掌握W3C标准本体论与Palantir私有本体论的核心区别,助您深入理解数据建模的本质与未来演进方向。 核心内容: 1. 本体论的哲学起源与W3C标准定义 2. W3C语义网完整技术栈的构成与边界 3. 与Palantir私有建模体系的关键差异对比
引言
近两年,本体论(Ontology)在技术圈的热度持续攀升。日常交流中,大家提到的“本体论”实际上指向两套截然不同的建模体系:一套是W3C语义网标准所定义的信息科学本体论,具备全球统一、开放规范的特征;另一套则是Palantir Foundry平台自主研发的私有建模层,仅在其产品体系内生效。虽然术语相同,但底层假设、标准规范、核心目标乃至能力边界,均存在本质性差异。
本文将基于W3C官方规范、Palantir官方平台文档以及本体论的学术共识,对这两套体系展开系统对比。从本源出发,逐步深入到具体的技术栈与工程落地实践,最终探讨在AI时代它们各自所展现的差异化价值。
一、本体论的两层本源定义:哲学根基与W3C标准化规范
1. 哲学层面本体论(Ontology词源本源)
本体论最早源于哲学领域的“存在论”,其核心聚焦于两大根本问题:客观世界中究竟存在哪些实体?这些存在物的底层结构与内在关联又是怎样的?代表性理论包括亚里士多德的实体-属性二元模型、海德格尔的存在阐释等。
这套体系的底层逻辑极为开放,不预设任何前提,也不绑定任何固化的业务流程。它纯粹是一种用于抽象认知世界的方法论。可以说,它是所有“本体”概念的词源基础,但绝不能直接将其作为工程建模工具来使用。
2. 信息科学标准本体论(学界+W3C公认权威定义)
1993年,Gruber提出了基础概念;至1997年,Studer、Benjamins、Fensel等学者进一步形成了计算机领域通用且完整的定义:
An ontology is a formal, explicit specification of a shared conceptualization.
翻译过来即为:本体论是对共享概念体系做出明确、形式化的规范说明。
该定义包含四个不可拆分的约束条件,它们共同划定了标准本体的核心工程边界:

3. W3C语义网完整配套技术栈
许多人认为标准本体仅能描述静态的实体关系,实则不然。W3C提供了完整的技术栈,覆盖校验、服务、审计、权限甚至数据写入等环节。不过,其设计哲学遵循分层解耦原则——每项规范各司其职,互不耦合。具体包括:
1. RDF/RDFS:三元组基础知识描述框架,用于定义类与基础属性。
2. OWL 2:扩展子类、等价类、互斥类、基数、传递关系等逻辑公理,支撑全局知识推理。底层默认采用开放世界假设(OWA):未明确声明的事实视为未知,而非虚假。
3. SHACL(形状约束语言):面向RDF实例数据校验,采用封闭世界假设,支持字段格式、基数、跨实体业务校验。但其输出仅为校验报告,不具备事务写入能力。
4. SWRL:基于OWL 2的Horn推理规则,仅能推导出新知识事实,无法驱动外部系统变更或写入。此外,许多推理机对复杂SWRL的支持存在局限。
5. OWL-S:标准化Web服务语义描述,仅定义接口的入参、输出、前置后置条件,未内置执行引擎、权限控制或审计日志。
6. PROV-O:溯源本体标准,仅规范操作记录的语义结构,不提供不可篡改的事务级审计。
7. WebAC:RDF资源细粒度访问权限标准,属于上层附加规范,主流本体编辑器和推理引擎并未原生集成。
