build & Test**(快速迭代循环),它把这个环节细化为五个具体步骤。不过这个技能的应用范围不止于此:同样的五个步骤也可以直接运行在生产数据上。首次执行时按顺序走一遍,然后可以循环执行第2到第5步,直到质量指标达标:
1. **准备数据**:基于已有的OpenTelemetry(OTel)追踪数据、手工构造的场景或合成数据,构建一个评估数据集。
2. **运行推理**:用Agent在数据集上执行,生成追踪记录;如果你已经有现成的追踪数据,这一步可以跳过。
3. **评分**:用Google的自适应AutoRaters(一种基于模型的评估器,能对追踪记录打分并给出解释),或者你自己的自定义指标进行评分。注意,*这是唯一一个必须执行的步骤*。
4. **分析失败**:阅读评估规则的结论,搞清楚*为什么*某个用例会失败;如果失败用例超过10个,使用自动损失分析(Automatic Loss Analysis)进行聚类分析。
5. **优化与迭代**:实施针对性的修复,重新执行2-4步,并与上一次的基线进行对比。
大多数失败案例都需要经过好几轮迭代才会看到指标真正发生变化,这个技能包把这种严谨的工程纪律固化了下来。
一个原则:优化者永远不能评审自己的工作
优化器和评估器必须保持解耦:不管是谁提出的修复方案(你的编码Agent、自动优化器,或者你本人),都绝对不能参与对修复效果的评审。最终的评分由Gemini Enterprise Agent Platform的GenAI评估服务独立完成。原理很简单:如果优化器能自己给自己打分,它就会学会“刷分”,而不是真心实意去改进Agent。这个看似不起眼的架构决策,远比表面看起来重要得多。
这个技能包是什么,不是什么
**它是什么**:一套方法论和编排工具,*在你的编码Agent内部运行*:它为你的目标选择合适的指标,调用GenAI评估服务,阅读评估结论,提出修复方案,并对比修改前后的效果变化。
**它不是什么**:
* **不是全自动的。** 它负责提议,你来决定是否批准。保留了“人在环中”的控制权,不是撒手不管。
* **不是绝对的真理来源。** 内置的AutoRaters远不止是让模型打个分那么简单。对于多轮对话Agent,它会从对话中提取用户的意图,为每个具体用例生成评估规则,对照每条标准验证追踪记录,并在多个样本间进行多数投票。虽然功能很强大,但它依然是基于模型的:它给出的分数是一个强的方向性信号。相比任何单次的绝对分数,更值得信赖的是不同版本间的*差值*。
* **不能替代真实流量。** 这个技能包可以用用户模拟器生成合成场景(这是GenAI评估服务的一个功能),但这只是冷启动时的应急方案。合成场景能帮你起步,但真正能让这个飞轮转得准的,是生产环境的真实数据。
这个技能包以两个版本发布,两者都基于同一个GenAI评估服务。根据你的技术栈,选择一个就行:
* *google-agents-cli-eval*:如果你使用agents-cli工具链构建ADK Agent。在skills.sh/google/agents-cli/google-agents-cli-eval安装。
