在智能车控制这一热门领域,如何让车辆既快速又稳定地运行始终是个难题。最近,Michal Nand 在 HACKADAY.IO 上分享了一套颇具创意的方案——利用卷积神经网络辅助巡线智能车的控制。他不仅清晰阐述了核心思路,还对神经网络的结构设计、训练方法以及在资源受限微控制器上的部署细节都进行了详尽讲解,值得深入拆解。
简介
智能车的任务并不复杂:在平面赛道上,沿彩色引导线(通常是黑色)从起点运行至终点,再折返。赛道某段还放置了一块砖头作为障碍物。传统方案要么依赖PID调参,要么靠逻辑判断,但作者另辟蹊径——大部分控制算法仍使用PID和逻辑判断,而核心的赛道类型识别则交由卷积神经网络。车模运行过程中,传感器采集二维路面数据,CNN负责对赛道类型进行分类,然后根据路况动态调整车速:直线加速、弯道减速,从而在保障稳定性的前提下提升速度。

▲ 利用神经网络控制的巡线智能车
机械结构
1. 硬件构成
智能车的硬件选型相当务实,核心配置如下:
- 嵌入式控制器:STM32F303,Cortex M4F 72MHz
- 电机驱动器:TI DRV8834 低电压双相步进电机驱动器
- 电机:Pololu HP电机,减速齿轮箱 1:30,带磁编码器
- 轮胎:Pololu 28mm,高黏着力
- 惯性导航器件:LSM6DS0
- 巡线传感器:8个绿光(540nm)光电传感器,3个红外障碍传感器
- 电源:180mAh,LiPol 2S
- 编程接口:USB,通过Bootloader下载程序

