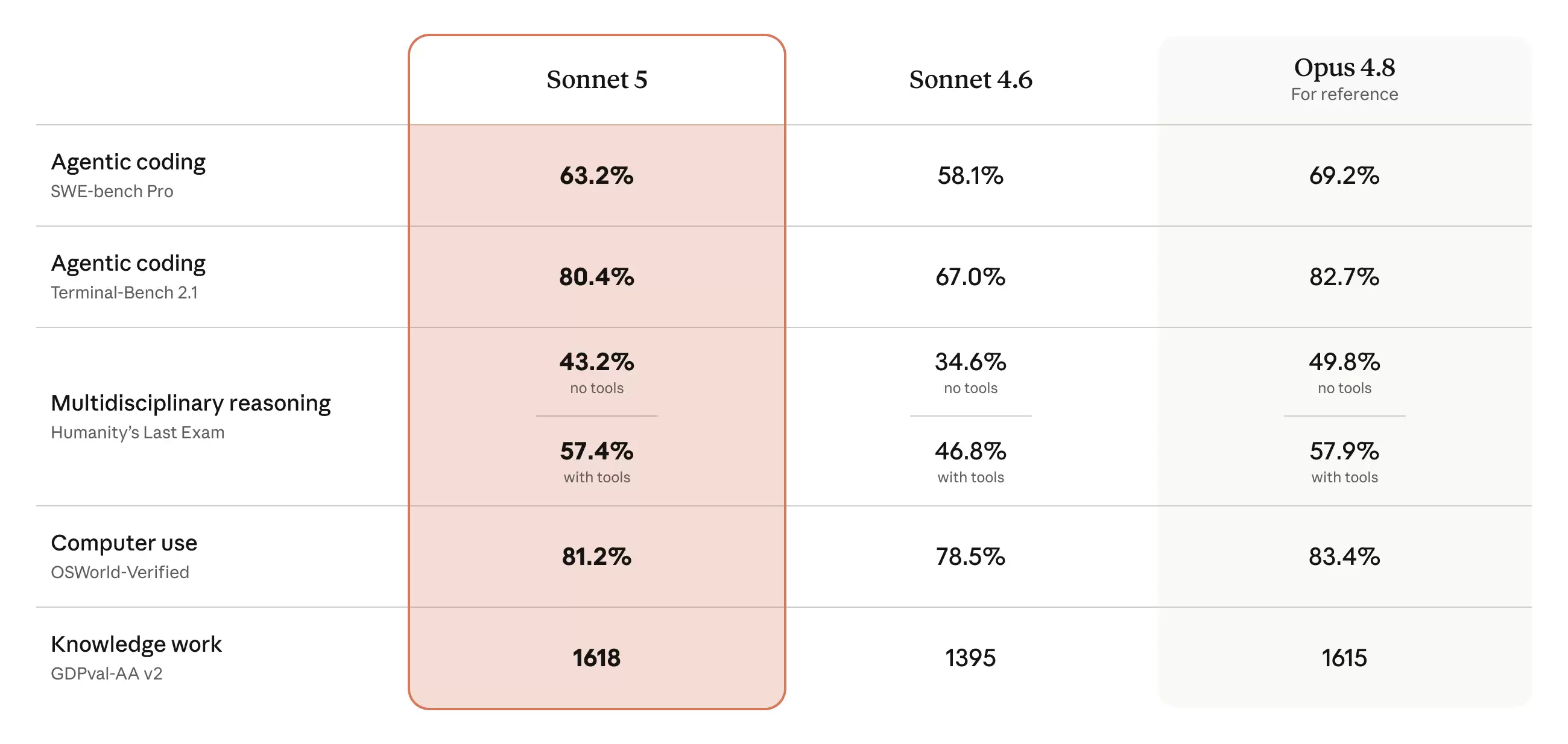
Claude Sonnet 5的主要目标就是成为迄今为止最具自动化能力的Sonnet模型。它能制定计划、使用浏览器和终端这类工具,并且自主运行的能力,在几个月前还只有那些更大、更昂贵的模型才能做到。
对很多开发者来说,智能体AI的时代是从Sonnet家族开始的:Claude Sonnet 3.5、3.6和3.7最早在编码和工具使用上展示了令人印象深刻的能力。不过最近一段时间,自动化能力最明显的提升更多地出现在我们的Opus系列上。
Sonnet 5正在迅速缩小这个差距:它的性能已经接近Opus 4.8,但价格低得多。相比前代产品Sonnet 4.6,它在推理、工具使用、编码和知识工作等关键的自动化表现方面都有大幅度提升:
安全评估显示,Sonnet 5的不良行为总体发生率低于Sonnet 4.6,在自动化场景下使用时也更安全。评估还表明,它在网络安全任务上的能力远低于我们现有的Opus模型。
从今天起,Claude Sonnet 5在所有套餐中均可使用:它是Free和Pro计划的默认模型,同时也适用于Max、Team和Enterprise用户。它也可以在Claude Code和Claude Platform上使用,上线初期采用优惠定价:每百万输入tokens 2美元,每百万输出tokens 10美元,有效期至2026年8月31日。之后标准定价为每百万输入tokens 3美元,每百万输出tokens 15美元。开发者可以通过Claude API使用 claude-sonnet-5。