* *agent-platform-eval-flywheel*:如果你直接使用评估SDK(适用于任何框架)。在skills.sh/google/skills/agent-platform-eval-flywheel安装。
实战:一个表面上成功、实则失败的案例
下面来看一个真实的Agent改进循环。阅读时请注意一个细节:开发者全程没有接触eval CLI,也没有手动指定过任何指标名称。他们只是安装了技能包,用自然语言描述了一个担忧,批准了一个行动计划,然后直接阅读了结果。具体怎么做,由技能包自己决定。其中最精彩之处,是技能包如何判断“到底哪个指标才能检测出这个失败”。
被测Agent是来自 *google/adk-samples* 的 `tra vel-concierge`(旅途管家),一个ADK多Agent旅行规划系统(灵感生成→规划→预订→临行前/途中/旅途后)。它会把正在规划的行程保存在会话状态中,这个特性恰恰埋下了一个非常隐蔽的Bug。
**你只需要这样告诉你的编码Agent:**
> *"在这个仓库上使用质量飞轮技能包。我担心 tra vell-concierge 能否妥善处理用户在对话中途提出的修改。比如,用户在规划过程中修改了计划(比如换了日期、换了酒店、人数变了),最终的行程是否真的反映了这些修改?还是它一直沿用着最初的方案?帮我设计一套测试方法,在开始跑之前先给我一个计划。"*
这就是全部的交互接口。没有命令行参数,没有指标名称。**这个技能包的任务,就是把你的目标翻译成正确的评估方案**。接下来就体现出它的价值了。它会先去阅读Agent的代码,然后给你汇报一个行动计划。它先是调用了两个内置的多轮AutoRaters,然后做了一件固定脚本无法做到的事情:*在它们的基础之上,为你添加了一个自定义的评分规则*,这个规则的目标就是精准抓住你关心的“修改前后”这一行为:
multi_turn_task_success 和
multi_turn_trajectory_quality 这两项都是自适应的:它们会为每个用例生成一套评估规则,理论上也能发现“修改遗漏”的问题。但这会落在一条与其他若干条规则并列的位置,而每次运行时生成的规则组合都可能不同,最终又会被糅合成一个混合分数。这样一来,就没有一个稳定的“修改是否被遵守”的度量指标可以用来设置阈值或观察趋势。因此,我需要把这个问题单独拿出来,定义成一个独立的指标:一个自定义评分规则,叫做
revision_honored。它会返回一个分类结果(HONORED / IGNORED / PARTIAL / NO_REVISION),这样我就可以精确计数、设置动作阈值(比如IGNORED超过20%就触发操作),还能在每次迭代中追踪它的变化。我会用用户模拟器生成25个用例,按5种修改类型分组。开始执行?
你批准了。在批准的那一刻之后,技能包就开始调用用户模拟器生成那些场景,然后使用两个内置评估器加上它自己创建的 `revision_honored` 规则来评分。只有少数几个用例失败了,数量还没到需要做聚类分析的程度,所以它直接阅读了评估结论,没有启动自动损失分析。以下是它实际执行的内容:
