比Playwright更给力的AI Agent浏览器自动化开源项目
时间:2026-07-01 17:40
BrowserAct是一款面向人工智能智能体的浏览器自动化命令行工具,通过隐身浏览器和动态 静态代理,解决了动态内容加载、Cloudflare反爬及账号长期登录等问题,使智能体能稳定执行浏览器操作,成为连接模型与现实世界的基础设施。
事情是这样的。
最近这一两年,日常的活基本都交给
Claude Code 了。让它帮忙整理文件、写代码、查资料、做总结,凡是能交出去的绝不动手。一个很深的感受是,Agent 这种东西,用得越深,越离不开它。但用得越深,也越能踩到它的坑。
前两天就踩了一个特别离谱的坑。
想让 Agent 去某个网站抓一点数据回来。听着不复杂,就是打开网页、等加载完、把内容拽下来。脑子里想,这玩意不就是个 Playwright 的活吗,几行代码的事。结果一跑起来,整个人都不好了。
第一关,登录态没。Agent 打开的浏览器是个什么都没有的全新小白板,连账号都没登录,直接被拦在门口。第二关,验证码。好不容易绕过登录这关,网站弹出来一个滑块。Agent 直接卡死,task 中断,啥都干不了。第三关,反爬。某些网站都不点名了,Agent 的请求一发出去,直接被 Cloudflare 拦在 403 那一页,连页面长啥样都没看到。
折腾了两个小时。期间还自己上手写 Playwright,写一段、跑一次、报错一次、再改一次。捣鼓下来,感觉头发都少了几根。
当时就在想,AI Agent 操纵浏览器这个事,听着是真性感,跑起来是真操蛋。
后来冷静下来想了一下,这其实不是 Agent 不聪明,是它缺一个稳定的浏览器执行层。Agent 自己,是个脑子。它需要一双手,一双能真正伸到浏览器里的手。然后有个朋友推荐了一个 GitHub 开源项目,叫 BrowserAct。

本来是抱着试试看的心态。浏览器自动化这块,已经被各种工具伤过太多次了,那种一看就牛逼轰轰的项目见过太多,真上手全是坑。但这次,是真的被爽到了。
先简单说一下这玩意是啥。
BrowserAct 是一个面向 AI Agent 的浏览器自动化 CLI。注意这个定语,面向 AI Agent。这就跟传统的 Playwright、Selenium 完全不是一个物种。
Playwright 是给程序员写脚本用的,你写一行代码,它执行一个动作。它是个确定性的执行工具,你让它点哪里它就点哪里。但 BrowserAct 不一样,它是给 Agent 用的「真实浏览器执行层」。你不用告诉它先点哪个按钮、再点哪个按钮,你只要告诉它「我要干嘛」,剩下的它自己想办法。而且它解决了那天晚上踩的所有坑。
一个一个说。
动态加载?直接拿下
回到抓数据这块。最先试的,是抓一个动态加载的网站。就是那种页面源码里啥都没有,所有数据都是 Ja vaScript 异步加载的网页。搞爬虫的朋友应该都知道这种页面有多恶心。
