在AI领域,小型模型能不能逆袭?伯克利团队最近给出了一个漂亮的答案。他们把1.5B参数的小模型,通过强化学习一调教,直接超越了OpenAI的o1-preview,在AIME 2024这类数学竞赛上展现出了惊人的推理能力。这件事在圈内引起了不小的震动——意味着在特定领域,小模型完全可以用更聪明的训练方法,打出比大模型还漂亮的成绩。
突破性成就:1.5B小模型挑战大模型
很长一段时间,AI界有个默认共识:要在数学推理这类复杂任务上出成绩,必须堆参数、堆算力。但伯克利团队的研究直接打破了这种惯性思维。他们没走寻常路,而是依靠精巧的训练方法和高质量数学数据集,在1.5B参数的小模型上应用强化学习,硬是把推理能力拉到了一个前所未有的高度——超越OpenAI的o1-preview。这告诉我们一个道理:并不是越大越好,在特定赛道上,小模型只要用对方法,潜力同样不可小觑。
DeepScaleR的创新训练方法:循序渐进,逐步突破
DeepScaleR的成功,关键在于训练方法上的破局。它放弃了传统大规模预训练模型那种“一口气吃成胖子”的思路,而是采用渐进式强化学习策略,像搭积木一样,一步一步引导模型把推理能力建起来。
1. 迭代式上下文扩展:从短到长,逐步加深推理深度
这个策略很有意思。研究团队没有直接训练模型处理超长上下文,而是从较短的上下文开始——先是8K字符长度的题目,好比让高中生先做基础作业;等模型能力上来了,再升级到16K字符(挑战性更高的题目);最后才推进到24K字符。这种逐步扩展的方法,有效避免了过早引入复杂性带来的训练困难。核心逻辑很简单:让模型先掌握简单的推理过程,再通过扩展上下文来挑战更复杂的问题。这就好比学数学,得从加减乘除开始,再慢慢接触微积分——模型通过这样的渐进训练,自然就构建起了自己的推理路径,不会因为“信息过载”而消化不良。
2. 强化学习奖励机制:纯粹的正确性驱动