# 每个修改类型生成一次用户模拟(共5种类型:人数、目的地、日期、酒店、删除站点)agents-cli eval dataset synthesize -n 5 --max-turns 8 --model gemini-3.5-flash --instruction "$(cat instr_party_size.txt)" --environment-context "$(cat synthesize_env_context.txt)" -o traces_party_size.json
# 合并5个追踪文件,然后一次性对25个用例进行评分agents-cli eval grade --traces traces_merged.json --config eval_config_revisions.yaml
你没有自己写过任何一行命令。选择指标、选择模拟器、确定分组方式,全部由技能包完成;你只是描述了一个目标。
**第一轮。** 三个指标都返回了结果。内置的AutoRaters已经显示出明显的质量缺陷(平均分在0.6附近,按严格标准看通过率很低),而自定义的评分规则则精确地量化出“修改遗漏”问题在其中占了多大比例:
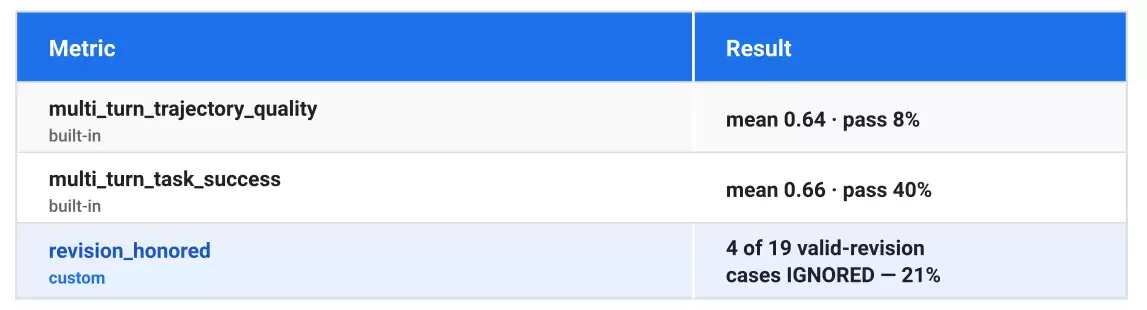
在这个评分规则下,IGNORED 表示 *修改内容被丢弃了*(其他可能的判定结果是 HONORED、PARTIAL 和 NO_REVISION)。这个21%的结果已经达到了技能包的预设干预门槛。更重要的是,评估结论精确地定位了失败的原因。不是你以为的那样:Agent并没有自信满满地确认一个错误的行程。在四个失败案例里,有三个案例中 **Agent的内部状态其实是正确的**(正确的值已经存入状态,也调用了正确的工具),但它 **最终回复给用户的消息里,竟然还是笼统地包含了旧的值**。Agent内部做对了,却在口头表述上自我矛盾。其中一条结论写得很清楚:
> *"尽管Agent在第3轮对话中调用 `memorize` 存储了正确的 `start_date`(2027-04-15)和 `end_date`(2027-04-19),但在用户明确修正后,它在最终输出时依然未能向用户提供正确的日期。"*
这就是那种“看起来一切正常但其实是错误的”失败的典型案例:没有崩溃,计划读起来也还行,Agent 的*语气*听起来像是完成了你的要求,但用户最终拿到的答案就是错的。这些案例的共因是:根Agent的指令中没有任何一句要求它在最终回复前,必须检查一下自己的回复和用户最近一次消息是否一致。
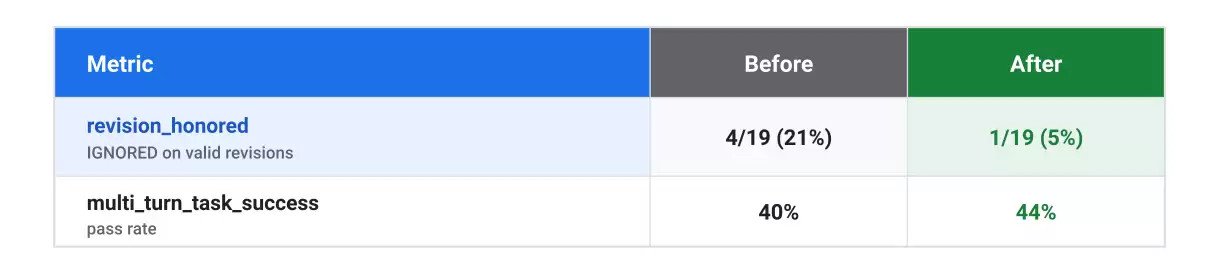
你可能会问,既然内置评估器已经是自适应的,那这个自定义规则是否还有必要?事实证明,发现问题本身不是难点,难在*隔离*问题。比如其中一个IGNORED案例(party_size_02)里,用户要求修改酒店,改成了“阿姆斯特丹Hostel World的青旅宿舍间”。下面这个对比清晰地展示了为什么需要自定义规则:内置的任务成功评估器给它整体打了0.80的高分。它确实生成了针对这一修改请求的评估规则,也标记为不满足(检测到了问题并解释了原因),但这一条不满足的规则和其他四条通过的规则混在一起,综合评分就被拉高了。而内置评估器无法做到的,就是给你一个单一的“这次对话是否遵守了修改要求?”的数据点,覆盖所有25个案例。必须把这个问题提升为一个独立的分类指标,你才能得到一个具体的数字(从21%降到5%),用来在修改前后进行精确对比。