Claude Sonnet 5 的实际表现
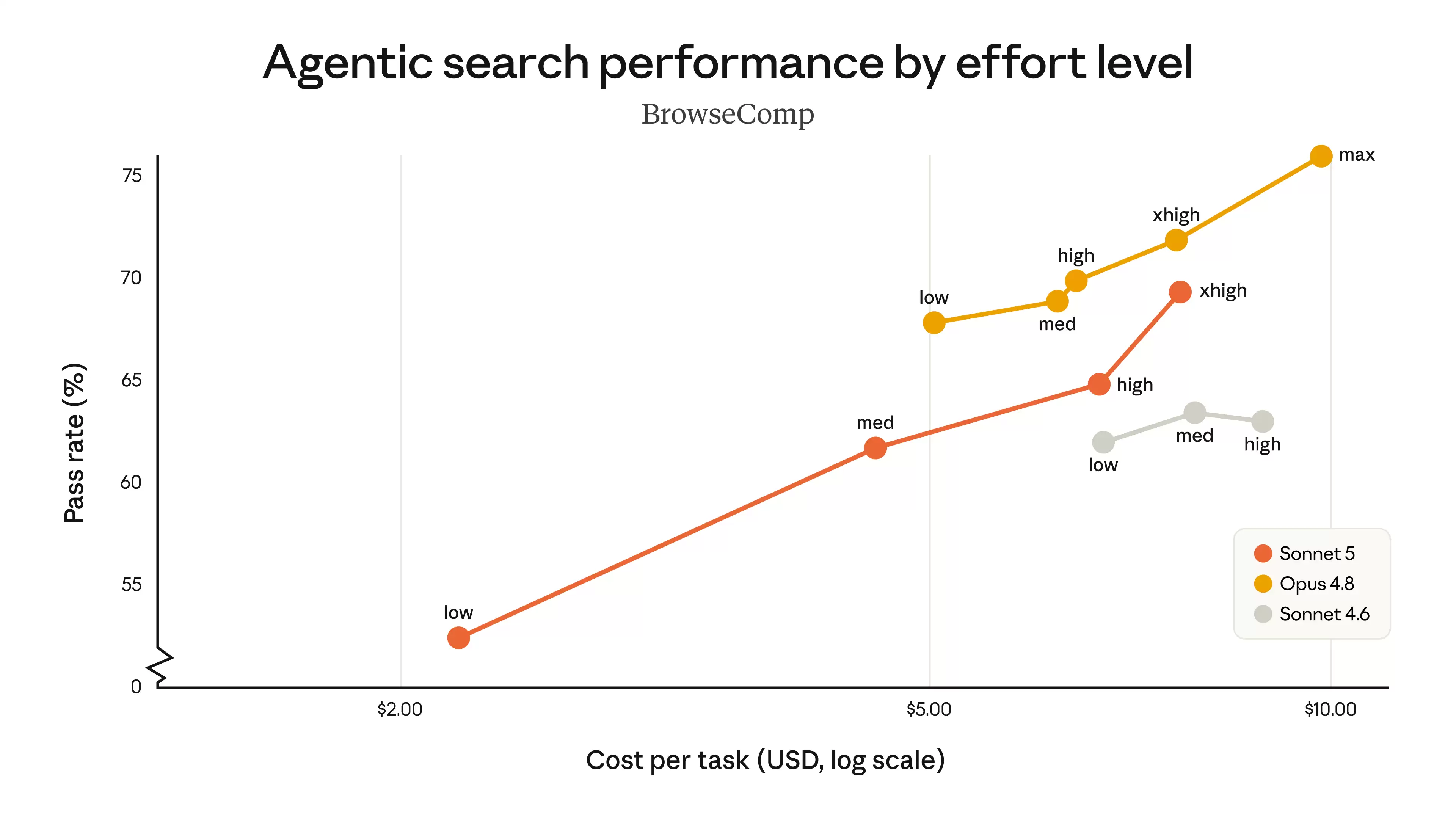
下面的图表比较了Sonnet 5、Sonnet 4.6和Opus 4.8在不同努力级别下,针对自动化搜索评估BrowseComp和计算机使用评估OSWorld-Verified的性能表现。Sonnet 5(橙色线)相比Sonnet 4.6(灰色线)是严格意义上的提升。Opus 4.8(黄色线)在这些任务上仍然是追求更高准确率的首选,但Sonnet 5为开发者提供了一个更低价的选择,且质量远超此前的同类产品。在Sonnet 5和Opus 4.8之间,用户可以根据所需努力程度来调整,找到成本与性能的最佳平衡点。
来自早期访问合作伙伴的反馈高度一致:Sonnet 5比其前代产品要“主动”得多。测试者描述了它如何完成以前Sonnet模型会半途而废的复杂任务,如何在未被明确要求的情况下自行检查输出,以及如何以极具吸引力的价格完成所有这些自动化工作:
Claude Sonnet 5为我们的智能体在多步骤软件工程工作中提供了一个强大的执行层。它能很好地处理混乱的技术环境中的持续编码、工具使用和调试,在需要跟进和技术性落地的流程中尤其有用。
我们交给Claude Sonnet 5一个两部分的任务——更新Salesforce账户层级,并向企业联系人发送发布公告——它从头到尾都完成了。过去这种任务会卡在半路。对于日常自动化来说,这是个无需动脑筋的选择。