8. SPARQL Update:标准RDF事务写入语法,仅提供数据变更接口,权限、流程、校验均需外部系统独立实现。
关键结论是:标准本体确实具备规则、校验、服务建模的能力,但缺少一体化的执行闭环。业务变更、权限、审计等功能,全部属于外置组件。本体论的核心职责,聚焦于跨主体知识共享与逻辑推理。主流的落地载体包括:RDF图数据库、通用知识图谱、跨机构语义融合项目。
二、Palantir Ontology:平台私有操作语义层
Palantir借用了“Ontology”一词来命名其建模框架。不过,它不提供原生OWL/RDF标准格式的导出能力,因此严格来说,它并不属于语义网体系下的标准本体实现。
官方对其核心定位是:面向企业内部决策闭环的一体化语义与运行契约层。它完整整合了数据、业务逻辑、可执行操作、全链路安全治理四个维度。底层设计目标是实现平台内可控的数据双向读写,以及AI Agent的自动化运营。
以下是Palantir Ontology的五大核心组件及其与标准本体的对标:
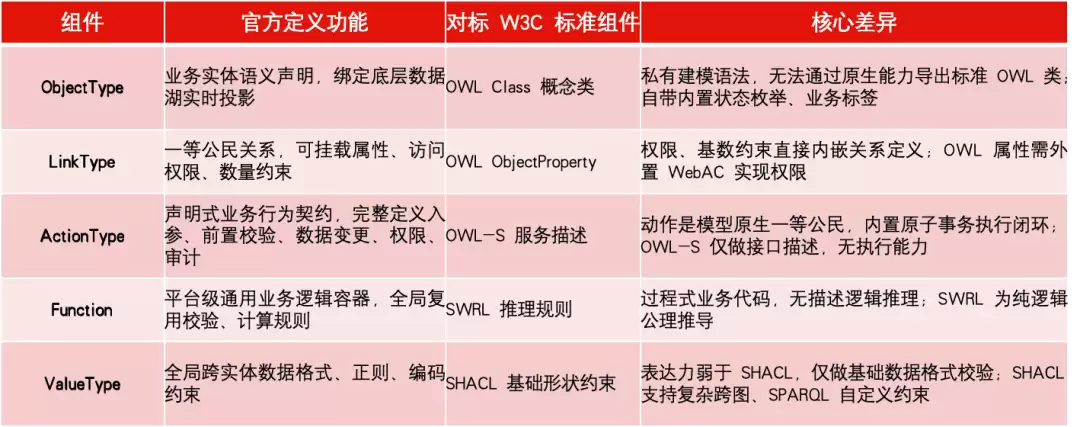
关于底层存储架构,需要客观说明几点:
1. 原始落地层:业务原始数据持久化在Iceberg、Parquet等列存数据湖中,长期归档采用列式存储。
2. 查询计算层:平台内置了定制化的属性图索引服务,用于实体关联遍历,这属于内存/计算层的逻辑视图。
3. 一个关键区分点:Palantir并不独立部署持久化的原生图数据库来存储全量实体关系。而主流的RDF引擎可以选择图数据库、关系库、数据湖等任意存储载体。两者仅是存储选型思路不同,并无优劣之分。
底层世界观假设的核心差异:
1. W3C OWL标准本体:采用开放世界假设(OWA),适用于互联网分布式、信息不完整的场景。
2. Palantir Ontology:采用封闭世界假设(CWA),面向企业内部完整可控的业务数据。凡未声明的事实,直接判定为不成立,适配确定性业务流程校验。
三、标准本体论与Palantir Ontology多维度对比
核心公式可这样区分:
标准本体论(核心:知识共享推理)= 领域概念模型 + 关系模型 + 描述逻辑公理模型 + 分层配套标准组件(规则/服务/审计/权限,独立分层)
Palantir Ontology(核心:平台内业务执行)= 业务对象模型 + 链接关系模型 + 内置操作执行模型 + 内嵌运行约束 + 原生三维权限与事务审计模型
| 对比维度 | 标准本体论(OWL/RDF/W3C语义网) | Palantir Ontology |
| 本质定位 | 跨组织通用标准化领域知识交换规范 | 单一平台内部私有业务运行闭环建模框架 |
| 核心目标 | 统一跨系统语义、异构数据互通、自动化逻辑蕴含推理 | 统一平台内业务执行、双向数据回写、全流程合规审计、AI受控操作 |
| 核心组成主次 | 概念、关系、逻辑公理为主;动作/权限/审计为分层配套标准组件 | 对象、链接、Action行为为核心;权限、校验、审计深度耦合模型定义 |
| 业务动作建模能力 | 可建模服务接口(OWL-S),仅提供契约描述,无原生执行引擎 | ActionType为原生一等公民,内置完整事务执行链路 |
| 数据写回闭环 | SPARQL Update提供写入接口,事务、校验、审计需外部系统拼接 | Action内置原子事务:参数校验→权限校验→前置规则→数据写入→同步不可篡改审计日志→外部系统同步,一体化闭环 |