让
Claude Code 分别用三种方式去抓:curl、WebFetch、还有 BrowserAct。curl 是最原始的,纯命令行请求。它连 Ja vaScript 都不执行,碰到动态页面直接拿回来一堆空壳。WebFetch 稍微高级一点,但说到底还是个静态请求工具。结果也确实是这样。curl 拿回来的就是一堆 HTML 框架,数据是一个没有。WebFetch 也差不多。
但 BrowserAct 这边,它启动了一个 Stealth 浏览器实例,真实地把页面加载完了,把 Ja vaScript 跑完了,然后再把数据拽出来。跑完一看,电影名称、评分,整整齐齐躺在表格里。
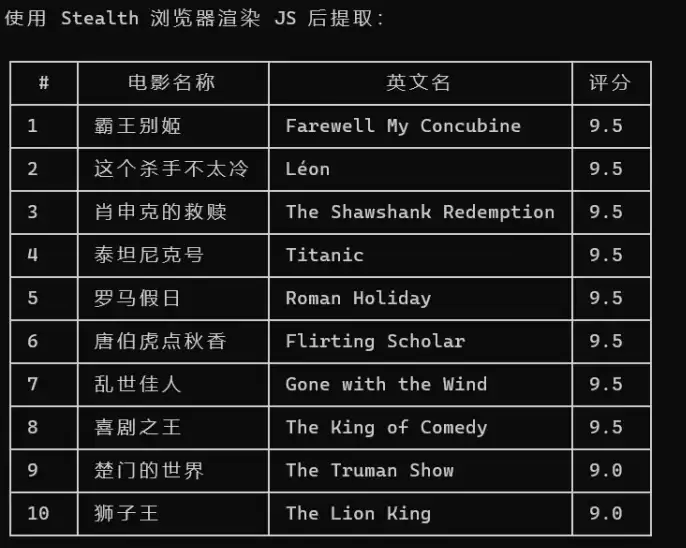
当时就觉得,有点意思。
反爬?Cloudflare 也能绕
但这个还不够刺激。真正让人「卧槽」的,是第二个场景,反爬。玩过爬虫的朋友应该都懂,IP 被限这个事,是个绕不开的痛。你高频访问一个网站,IP 迟早要被风控盯上。
让 BrowserAct 用 Stealth 浏览器配合动态袋里,去抓 Product Hunt 今日热门产品。为啥选这个站,因为这玩意上面套了一层 Cloudflare。一般工具进去就是 403。
让 Agent 分别用直连和动态袋里两种方式去抓。直连那次,请求一发出去,直接被 Cloudflare 拦死。返回的就是那个经典的「Just a moment...」等待页面,Agent 在那转圈,啥也进不去。动态袋里那次,成功进去了。不仅进去了,还把今日热门产品列表完整地抓了回来。
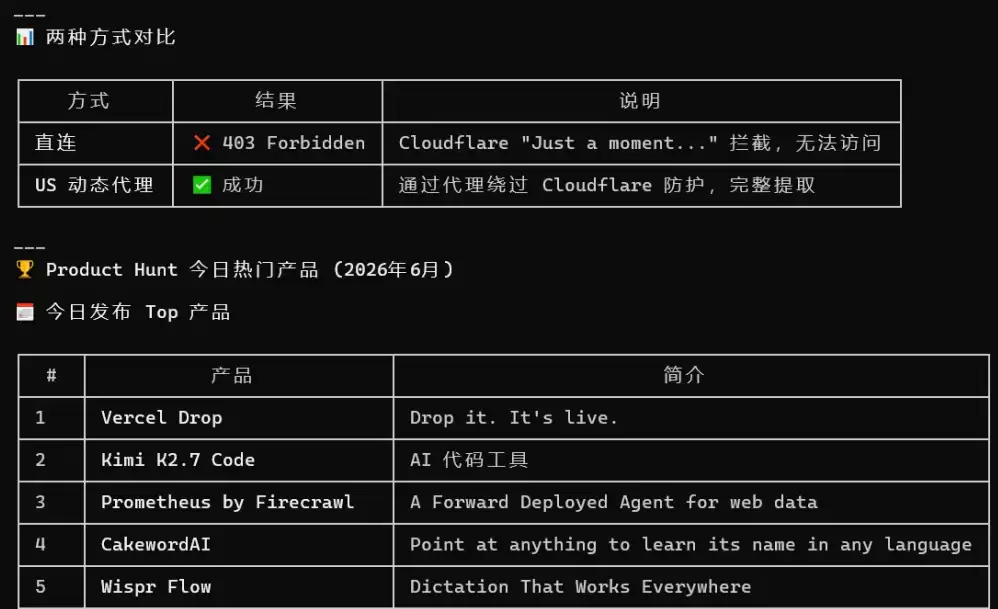
看了一下它的工作原理。动态袋里让请求的 IP 跟直连不一样,再加上 Stealth 浏览器的指纹伪装,两层叠加之后,网站看到的是「不同地方的不同用户在正常浏览」。被拦的概率,大幅下降。
到这里,已经觉得这玩意很能打了。
账号长期登录?这才是灵魂
但更骚的还在后面。第三个场景,是这个项目真正戳到我的点:账号长期登录。
很多朋友可能没意识到这个事有多重要。解释一下。你想想看,假设你有一个 X 账号,你今天用 IP-A 登录,明天用 IP-B 登录,后天又换一个 IP-C。每次的浏览器指纹还都不一样。平台会怎么判断?它会认为你的账号在被一群不同的人使用,或者在被批量操作。然后你的号就没了。
所以对于多账号运营、多店铺管理、长期数据采集这种场景,你需要的是固定 IP 加固定指纹。这就是 BrowserAct 的静态袋里功能。
用静态袋里绑定了一个 Stealth 浏览器,去访问 X。第一次访问,拿到了主页前 10 个帖子的标题、点赞数、评论数,还有浏览器的出口 IP、Cookie 摘要、指纹摘要。到这里都很正常。
