国产AI圈又炸了——一个仅有8B参数的模型,居然能在iPad上流畅运行,多模态能力直接对标GPT-4o。更让人激动的是,它还是全球首个开源的8B级多模态模型。没错,说的就是面壁智能最新发布的MiniCPM-o 2.6。
为什么这么轰动?因为8B的参数量,放在大模型领域只能算“小身板”,但它却在看、听、说等多种模态上,跟GPT-4o这样的巨无霸正面硬刚。而且,它真的能在iPad上跑起来——这可不是噱头,是实实在在的开源项目。
从网友们转发的实测来看,效果也确实有点意思。比如,MiniCPM-o 2.6可以直接“盲听”声音,知道你在干什么——翻书声、咳嗽声、倒水声、敲门声,声声精准识别。
不止听觉,在看和说 方面,它同样有两把刷子。例如,你可以在iPad上让它“睁眼”玩三仙归洞,它还能记住所有牌被翻过去前的图案:
方面,它同样有两把刷子。例如,你可以在iPad上让它“睁眼”玩三仙归洞,它还能记住所有牌被翻过去前的图案:
在说方面,MiniCPM-o 2.6现在更自然了,不仅能扮演新闻主播、学生等各种角色,甚至连咖喱味的英文(印度口音)也信手拈来。实时打断更是不在话下:
网友们看罢连呼“Awesome”,有人甚至感叹:超酷的,我的iPad像有了第二个大脑。
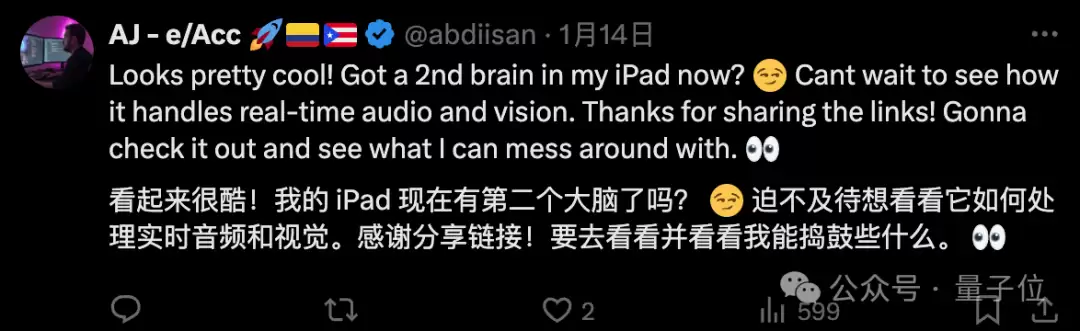
当然,不只是效果惊艳。面壁智能同步晒出了看、听、说等多模态能力在各项评测榜单的成绩。从分数上看,仅8B的MiniCPM-o 2.6整体能力已经能跟GPT-4o比肩,甚至在很多细分项目中实现了超越:
用面壁官方的话来说,MiniCPM-o 2.6已经是开源社区最强语音通用模型、最强端侧视觉通用模型,以及最强实时流式多模态模型。
那么,实际体验到底有多丝滑?
来一波实测
先看视力水平。我们演示了一个简单操作——从“这是一张照片”这句话里删掉两个字,看看MiniCPM-o 2.6能不能看出来。它精准地回答:“你刚刚删除了‘照片’两个字。”
再给它看一段《黑神话:悟空》的经典片段,问它那个游戏叫什么。它又答对了:“你展示的游戏是《黑神话:悟空》。”
之所以能做到这么精准,根据面壁智能的介绍,是因为MiniCPM-o 2.6已经实现了真·看视频。它并不是此前的“照片大模型”——那种在用户提问之后才开始对视频静态图片抽帧、无法回答提问之前视频内容的模型。真·看视频的大模型能持续对实时视频和音频建模,这就更像人类的眼睛了。
在视觉方面,除了视频,对于图片的理解和推理,MiniCPM-o 2.6的能力同样更上一层楼。比如让它帮忙指导调整自行车座椅,从找到位置到挑选合适工具,它都能正确get用户意图。

它也能化身学习搭子,帮忙解题。

这些表现都基于MiniCPM-o 2.6强大的OCR(光学字符识别)能力。官方声称,它可以处理任意宽高比,以及高达180万像素的图像(例如1344x1344)。比如直接对准iPad,它就能识别屏幕上的内容。
在听方面,前面已经展示了不少案例,这里不再重复。继续深入实测说的能力。比如让它用四川话教煮火锅:
嗯,川味十足。可见,MiniCPM-o 2.6在交互上,是把看、听、说等模式拿捏得相当到位。
那么接下来的问题是:
怎么做到的?