Claude Sonnet 5用更少的步骤完成更多的工作。同样的输出质量,步骤更少。它拒绝不安全请求的方式清晰而一致。在Lovable,我们正在将强大的工具交到数百万构建者手中。一个懂得何时说“不”的模型和懂得如何构建的模型同样重要。
我们把Claude Sonnet 5用于数十个最具挑战性的真实pull request,它每个都自主完成了从测试到验证的全部流程,让我们的工程师可以专注于判断、决策和最终签字。
我让Claude Sonnet 5调查一个bug。没有提示,它自己写了一个复现测试,实现了修复,然后暂存修复以确认没有这个变动bug会重新出现。所有这些都在单次运行中完成。
有了Claude Sonnet 5,智能体能坚持计划,遵循我们的约定,并以高效的交付多步骤变更,而且成本控制得很好。
Claude Sonnet 5在老旧代码上表现出色——竞态条件、隐藏测试、那些没人愿意触碰的部分。它能追踪到失败的真正根源,并交付一个持久性的修复,而不是仅仅修补表象。
Claude Sonnet 5在Eve的原告律师任务中处于帕累托前沿。我们在法律研究与分析方面看到了最清晰的进步,其性价比让迁移决策变得非常容易。
ClickHouse智能体实时探索数据并即时产出洞察,因此测试新模型时时间-洞察力至关重要。Claude Sonnet 5以更紧凑的步骤进行推理,让我们的用户明显更快地得到答案。这种速度是我们的客户能感受到的差异。