真正炸的,是接下来的操作。关掉了这个会话。过了一段时间,重新启动 Agent,再让它做同样的操作。新开一个会话,重启浏览器,再访问一次 X。
两次结果放在一起对比,真的被惊到了。
IP 完全一致。两次独立会话、两次浏览器重启,IP 始终锁定在
28.56.87.14。Cookie 关键信息一致。10 个 Cookie 里 8 个完全一致。最关键的 loid,就是 X 的匿名用户 ID,跨会话不变。这意味着 X 把这两次访问识别为同一个用户,不会触发「新设备登录」检测。浏览器指纹一致。两次会话生成的指纹完全相同。
也就是说,IP、Cookie、指纹三项全部一致,唯一变化的是内容本身。这正是「一个正常用户多次打开 X」该有的样子。同一台设备,同一个网络环境,每次看到的是最新内容。
测完之后愣了一下。因为这一刻突然意识到,Agent 终于能像人一样操纵浏览器了。
一点更深的思考
聊到这儿,想说点更深的。行业这一两年一直在喊 AI Agent 会碘伏这个、会碘伏那个。但你真正下场用就会发现,Agent 能做的事情,其实是非常有限的。它很聪明,能理解你的意图,能写代码,能写文章。但它同时也很无力。它没有手,没有眼睛,没有登录态,没有指纹,没有 Cookie。它需要别人帮它把那些「真实世界」的事情先处理好。
BrowserAct 干的就是这个事。它不是让 Agent 更聪明,而是让 Agent 终于能「进得去」。
有时候会觉得,AI 这波浪潮里,最值得做的不是模型本身,而是模型跟真实世界之间的那层「基础设施」。模型是大脑,基础设施是手脚。光有大脑没有手脚,它就只能活在对话框里。
BrowserAct 就是给 Agent 长了一双能真正伸到浏览器里的手。这双手能不能敲代码、能不能写文章不重要。重要的是,它能登录、能通过验证码、能不被反爬识别。它能进去。能进去,是一切的前提。
前段时间一直有个感觉,AI 这块,最稀缺的不是花活,是基建。能把基建做扎实的人,比会做花活的人值钱多了。
BrowserAct 算是其中一个。
安装和最后的话
最后说一下安装。很简单,在
Claude Code 或者
Cursor 里,把这个项目的 GitHub 链接发给 Agent,让它自己装就行。不用动手。
```
安装 browser-act
skill: https://github.com/browser-act/skills/tree/main/browser-act
```
Agent 会自己跑完整个安装流程,还会顺手验证一下能不能用。
说真的,这个项目是打算长期用下去的。它解决的不是「让 Agent 跑得更快」的问题,而是「让 Agent 跑得进去」的问题。这两个问题,听起来差不多,实际上差了十万八千里。
那天晚上踩完坑之后,最大的感受就是,AI 这玩意,未来一定不是模型在单打独斗,而是模型加一堆基础设施在打配合。谁能把基础设施这一层做扎实,谁就能在 AI 这一波里站得更稳。
好了,今天就聊到这。