**一个案例,三种评估:party_size_02**
*用户要求一个柏林到阿姆斯特丹的便宜旅行,5个人;随后在对话中将酒店需求改为“阿姆斯特丹Hostel World的青旅宿舍间”。*
**revision_honored(自定义)→ IGNORED。** *“Agent虽口头确认了这项修订,但最终呈现的依然是此前推荐的方案,并未按修订后的条件进行搜索,也未将新的偏好存入记忆。”*
**multi_turn_task_success(内置)→ 0.80。** 生成了5条评估规则,4条通过:✓ 便宜旅行5人 · ✓ 航班选项 · ✓ 确认选择easyJet · ✓ 提供了酒店选项。第5条失败:✗ *“提供‘阿姆斯特丹Hostel World’的宿舍间选项”*:*“Agent未能提供用户明确要求的信息……因为Agent自称缺乏相应工具能力。”* 修改遗漏的问题确实存在且被指出了,但它只是五条规则中的一条,所以综合分数依然很高。
**multi_turn_trajectory_quality(内置)→ 0.67。** 这里的扣分源于评估配置本身的一个缺陷,而不是Agent的错:评估器没有获取到Agent的工具描述,所以把合法的工具调用(比如 `flight_search_agent`, `_memorize_impl`)标记成了“不允许的工具”。这也说明了为什么在前后对比时,我们更依赖自定义规则和任务成功指标,而不是轨迹质量指标。
**修复与重跑。** 你批准了一个精准的修改:在根Agent的指令中增加了三句话,要求它在给出最终回复前,必须与用户最后一次提出的修改进行比对。技能包再次运行了相同的评估流程:
甚至不需要一个明确的目标
上面的周期是从一个清晰的目标开始的。但当你暂时还摸不着头脑、说不上来哪里不对劲的时候,这个技能包同样好用。你只要把它指向一个全新的Agent,说一声“*找出一个真实失败并修复它*”,它就会自动开始大范围扫描:合成多样化的场景,用内置的多轮指标进行评分,然后自己找出最主要的失败模式。
我们在另一个Agent上做了测试:来自 *google/adk-samples* 的 `software-bug-assistant`(软件Bug助手),一个连接了*真实*工具(背后是Postgres工单数据库的MCP工具箱,加上网页搜索和StackExchange搜索)的Bug分类助手。在没有任何预设目标的情况下,技能包立刻发现了一个问题模式:在15个用例中,有14个Agent虽然正确完成了任务,但**从未告诉用户它调用了哪些工具**。它自己的指令明明要求这样做,但模型却悄悄地把这个要求当成了可选项。只需要修改一段话,强制要求每个回复现在都以一个脚注结尾,比如“已使用的工具:search-tickets, get-ticket-by-id”,就能在一次迭代中把所有15个用例的该指标从 **0%** 提升到 **96%**。