▲ 智能车的硬件构成
2. 组成器件
| 序号 | 种类 | 数量 | 型号 |
|---|---|---|---|
| 1 | MCU | 1 | STM32F303 72MHz ARM Cortex M4F |
| 2 | 电机驱动 | 1 | TI DRV8834 |
| 3 | 电机 | 2 | 1:30 Pololu,带磁编码器 |
| 4 | 轮胎 | 2 | Pololu 直径28mm |
| 5 | 巡线传感器 | 8 | 540nm光电传感器+白色补光LED |
| 6 | 红外传感器 | 3 | 表贴红外传感器+红外LED |
| 7 | 惯性传感器 | 1 | IMU LSM6DS0 陀螺仪+加速度计 |
控制算法
1. 控制调试界面
“磨刀不误砍柴工”。作者基于OpenGL开发了一套调试软件,通过界面可以实时查看:八个巡线光电传感器的原始数值、电机状态(速度、编码器值)、惯性传感器数据、神经网络分类处理过程,以及通过串口获得的原始数据。这种可视化调试手段,对理解卷积神经网络在真实场景中的行为非常有帮助。
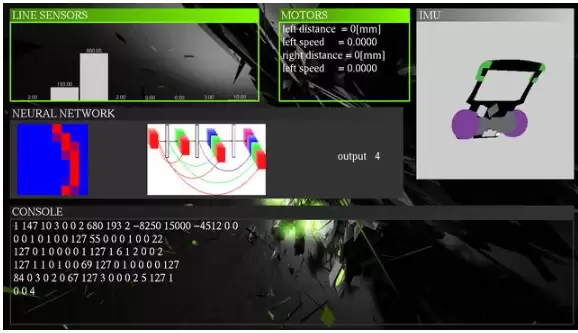
▲ 编程调试界面
2. 智能车控制软件要点
控制软件的主要功能与指标可以概括为:
- 通过二次插值算法,利用8个光电传感器获得更精确的引导线位置
- 主控制频率:200Hz
- 方向控制器:采用PD控制
- 电机速度控制:采用双串级PID
- 赛道引导线预测:直线加速,弯道减速,通过深度神经网络识别赛道类型
- 软件编程语言:C++
- 神经网络训练:使用GPU加速
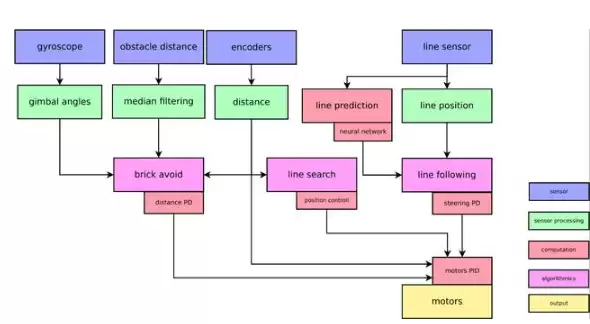
▲ 智能车的软件控制框架
3. 神经网络用于引导线的预测
作者利用深度卷积神经网络完成对引导线的预测与分类,核心思路是根据引导线类型调整运行速度:直线时快速通过,曲线时减速慢行。这里采用了DenseNet(稠密连接卷积神经网络)结构。
输入数据是一个8×8的传感器数据矩阵:8个光电传感器排成一条直线,连续采集前后相邻8条数据,构成8×8的二维矩阵。输出是五种曲线类型:两种右拐、两种左拐、一种直线。
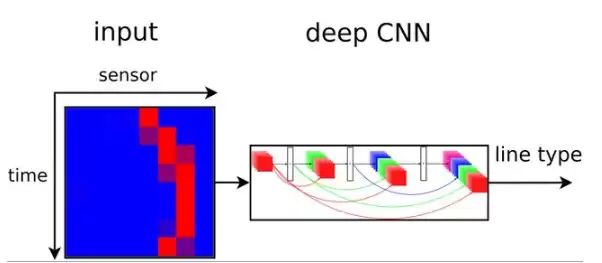
▲ 神经网络结构图
训练数据采用人工生成的仿真数据,样本量:训练集25000个,测试集5000个。数据增强手段包括Luma噪声和White噪声。
▲ 输入训练数据样本
由于最终要部署在STM32F303这样的单片机中,作者在网络的鲁棒性与运行速度之间做了权衡。网络运行频率也是200Hz,意味着单次推理时间必须小于5毫秒。为此,作者选择了DenseNet,它相比纯卷积神经网络使用更少的卷积核,从而提高了计算效率。
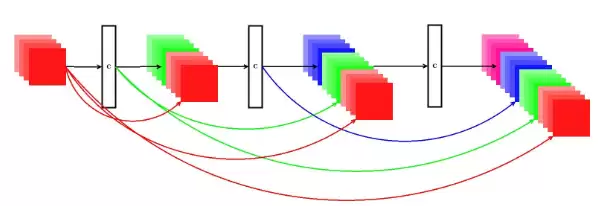
▲ 神经网络的结构
最终,网络在测试集上的识别准确率达到了95%。
4. 网络最终结构
CNN的具体参数如下表所示:
| 网络层 | 网络层类型 | 输入特征图张量尺寸 |
|---|---|---|
| 1 | 卷积 3×3×4 | 8×8×1 |
| 2 | MAX POOLING 2×2 | 8×8×4 |
| 3 | 稠密卷积 3×3×4 | 4×4×4 |
| 4 | 稠密卷积 3×3×4 | 4×4×8 |
| 5 | 全连接层 输出5 | 4×4×12 |

▲ 神经网络的各层结构参数
5. 将网络部署到单片机中
为了让神经网络在32位单片机上跑起来,作者做了三方面的改造:首先,将所有浮点数改为int8_t;其次,将权重参数缩放到8bit范围;最后,使用双缓存技巧节省内存,共用两个内存缓存来计算所有层的数据。这样一来,原本需要大量浮点运算和内存占用的网络,就能在资源极其有限的嵌入式环境中流畅运行。

▲ 神经网络部署到单片机的流程示意图