在Pace,我们的计算机使用智能体在保险公司运营团队已经使用的系统上运行保险工作流程——业务提交、首次损失通知(FNOL)、损失记录。Claude Sonnet 5能持续采取正确行动并快速完成,这恰恰是真实保险工作所需要的。
安全评估
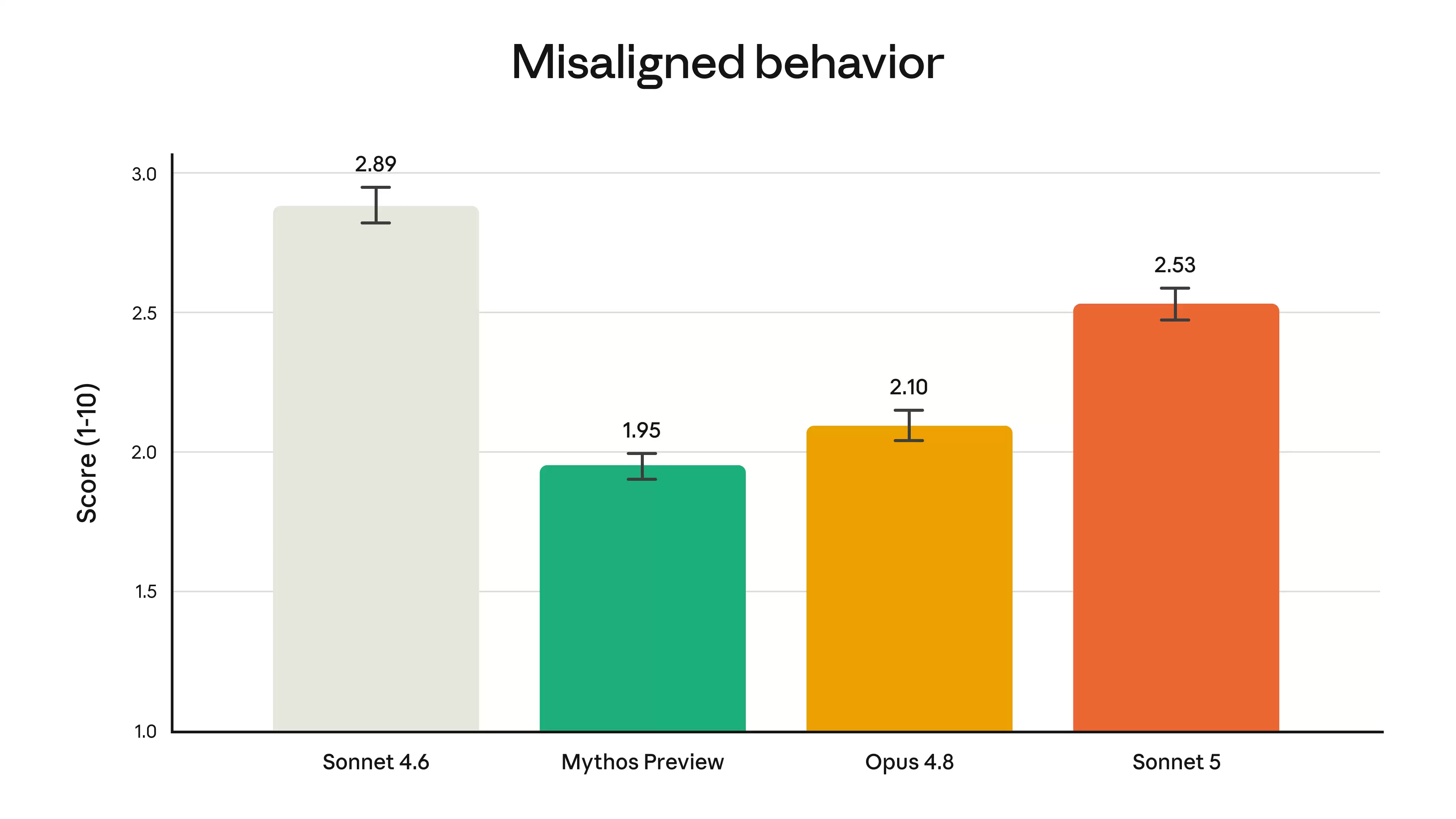
部署前的安全评估发现,Sonnet 5相比Sonnet 4.6整体上是一个改进。在自动化安全方面,该模型在拒绝恶意请求和抵御提示注入攻击方面表现更好。相比Sonnet 4.6,模型的幻觉率和谄媚率也更低。在我们自动化的行为审计中(该审计测试了包括与滥用和欺骗合作在内的广泛不当行为),Sonnet 5的总体得分更低(即更安全)。不过,与能力更强的Opus 4.8和Claude Mythos Preview相比,它在这次评估中确实表现出略高的不当行为发生率。
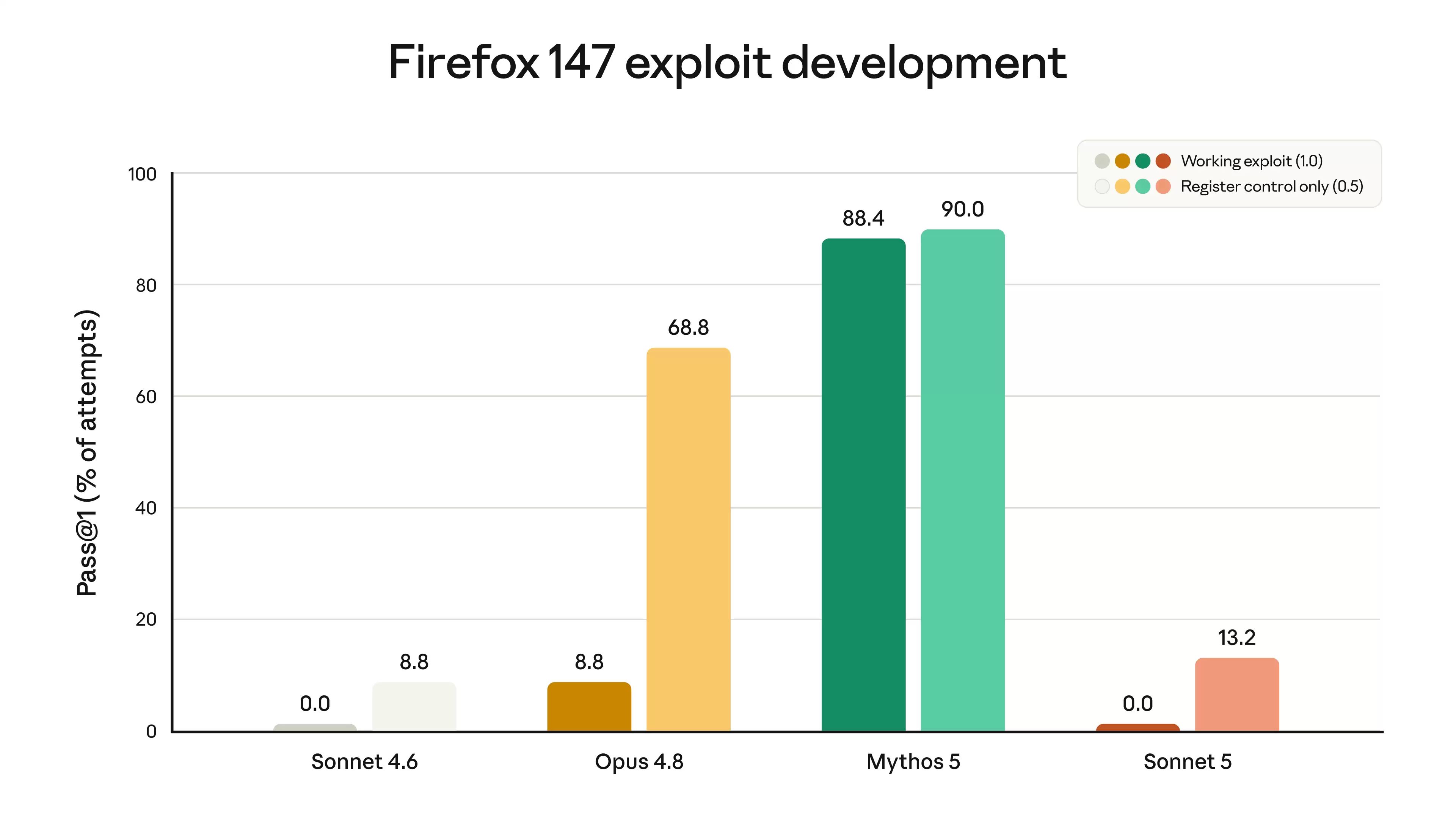
我们没有刻意针对网络安全任务训练Sonnet 5。它可以执行一些常规、无害的网络任务,但在测试潜在危险网络技能(如开发软件漏洞)的评估中,其表现远不如Opus 4.8和Mythos 5等模型。下图表显示了其中一项评估的结果,该评估测试了模型为Firefox 浏览器漏洞开发利用程序的能力。Sonnet 5从未能够成功开发出一个完整可用的漏洞利用程序,但与Sonnet 4.6相比,它确实显示出略高的部分成功率。这个变化很可能是通用智能提升的结果,而非针对性训练所致。