同一个技能包,更宽松的指令。“我要解决这个问题”和“帮我找个问题”,都能到达目标。
这两次迭代的关键点完全一致:为你改变的特定行为挑选一个稳定的度量标准(可以是一个自定义评分规则,也可以只是一个简单的计数),然后把这个标准作为你改进的基石。同时把自适应内置指标作为衡量整体健康度的信号,因为它们的规则每次运行都在变化,不适合作为迭代前后的精确对比。
从开发内循环到生产外循环
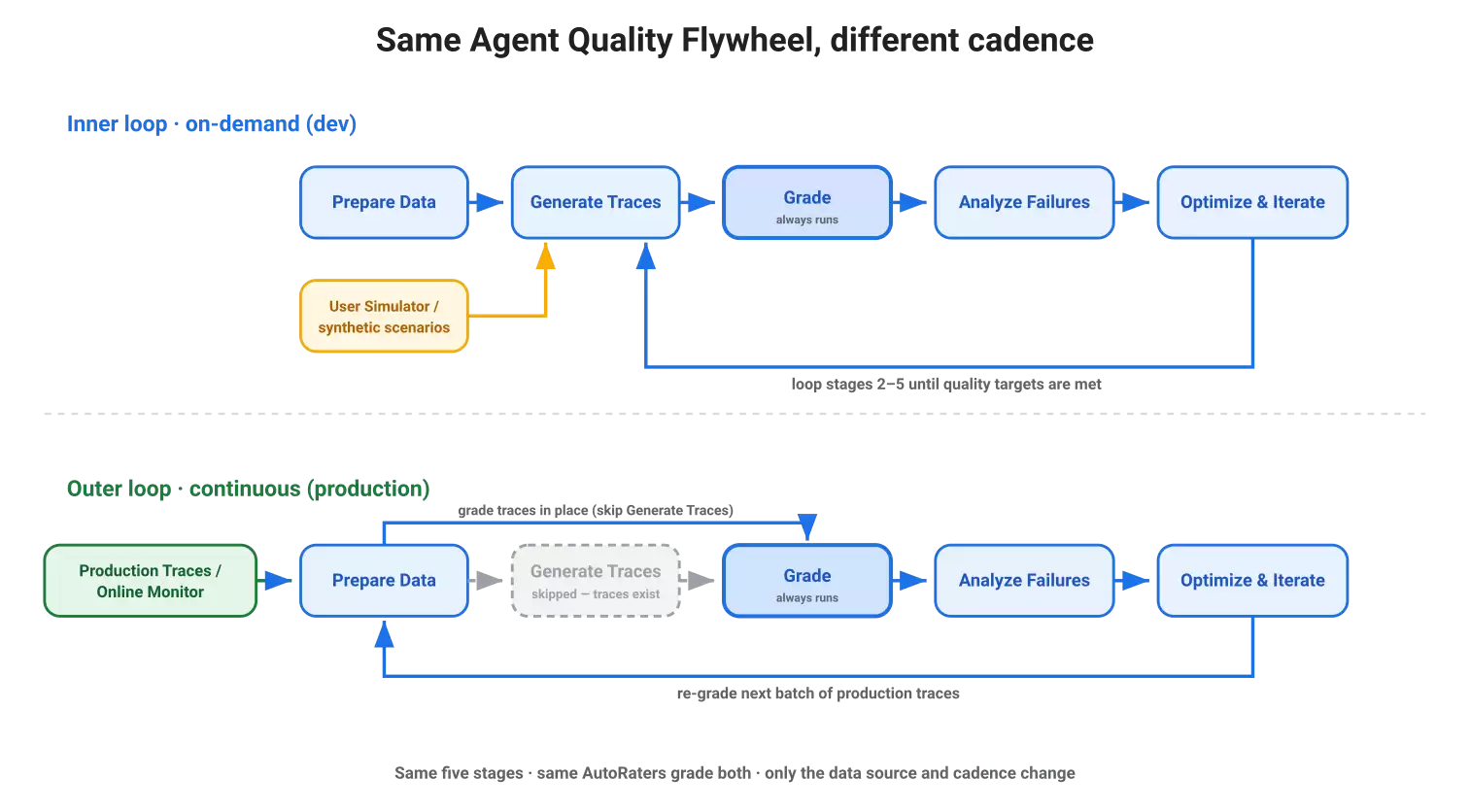
前面的周期使用了用户模拟器,因为当时还没有真实的用户数据可用——这是按需进行的、开发侧的操作。随着Agent逐渐成熟并开始处理真实流量,生产环境的会话记录就成了最有价值的输入。每一次真实的会话请求,都包含了一个真实的用户意图(来自用户、另一个Agent,或者上游服务),每一次失败都为一个新的迭代周期准备好了一个天然的测试用例。同样的五个步骤,现在用真实的使用数据替代了模拟数据。
同一个技能包可以直接运行在生产数据上;你只需要让它指向真实的追踪记录,而不是合成的。告诉它“分析一下上周的生产会话”,因为它面对的追踪记录已经是完整的,它会直接跳过运行推理这一步,直接调用相同的评估器进行评分。线上的监控器会持续评估实时流量,把质量分数写进Cloud Monitoring;当分数出现波动,你就可以把失败的追踪记录交给同一个技能包来处理——就是你刚才看到的那个评估-修复循环。同一个飞轮,只是节奏不同:生产环境是持续的,开发环境是按需的。评估两端的是完全相同的AutoRaters。
目前,这个技能包负责执行开发内循环,并在你指定方向时处理生产环境的追踪记录。未来的方向是让它更多地自主驱动生产端的外部循环:观察监控数据,主动发现指标回归,并在流量变化时提出修复建议。
现在就开始
**你需要准备:** 一个启用了Agent Platform GenAI评估服务的GCP项目,一个待评估的Agent(ADK或其他框架均可),以及一个负责驱动技能包的编码Agent。如果需要对生产流量进行评估,Agent还需要输出OpenTelemetry追踪数据(ADK默认支持)。
安装你的编码Agent将驱动的技能包:
# CLI驱动 (ADK + agents-cli):npx skills add https://github.com/google/agents-cli --skill google-agents-cli-eval
# SDK驱动 (所有框架):npx skills add https://github.com/google/skills --skill agent-platform-eval-flywheel
然后开始一个迭代周期:将技能包指向你的Agent,描述你想要度量的内容。你的编码Agent会接手剩下的所有工作。
你的Agent不必一开始就是完美的。它只需要能被持续改进。
来源:https://www.bestblogs.dev/article/10fc7b2b?utm_source=rss&utm_medium=feed&utm_campaign=resources&entry=rss_article_item