自动语音合成技术如今已经渗透到我们生活的方方面面,从手机里的语音助手到车载导航系统,背后都离不开这项技术的支撑。在整个语音合成链条中,声码器扮演着一个相当关键的角色——它负责把声学特征转换成我们能直接听到的音频信号。Wa veGlow这个模型确实很厉害,实现了并行化的语音生成,但问题也很明显:它的计算量实在太大了,大到本地设备根本扛不住,只能依赖云计算。而一旦上了云端,网络延迟和用户隐私就成了绕不开的坎。
不过,最近来自加州大学伯克利分校的研究人员带来了一款超轻量级的声码器模型SqueezeWa ve,专门为了解决这个计算效率难题。他们在Wa veGlow的基础上,对结构和计算方法做了深度优化,使得计算量直接减少了61到214倍。这个模型小到什么程度呢?哪怕是树莓派这种级别的设备,都能稳稳跑起来,实现实时的语音合成。
一、TTS从云端向边缘
从车载地图到智能音箱,现在越来越多的设备都开始引入语音交互。但想要获得高质量的语音合成体验,背后往往需要复杂的机器学习模型和庞大的云计算资源来支撑。硬件的发展正在改变这个局面——边缘设备的计算能力越来越强,让模型在本地运行成为可能。同时,消费者对数据隐私也愈发敏感,谁都不希望自己的语音数据在云端流转一圈。再加上人们对语音助手的依赖性越来越强,对响应速度的要求自然也水涨船高。为了提供更低延迟的体验,同时摆脱网络质量的制约,本地运行的语音合成模型显然比云端方案更有吸引力。
典型的现代语音合成模型通常由两个核心部分组成:合成器和声码器。合成器负责把文字转换成声学特征,声码器则把这些特征进一步合成为最终的波形输出。目前的高质量语音合成器,无论哪个环节,计算资源的消耗都相当可观。SqueezeWa ve的切入点很明确——就是提升合成器的效率。举个例子,Wa veNet及其变体采用的是自回归方法,每个生成的样本都依赖于前一个,这种串行处理方式让硬件并行加速变得困难。而基于流的Wa veGlow虽然能在一次前向传播中生成大量样本,但代价是巨大的计算量——生成1秒22kHz的语音就需要消耗229G MACs,这远远超出了移动端处理器的承受范围。相比之下,Wa veFlow虽然能在V100显卡上实现超实时性能,但同样不适合在边缘设备上部署。
正是在这个背景下,研究人员提出了SqueezeWa ve。他们重新设计了Wa veGlow的架构,通过重整音频张量、引入深度可分离卷积以及一系列优化措施,使得计算量比原版Wa veGlow大幅缩减。实测下来,在笔记本端就能实现每秒123K到303K样本的生成速度,哪怕是在树莓派3B+上,也能跑出15.6K样本每秒的实时水平。
二、重新审视Wa veGlow的计算复杂度
先来看看Wa veGlow的计算瓶颈到底在哪里。与直接进行卷积操作不同,Wa veGlow首先会把邻近的样本聚类,构建多通道输入。其中L代表时域维度的长度,Cg则是每个时间步上聚类组合的样本数量。波形中的样本总数是固定的。随后,波形会经过一系列双边映射的转换,每个映射都利用输入得到输出。具体来说,输入信号先被可逆的逐点卷积处理,然后沿通道拆分为两部分。其中一部分会被用来计算仿射耦合系数,另一部分则参与后续的运算。整个过程里还嵌套了一个类似Wa veNet的函数,用于编码音频的梅尔谱。最终,仿射变换层通过逐元素相乘等操作计算出结果,并在通道方向上组合输出。