DeepScaleR的奖励机制非常简洁——1分奖励正确答案,0分奖励错误答案,没有中间地带。这种二进制奖惩机制,避免了传统强化学习中“过程奖励”可能带来的冗余和误导。在数学推理这个场景下,最终答案正确与否才是硬道理,中间步骤再花哨,如果结果错了也没用。所以这种纯粹的结果奖励模型(ORM),反而更契合数学的严谨性:只有对与错,没有模糊地带。说白了,模型能腾出所有精力去追求那个最终答案,而不是纠结于推理过程的花样。
3. 小模型大突破:高效利用计算资源
DeepScaleR的参数只有1.5B,但训练效率高得惊人。整个训练只用了3,800 A100 GPU小时,折算下来成本约4,500美元。对比传统大模型动辄数百万美元的训练开销,这简直是白菜价。高效率的来源有两个:一是强化学习本身的高效利用,二是迭代式上下文扩展让训练过程更聚焦于推理能力本身,而不是堆砌算力。这再次证明,只要有创新的方法,小模型也能用很少的资源做出大成绩。
卓越性能:超越o1-preview,挑战数学竞赛
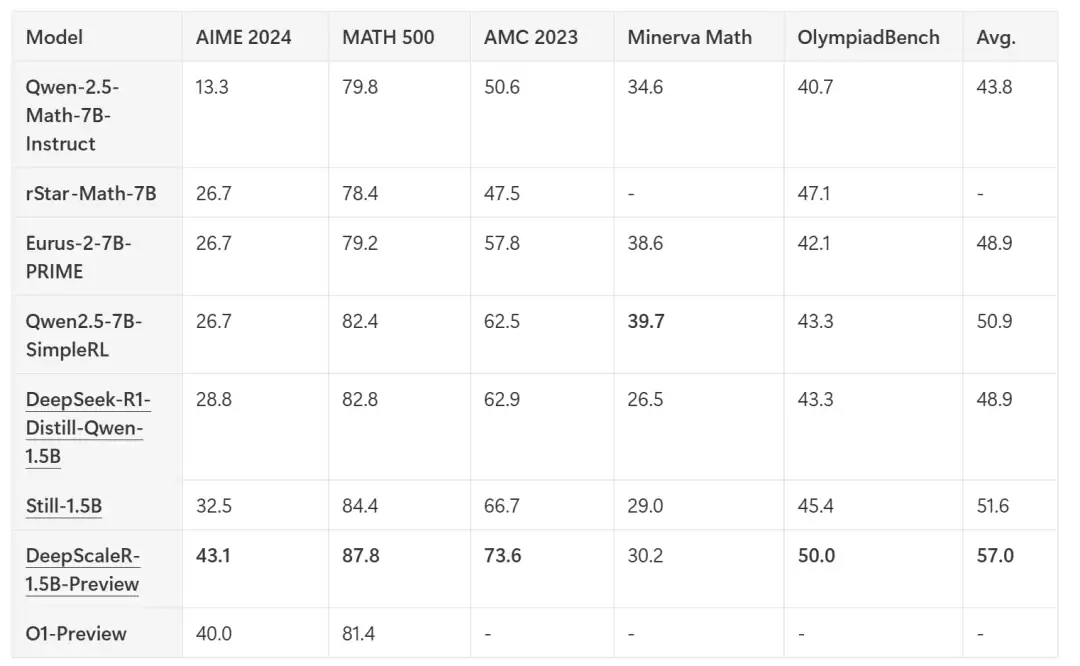
为了验证实力,研究团队把DeepScaleR和多个主流模型摆了擂台,包括基础的DeepSeek-R1-Distilled-Qwen-1.5B、学术界的rSTAR-Math-7B、Eurus-2-7B-PRIME以及Qwen2.5-7B-SimpleRL等。
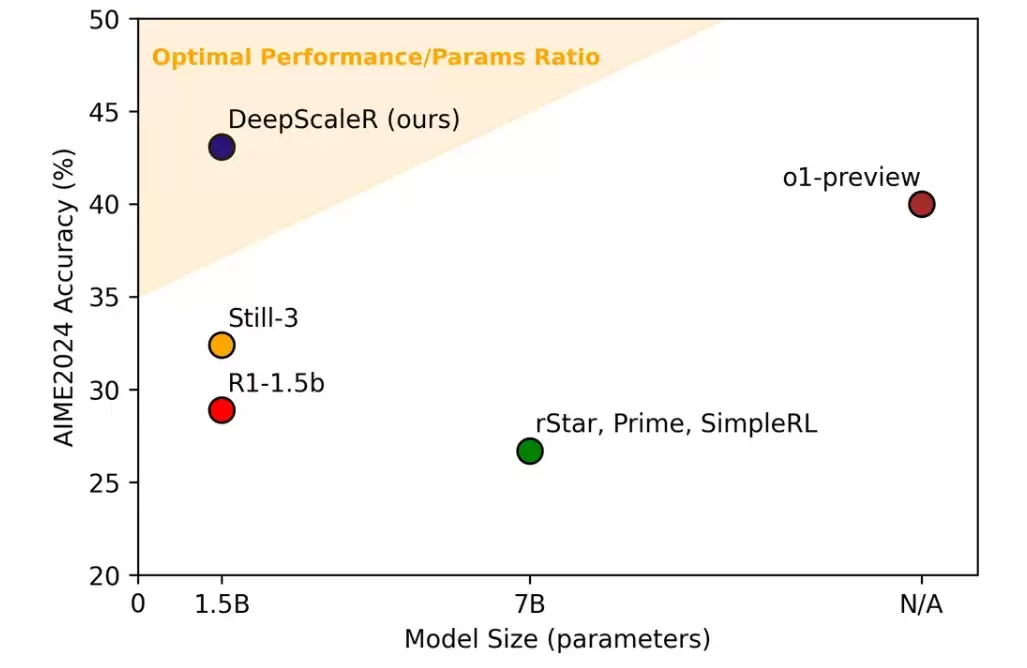
对比结果相当亮眼。DeepScaleR-1.5B-Preview在AIME 2024、MATH 500和AMC 2023等多个数学竞赛测试中全面开花。尤其在AIME 2024上,它的Pass@1准确率达到43.1%,比基础模型提升了14.4%,直接超越了OpenAI的o1-preview。而综合平均性能,DeepScaleR拿到57.0%,远远甩开其他基准模型。在MATH 500上它拿了87.8%,在AMC 2023上也拿到73.6%——这种表现在小模型里,算得上惊艳了。