概括而言,面壁智能一直专注于面向边端算力场景进行极致优化,核心思路是让模型在手机、iPad这样的端侧设备上更快、更好、更省地跑起来。

MiniCPM-o 2.6采用的模型架构,显然也贯彻了这一目标。之所以看听说全能,关键之一在于下面的端到端全模态架构——它能将文本、图像、音频等不同类型数据的编码和解码模块,通过端到端方式连接起来训练。这样模型就不是孤立地处理每种模态,而是综合考虑它们之间的关联和交互,充分调用多模态知识。并且,整个过程完全使用交叉熵(CE)损失(无辅助/中间损失函数)进行端到端训练。
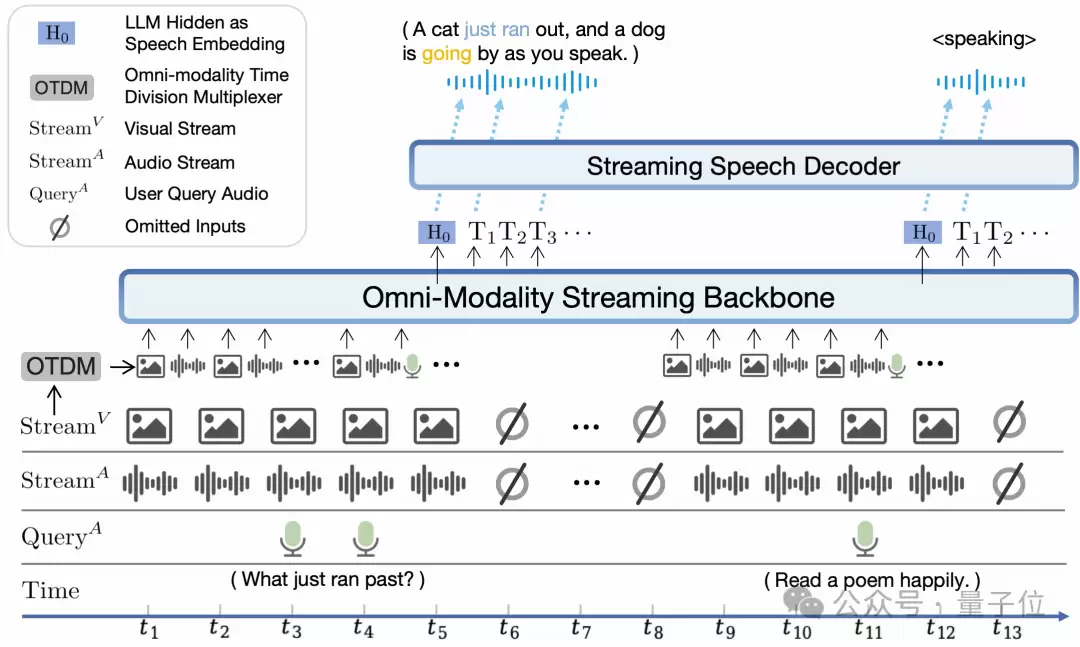
此外,为了适应流式输入输出(即实时、低延迟),不必像传统那样等所有数据都准备好再处理,面壁团队做了两方面工作:一是上手改造离线编/解码器模块,将其变成更适于流式输入/输出的在线模块;二是针对大语言模型的基座,设计了时分复用的全模态流式信息处理机制(Omni-modality Time Division Multiplexer,OTDM)。
尤其是后者,它将同时并行输入的多模态(如视频流和音频流)按照时间顺序拆分、重组,形成一个个小的周期性时间片序列。这样一来,在一个时间片内,可以先处理一小段视觉信息(如几帧图像),然后处理一小段音频信息(如几毫秒的音频波形),再将它们组合起来,从而避免信息混乱。
接下来,经OTDM处理后的多模态信息片段,继续按时间顺序传递给全模态流式骨干网络(Omni-Modality Streaming Backbone)。作为架构的核心,它负责提取不同类型数据的特征(类似关键帧、关键音频等),再融合起来。过程中,大语言模型隐藏层(图中H0)被用作语音嵌入,以更好地输出语音内容。
当然,最终输出语音还要靠最后的流式语音解码器(Streaming Speech Decoder),它将接收到的信息转化为语音形式。值得一提的是,面壁团队还设置了可配置的声音方案:不仅设计了新的多模态系统提示,可直接通过文字或语音样例生成或选择声音风格,还支持端到端声音克隆和音色创建等高级能力。
总体来看,这一架构实现了多模态流式处理+声音的自由选择,无论面对哪种数据,都能实现高效、低延迟交互,从而成为听说看“六边形战士”。