由于Sonnet 5在这些任务上比其前代稍强,我们默认启用了网络保护措施。这些措施——能够实时检测并阻止危险的网络使用——与Claude Opus 4.7和4.8中的相同(因为我们判断Sonnet 5的总体网络安全风险水平较低,所以这些措施不像随Fable 5发布的那么严格,后者会阻止范围更广的网络安全任务)。1
我们对Sonnet 5在多项安全和能力评估中的完整评估在Claude Sonnet 5系统卡片中有详细报告。
可用性与定价
Claude Sonnet 5现已全面开放使用。上市优惠期定价为每百万输入tokens 2美元,每百万输出tokens 10美元,有效期至2026年8月31日。之后将转为标准定价:每百万输入tokens 3美元,每百万输出tokens 15美元。2 我们已提高了Chat、Cowork、Claude Code和Claude Platform上的速率限制3,以适应用户使用更高努力级别时增加的token消耗;用户可以根据自身项目需求选择相应的级别。
脚注
1 Sonnet 5属于我们的网络验证计划(Cyber Verification Program)。该计划现已可直接在原生Claude Platform、AWS上的Claude Platform以及Microsoft Foundry中的Claude(托管于Azure和Anthropic)上使用,并即将在Google Vertex中的Claude上推出。已经注册网络验证计划的组织将自动获得对Sonnet 5的相同访问权限,无需重新申请。总体而言,对于需要减少护栏的网络安全工作,我们推荐使用Claude Opus 4.8。
2 Sonnet 5是对Sonnet 4.6的升级,但它使用了更新的分词器(tokenizer),以改变模型处理文本的方式并提升性能(这与我们随Claude Opus 4.7引入的分词器更改类似)。其代价是相同的输入可能映射为更多的tokens:大约为1.0–1.35倍,具体取决于内容类型。上市优惠定价旨在确保向Sonnet 5的过渡在成本上大致持平。
3 2026年4月26日,我们在每个使用层级提高了Sonnet和Haiku的速率限制,并在原生Claude Platform上简化为三个层级(Start、Build和Scale)。您可以在Claude Console中查看您的层级和当前限制,或查阅文档了解更多信息。
- 人类最后的考试: 我们更新了“人类最后的考试”的评分模型,并将Sonnet 4.6的得分更新为34.6%(无工具)和46.8%(带工具)。这是该分数与Sonnet 4.6发布博客中报告的数字不同的原因。
- OSWorld-Verified: 我们调整了OSWorld-Verified评估的运行方式,以更准确地反映模型在真实世界中的表现,并将Sonnet 4.6的得分更新为78.5%。这是该分数与Sonnet 4.6发布博客中报告的数字不同的原因。