| 权限体系实现 | WebAC国际标准,独立于本体模型,跨系统通用;主流工具无原生集成 | 对象/字段/Action三级内嵌权限,基于角色、数据标记、使用目的三维管控,平台原生生效 |
| 审计溯源特性 | PROV-O仅定义溯源语义,无事务级不可篡改日志绑定 | 写入操作与审计日志同一事务持久化,日志私有格式,仅平台内可解析 |
| 核心执行引擎 | DL描述逻辑推理引擎:支持完备、可靠且可判定的自动化逻辑推理,自动推导子类、传递关系、等价实体等隐含知识 | 业务执行引擎:驱动Action完成数据变更;无通用描述逻辑推理能力,仅支持自定义过程式代码判断 |
| 底层存储适配 | 无绑定,兼容图数据库、关系库、数据湖、文件系统任意载体 | 原生适配Iceberg/Parquet数据湖,脱离Palantir平台无法直接迁移模型 |
| 形式化逻辑强度 | 极高,基于可判定OWL 2描述逻辑,支持完备、可靠且可判定的全局知识推理 | 中等,仅业务声明式契约语法,无公理推理体系,仅运行时逐条校验 |
| 适用使用者 | 知识工程师、跨机构协同项目、多系统数据融合、知识检索RAG场景 | 企业内部运营团队、平台内AI Agent、业务合规决策者、内部一体化运营项目 |
| AI协作模式 | 为跨数据源RAG提供标准化语义索引;LLM需对接外部API、权限系统完成操作,无原生人工复核流程 | 为平台Agent提供完整Action契约;运行时根据角色、实体状态动态过滤可用操作;原生Proposal提案机制,AI仅生成变更草案,人工审核后执行 |
| 标准化互通性 | W3C开放国际标准,模型可导出RDF/OWL/SHACL,无厂商锁定风险 | 完全私有封闭规范,无原生标准语义导出能力,存在强厂商锁定,模型无法原生跨平台复用 |
| 工程落地成本 | 轻量本体可快速搭建;复杂业务执行场景需额外集成流程、权限、审计组件,集成成本高 | 一站式集成语义、执行、安全能力;但建模门槛高,Schema刚性较强,业务迭代修改模型成本高 |
案例对照:车辆生产领域建模
1. W3C标准本体完整建模
a) OWL 2定义概念类:车辆 Vehicle、零件 Part;对象属性:Vehicle requires Part。
b) OWL 2公理:车辆生产必须配套全部必需零件。
c) SHACL约束:零件库存数值不可为负数。
d) SWRL规则:零件库存<需求数量 → 推导“禁止生产”事实。
e) OWL-S:标准化“启动生产”服务接口,定义入参、访问权限。
f) PROV-O:定义操作溯源记录语义。
短板在于:整套模型只能推导、校验、描述接口,无法原生驱动MES/ERP同步写入,没有内置的事务、审计、权限拦截逻辑,需要额外开发外部执行层。
2. Palantir Ontology建模
a) ObjectType:车辆 Vehicle,内置生产状态枚举(计划中/生产中/已完工)。
b) LinkType:车辆 - 需要零件,链接挂载需求量、必需标记、访问权限。
c) ActionType:startProduction 启动生产,内置六层原子执行链路:参数格式校验→角色+数据标记权限校验→Function校验零件库存前置条件→原子事务更新车辆状态→同步生成不可篡改审计日志→自动双向同步数据至MES/ERP外部系统。
二者都能覆盖实体描述与生产流程管控,核心架构差异在于:标准本体依靠多套开放标准分层拼接实现,具备跨平台复用性,但缺少执行闭环;Palantir则将全部执行、管控能力耦合进建模语法,平台内一站式可用,但无法对外互通。
