本地运行大型语言模型这件事,曾经被许多人视为技术门槛较高的领域,不过现在情况正在发生变化。Ollama这个开源工具的出现,让本地部署LLM(比如deepseek-r1、qwen2.5这类模型)变得格外便捷。它把模型下载、部署、管理这一整条链路,都压缩成了几个简单的操作,不需要你再去折腾复杂的配置环境。这意味着什么?意味着普通开发者、甚至有一定动手能力的爱好者,都能在自家电脑上轻松体验和开发基于大模型的应用了。
先来了解下它的核心价值:
1. 简化了本地部署大型语言模型的整个流程
2. 提供了清晰且安全的安装方法
3. 对硬件配置有相应要求,不能忽视安全问题
Ollama是什么,它为什么重要
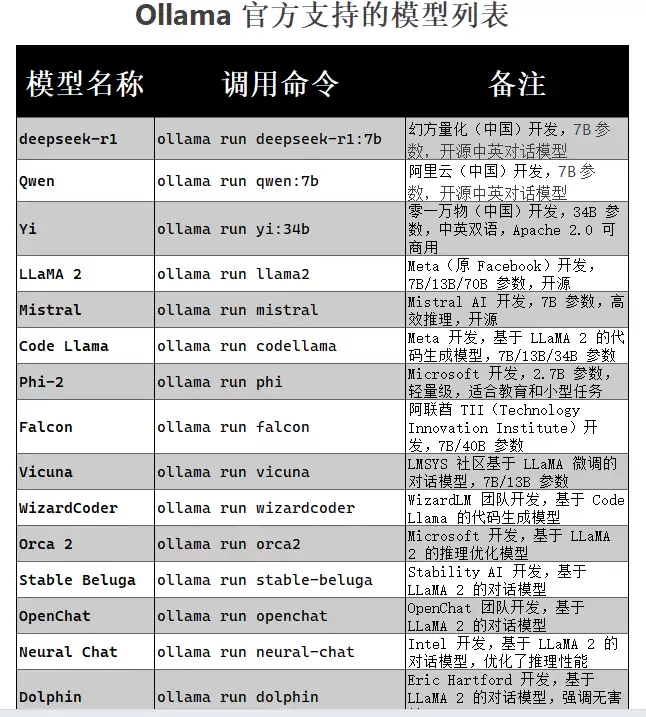
Ollama 是一个专注于本地高效运行大模型的开源工具。它把这些模型的下载、部署、管理全部抽象成简单的命令,让你不必为环境依赖焦头烂额。从ollama官网上能看到当前支持的所有模型列表,下面这张图就是它的模型展示页:
按部就班:Windows与Linux的安装
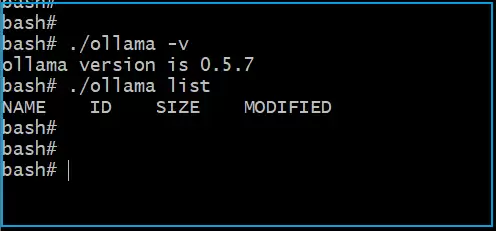
装机这件事,不同系统有不同路数。Windows环境最简单,官网下载安装包,一路Next就能搞定。Linux用户则需要通过命令行动手,过程也很直接:
$ curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
$ sudo tar -C /usr -xzf ollama-linux-amd64.tgz
$ ollama serve
$ ollama -v
当然,如果你不想手动一步步操作,也可以直接用官方提供的自动化脚本。不过在运行之前,最好先看一眼脚本里到底要做些什么,毕竟这是自己机器,安全总得放在第一位:
$ curl -fsSL https://ollama.com/install.sh -o ollama-install.sh
如果实在懒得研读脚本代码,不妨把脚本内容发给AI助手(比如deepseek),让大模型帮你梳理出关键步骤。以下就是该安装脚本的主要操作汇总:

自动化安装的额外处理:显卡驱动
手工安装和自动安装之间一个关键差异就在这里:自动安装脚本会替你处理显卡驱动的检测与配置。它涉及到 lsmod、modprobe 这些Linux内核模块相关的命令,所以如果你操作的是一台与别人共享的服务器,务必谨慎行事。

另外需要注意,安装完成后,Ollama会默认开启11434端口。如果是公网GPU服务器,随便开放端口可能带来入侵风险,这个隐患不能忽视。
摸清家底:检查服务器硬件配置
在正式运行模型之前,先确认下机器的硬件底子是什么。以下是一组常用的检测命令:
$ cat /proc/cpuinfo && free -g && nvidia-smi
同样,如果不想逐行分析这些输出,让AI助手(比如kimi)帮你汇总配置信息也是一个高效选择:

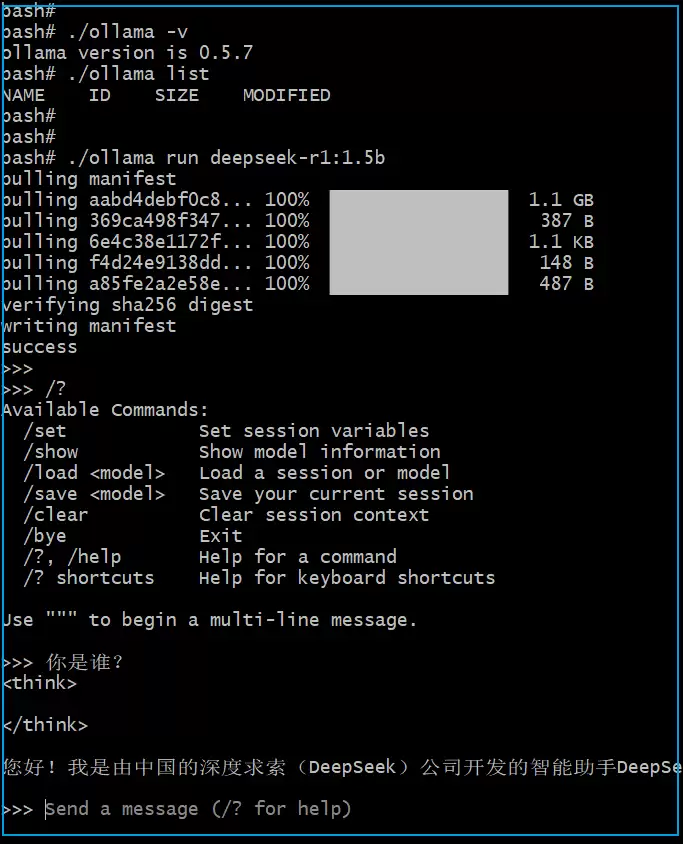
初次体验:跑一个1.5b的小模型
环境搭好之后,可以先找一个轻量模型练练手。直接运行以下几个命令就能体验deekseek-r1的1.5b版本:
./ollama run deepseek-r1:1.5b
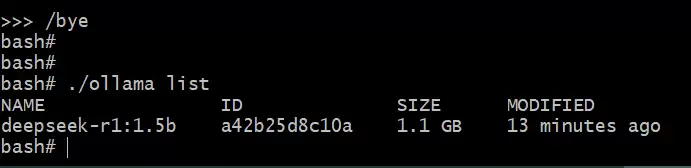
这个模型大小也就1.1GB左右,对硬件要求不高:
需要澄清一点,默认安装的Ollama服务本身并不支持联网搜索。如果确实需要查询互联网上的即时信息,当前最便捷的办法还是使用AI公司提供的线上服务。比如你可以问deepseek-r1模型的大小和运行需求,或者通过kimi发出疑问:
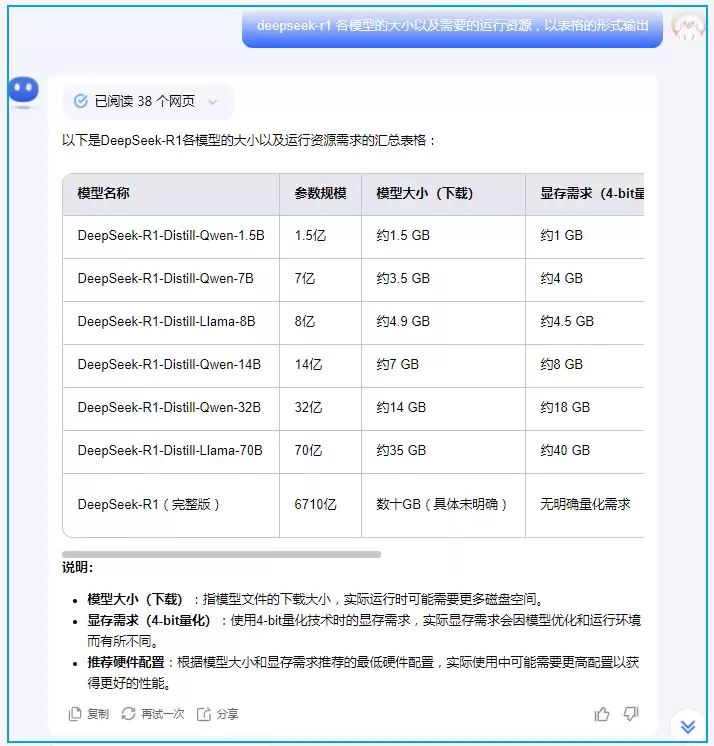
再比如,deepseek-r1:1.5b中的"b"到底代表什么?这类技术参数可以直接用AI查询。更有意思的是,你会发现今天所有博客、公众号的内容,几乎都成了AI的素材;而人们又通过AI去获取信息、再写公众号文章——最终,闭环了。