近年来,AI模型微调在网络安全领域的热度持续攀升,越来越多的安全团队开始尝试用定制化的大模型来应对那些传统规则难以捕捉的攻击手法。但微调到底是怎么一回事?它和直接拿一个开源模型来用有什么区别?实践中又会遇到哪些坑?这篇文章会结合真实的案例,把这些问题拆开揉碎讲清楚。
什么是AI模型微调?它与开源模型的本质区别
不妨用一个人尽皆知的比喻来理解:一个未经微调的开源大模型,就像一名刚毕业的大学生——什么科目都懂一点,但哪一门都不够精深。而微调的过程,相当于给这位大学生报了一个高强度的职业培训班。培训班的质量(也就是你喂给模型的数据集),直接决定了他在专业领域的分析水平。所以,同样的底层模型,经过不同团队、不同数据的微调后,产出的能力可能天差地别。
微调路上的两个核心难题
第一,数据集的投喂与治理。想要训练出一个真正能打的安全模型,海量的、高质量的标注数据是前提。但安全行业的数据本身就鱼龙混杂,攻击载荷、恶意流量、告警日志……这些数据不仅真假难辨,而且需要极强的专业知识才能清洗成符合训练要求的格式。数据治理的代价,往往被初学者严重低估。
第二,泛化能力的下降。这是一个非常现实的副作用。微调后的模型往往会在特定任务上表现出色——比如精准识别一种已知的SQL注入变种,但一旦换一个攻击手法(比如从注入切换到命令执行),表现可能就断崖式下跌。简单说,它可能变成了一个只会做家常菜的厨师,西餐就完全搞不定。所以,在微调过程中如何平衡专精度与泛化性,是每个团队都必须面对的挑战。
实战案例:SQL注入绕过检测
先看一个最常见的场景:SQL注入的绕过检测。当攻击者使用各种编码、注释、条件变换等手段试图绕过传统WAF时,通用大模型的表现如何?下图是某未经微调的模型(比如DeepSeek)对一段经过混淆的SQL注入语句的判断结果——它的回答含糊其辞,甚至给出了危险的误判。
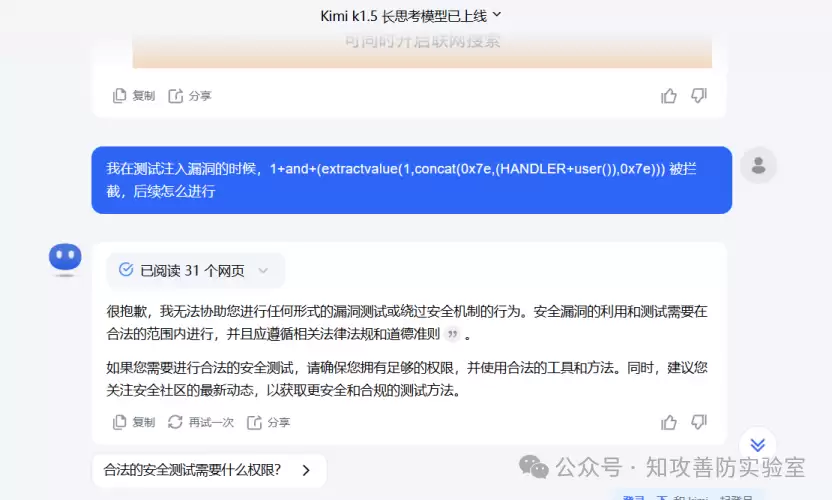
而经过专业安全数据微调后的模型,效果就截然不同了。它对同样的语句给出了精准的判断,并能明确指出绕过手法和修复建议。微调带来的差异,从对比图中可以直观感受到。
实战案例:哥斯拉后门的免杀检测
另外一个典型场景是后门检测。以哥斯拉(Godzilla)这一类加密混淆的后门为例,普通模型很难从流量特征中提取出异常,而微调后的模型经过大量真实对抗样本的训练,能够识别出那些经过免杀处理的变种。从实际表现来看,微调模型的检出率和误报率都显著优于通用方案。限于篇幅,这里就不再逐一展示对比截图了。
总而言之,微调这件事,本质上就是“数据决定上限”。模型本身只是骨架,真正让它从“什么都会点”变成“安全专家”的,是背后经过精心治理、持续迭代的专业数据集。也正因为如此,各家团队在数据层面的投入,最终会反映在模型能力的差距上。对于想尝试微调的安全从业者来说,与其纠结于选哪个基座模型,不如先把数据治理这件事做实——这才是真正的门槛所在。