先梳理几个核心观点。Prompt工程这一领域讨论已久,大家心里都清楚:要撰写一条高质量的提示词,尤其是针对复杂任务的提示指令,远非表面那般简单。手动调整参数、反复测试验证、不断迭代优化,会耗费大量时间与精力;并且一旦切换领域或任务类型,先前积累的经验往往会大打折扣。
那么,是否存在一种自动化方法,能够替代人工完成提示词优化,甚至生成效果超越人类?微软最新推出的PromptWizard框架,为此提供了一个令人惊艳的解决方案。
PromptWizard框架详解
简而言之,PromptWizard是一套全自动的离散提示优化框架。它的核心机制十分独特——自我演化、自我适应。它并非套用固定模板,而是借助反馈驱动的批评与合成过程,在探索与利用之间找到最佳平衡点。
如何理解呢?该框架能够自动生成一批提示指令,自行评估效果,然后根据成功与失败的案例进行批评、修改,最终合成出更优版本。这一循环迭代持续进行,直到生成一条针对特定任务、既人类可读又高效精准的提示词。
从测试数据来看,该框架在45个任务上均表现亮眼,即使在训练数据有限、使用小参数模型或不同架构模型的情况下,依然能取得不错的效果。这意味着它不挑剔环境,具备极强的通用性。
PromptWizard解决的痛点
那么,它具体解决了哪些实际难题?
-
手动提示工程的局限性
手动编写提示词极为耗时,且不同领域任务对风格、格式的要求差异巨大,很难找到万能模板。PromptWizard的做法是让LLM自行生成、批评、提炼自身提示与示例,通过迭代反馈不断逼近最优方案。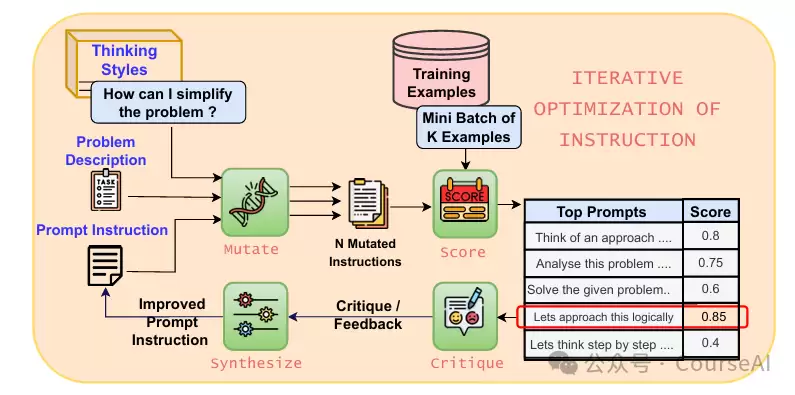
-
现有优化策略的不足
以往的连续或离散提示优化方法,要么需要额外训练神经网络,成本高昂;要么在提示空间搜索时纯靠随机,缺乏反馈机制,效率低下。PromptWizard引入反馈驱动的批评与合成机制,显著改善了随机性与低效问题。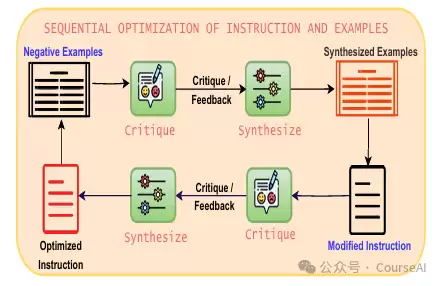
-
特定任务提示的生成
每个任务都有其独特的“语言”,通用模板往往失效。PromptWizard通过迭代细化提示指令与上下文示例,最终生成的提示高度定制化,不仅提升了模型性能,也增强了可解释性。
PromptWizard架构与流程
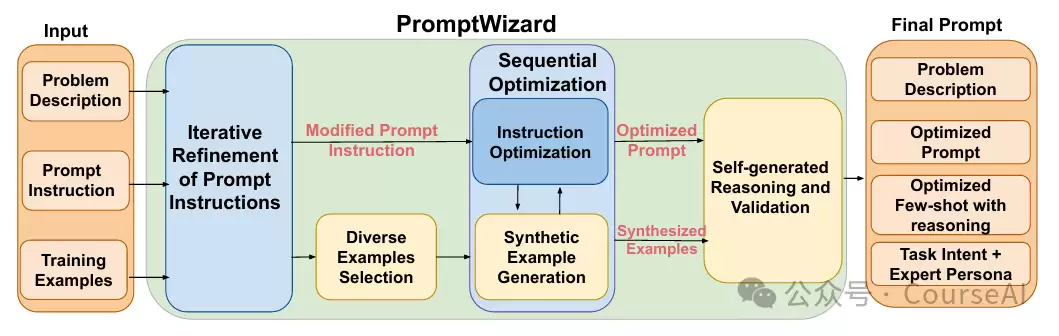
纵观整个流程,可以将其理解为一个自循环的优化引擎:
-
问题描述与初始提示指令
一切始于接收问题描述与一个初始提示。例如,对于数学题求解任务,初始提示可能是“让我们逐步思考来找到解决方案”。 -
生成指令变体
基于初始提示,系统利用预定义的认知启发式或思考风格,生成大量提示变体。这些变体从不同角度描述同一问题,确保指令的多样性。 -
性能评估
有了变体后,需要打分。PromptWizard采用评分机制,在一小批训练样本上测试每个变体的表现。评分标准可以是传统的F1分数,也可以是LLM作为裁判。 -
反馈与提炼
选出当前最优版本后,关键环节到来:批评组件会对该版本进行审查,分析其成功与失败之处,并给出具体、有针对性的反馈。 -
合成与优化
合成组件根据反馈重新表述并增强指令,生成更贴合任务的优化版本。此过程中,反馈质量直接决定优化方向。 -
识别多样化示例
仅优化指令还不够,PromptWizard还会从数据集中抽取候选示例,通过评分机制评估当前提示在这些示例上的表现,将其分为正面与负面两类,从而找到一组既有效又多样化的示例。 -
顺序优化
大多数现有方法只优化提示指令或少数示例,而PromptWizard采用顺序优化策略,同步对指令与示例进行批评与合成,从而整体提升提示质量与任务性能。 -
自生成推理与验证
优化完指令与示例后,PromptWizard整合链式思考推理。它为每个选定示例自动生成详细的推理链条,并让LLM自行验证这些链条的连贯性与相关性。 -
任务意图与专家角色整合
最后一步,将任务意图与专家角色直接嵌入提示中,确保模型在执行特定领域任务时始终保持相关思维框架,避免偏离到泛化回答。
三种方式提升Prompt质量
在实际使用中,PromptWizard还提供三种不同的优化路径,用户可根据自身数据情况灵活选择:
-
无训练数据,也不需要上下文示例
直接让框架基于问题描述生成并优化提示。 -
无训练数据,但需要上下文示例
分两步走:先通过特定策略生成合成数据,再利用这些合成数据优化提示指令与示例。 -
有训练数据,且需要上下文示例
让模型自行生成、评价、改进提示词及示例,通过持续反馈循环提升最终输出质量。
归根结底,PromptWizard不仅仅是一个自动化工具。它代表了一种全新思路——让LLM自己成为提示工程师,通过自我批评与自我迭代,持续逼近最优解。一旦这一机制规模化,对AI应用开发的效率提升将极为显著。