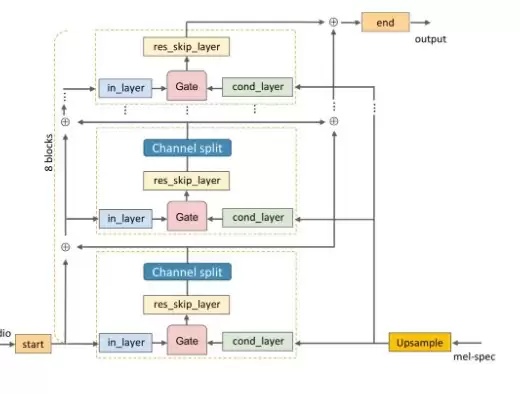
Wa veGlow的计算量主要来自其中的WN函数。从计算流程来看,输入首先经过逐点卷积,通道数从一个小数目扩张到256维。接着,一个卷积核为3的一维膨胀卷积会继续处理结果,同时梅尔谱也被馈入网络。由于梅尔谱的时域长度远小于波形长度,还需要对它进行上采样才能匹配维度。
随后,in_layer和cond_layer的输出按照Wa veNet的方式通过门函数合并,传到res_skip_layer。这个输出的长度是L=2000,通道数为512,接着会被拆分为两部分。整个结构重复八次,最后的res_skip_layer输出与end逐点卷积,计算出转换因子。
最终,通道从512被压缩到8。在整个计算过程中,in_layer占据了47%的计算量,cond_layer占了39%,res_skip_layer则是14%。正是基于这样的分析,研究人员决定对网络结构进行改进。
三、SqueezeWa ve的改进措施
对Wa veGlow的计算复杂度进行拆解后,问题变得很清晰:最大的计算负担来自输入音频波形的形状——具体来说就是长度。Wa veGlow的输出维度是L=2000、Cg=8,这从三个层面拉高了计算复杂度。首先,Wa veGlow使用的是一维卷积,计算复杂度会随L线性增长。其次,为了匹配梅尔谱的时域分辨率,需要上采样,但上采样本质上只是对现有样本做简单插值,意味着in_layer中相当一部分计算其实是冗余的。此外,在WN函数中,8通道的输入被映射到256到512维的高维空间,最后又被压缩回8通道,中间维度的信息不可避免会出现损失。
针对这些问题,研究人员给出的方案是:把输入音频变形为更小的时域长度和更多的通道数,同时保持WN函数中的通道尺寸不变。具体来说有两种方案:当L=64时,时域长度与梅尔谱完全一致,无需上采样;当L=128时,梅尔谱只需要做最近邻采样,进一步减少了cond_layer的计算量。
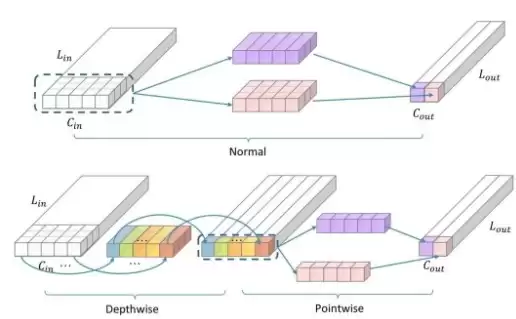
除此之外,研究人员还用深度可分离卷积替代了in_layer中的一维卷积来处理音频信号。一维卷积的输入输出维度变换,计算量的量级是MACs,而深度可分离卷积能将这个量级大幅缩小。当卷积核K=3、输出通道Cout=512时,这种方法能减少近三倍的计算量。
还有一个改进点在于,由于时域长度缩短,已经不需要膨胀卷积来增加感受野,换成常规卷积更适合硬件计算。同时,res_skip_layer的两路输出分支被合并,进一步减少了最终的输出通道数。下图可以更直观地看到SqueezeWa ve的改进效果。
四、实验结果
为了验证模型的实际表现,研究人员将SqueezeWa ve与Wa veGlow以及基准模型进行了对比。上表中的SW-128L代表的是L=128的模型版本。结果显示,SqueezeWa ve系列模型的计算量相较Wa veGlow大幅下降,但生成的语音质量依然能维持在较高水准。
为了检验在边缘设备上的性能,研究团队还对比了MacBook Pro和树莓派上的测试数据。结果表明,即使在树莓派这样的平台上,SqueezeWa ve也能实现每秒5.2K到21K样本的生成速度。其中,SW128S版本已经能够实时生成高质量的音频结果。