四、建模分层体系说明
行业技术社区中常提及一套三层建模分层表述。这套说法在讨论中较为常见,但需要说明的是,它并未获得W3C、ISO或学术界的通用权威标准支撑,仅可作为辅助理解的能力分层视角,并不代表层级之间存在代际优劣或高低之分。
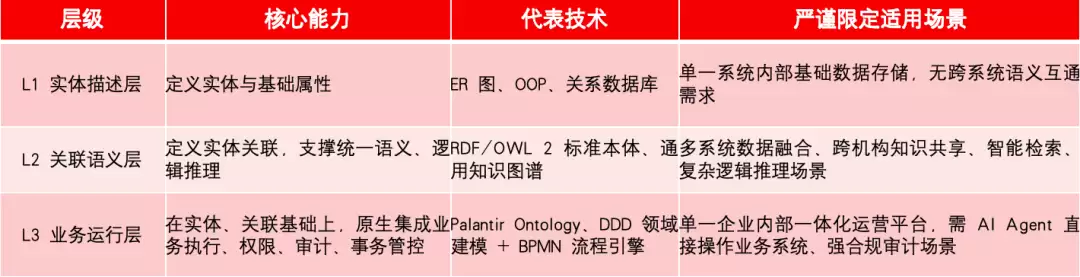
补充一句:L3并非Palantir独有范式,DDD聚合根、BPMN流程引擎均属于同类方案——它们都在描述“业务如何运行”。Palantir的差异化之处在于,它将执行与安全逻辑深度嵌入到了语义建模层。
五、大模型AI时代:两套体系差异化价值
精准定位一下二者的区别:
标准W3C本体论,解决的是AI跨平台读懂知识、互通数据、全局逻辑推理的需求。
Palantir Ontology,解决的是单一企业内部AI安全、合规、一体化执行业务操作的需求。
两者能力互补,不存在互相替代的关系。工程实践中可采用混合架构落地——例如内部使用Palantir进行运营建模,上层再对接一层OWL 2标准本体,实现对外跨组织的数据互通。
1. 标准W3C本体论+LLM
优势:
a) 标准化语义结构,支撑跨数据源、跨机构的RAG知识检索,统一异构知识库语义。
b) 开放格式,LLM可对接所有兼容W3C标准的外部系统,无平台绑定。
c) 完备的DL逻辑推理能力,依靠本体公理约束大模型输出,有效降低知识幻觉。
客观局限:
a) 执行链路分散,LLM调用业务操作需额外对接API、权限、审计模块,整体集成成本更高。
b) 缺少原生的提案审批闭环。虽然可基于外部工作流搭建人工复核流程,但这不属于本体的原生内置能力。
2. Palantir Ontology+LLM/AI Agent
优势:
a) Agent可统一识别平台内的语义对象,无需适配多套异构业务接口。
b) Action自带完整契约:入参规范、权限拦截、前置业务规则、原子事务、审计日志一体化。
c) 运行时动态裁剪Agent可执行的Action列表,根据用户角色、实体实时状态实现权限隔离。
d) Proposal提案原生机制:AI仅生成变更提案,人工审核确认后才执行,大幅降低误操作风险。
客观局限:
a) 本体模型、Action定义、权限规则完全私有封闭,Agent的能力无法跨平台原生复用,仅在Palantir体系内部生效。
b) 缺失通用描述逻辑推理,复杂的多维度知识推导、跨实体蕴含计算能力弱于OWL 2标准本体。
c) 平台重度绑定,整套模型和业务规则无法原生迁移到其他数据平台,长期存在厂商锁定风险,建模与维护成本偏高。
六、总结:两套体系取舍逻辑与选型客观结论
W3C标准本体论 = 全球通用标准化地图
优势:统一语义语言、跨组织自由互通、无平台绑定、强大的全局逻辑推理。
短板:仅提供静态知识描述框架。若要落地业务变更与流程管控,需额外集成流程、权限、审计等外部组件,一站式运营闭环的实现成本较高。
Palantir Ontology = 企业专属一体化操作系统
优势:企业内部一套体系即可完成语义查看、业务调度、权限管控、操作留痕、双向数据变更。AI Agent能够直接安全地执行业务。
短板:仅适配自有平台,更换数据系统就需要完整重构整套模型。Schema刚性较强,快速迭代多变业务时改造成本高,存在厂商锁定风险。
一句话总结:两个体系虽共用“本体”一词,但本质区别显著。技术选型时,需结合短期业务落地与长期数据互通诉求综合判断,不能简单地说某一套体系全面优于另一套。