从更大层面来说,作为“以小博大”的老手,MiniCPM-o 2.6仅仅是面壁智能更大计划的一环。面壁智能2018年脱胎于清华NLP实验室,是国内最早进行大模型研究的一批人,逐渐聚焦于更高效的端侧模型之路。CEO李大海曾表示:“站在大模型时代,我们都在提‘AI原生应用’;这个时代需要的全新操作系统,就是AI原生应用+AI原生硬件。而其中的AI原生硬件,只要能在端侧运行大模型就是原生硬件。因此,端侧大模型格外重要。”
想在手机、PC这样的端侧丝滑跑起来,大模型必须同时满足两个条件:要小,还要性能高效。早在2020年,面壁就作为“悟道”大模型首发主力阵容,发布了全球第一个20亿级中文开源大模型CPM 1,并持续参与之后的CPM 2和CPM 3。其中,4B大小的CPM 3已能和GPT-3.5掰手腕。后来走红全网的“小钢炮”系列也延续了这一路线——仅2B大小的MiniCPM,在多项主流中英测评中超越“以小博大”的标杆Mistral-7B,甚至越级比肩Llama2-13B、MPT-30B、Falcon 40B等模型,且价格极低(1元=1700000 tokens,成本仅为Mistral-Medium百分之一)。
过去一年,他们陆续推出了一系列“以小博大”的产品。就在刚结束的CES上,面壁小钢炮MiniCPM系列也亮相了:一个是去年9月发布的MiniCPM 3.0文本模型,仅4B,代码、数学等能力达到GPT-3.5水平,支持无限长文本;另一个是去年8月发布的MiniCPM-V 2.6多模态模型,仅8B,据当时官方介绍,它首次将超清OCR识图、实时视频理解等能力集成到端侧,也首次在端侧达到单图、多图、视频理解等多模态核心能力全面超越GPT-4V。
而这一次的MiniCPM-o 2.6,更是加上了多模态实时语音交互能力,离人人可用的端侧模型更近了。当然,这也极大便利了视障人士友好出行——真实的出行环境异常嘈杂,而能部署在移动设备的端侧模型,好处恰在于不依赖网络就能本地运行(比如下面的识别红绿灯案例)。
由于能在弱网断网场景中正常工作,面壁端侧模型拥有了更多应用场景,也适合部署在智能眼镜等头戴式设备上。更重要的是,面壁将这些端侧模型完全开源了。
回顾过去一年大模型的发展,国产开源力量表现亮眼。从大众知名度和开源情况来看,DeepSeek、阿里Qwen,以及本次的面壁智能,隐&隐已有“中国大模型开源三剑客”之势。横空出世的DeepSeek-v3,以1/11算力训练出超过Llama 3的开源模型,震撼了整个AI圈;阿里Qwen更是隔一两个月就刷新一次能力边界;而面壁小钢炮MiniCPM系列广受开源社区喜爱,是2024年Hugging Face下载量最高的国产模型之一。在开源这件事上,面壁智能一直很活跃,也收获了不少好评。