最近,清华教授、智谱AI灵魂人物唐杰在社交媒体上相当活跃。昨天刚聊完AI的终局认知,抛出了“AI的终局就是AGI,一场猎龙游戏”的观点,引发广泛讨论后,今天又当众发起了一次需求征集:
各位!下个版本的GLM,你想要啥?
这条推文刚发出,浏览量就飙到了40w+。其影响力可见一斑。
但要说网友们为何如此捧场,还得往回看。去年GLM-4.6刚开源时,唐杰也做过类似提问。当时的评论区里群策群力,一条条需求后来都陆陆续续在GLM后续版本中得到了实现。那叫一个“有求必应”。
所以这次一开口,懂行的人立刻团建去了——有人po出自己的痛点,连智谱自家员工都下场留言。
比方说,有网友直接拉出一张心愿单:更强的Agent能力、超长上下文保持质量、更灵活的API……

还有更直接的,诚恳祈祷:求你了GLM!做一个类似Codex的桌面应用吧!
不过有趣的是,这次GLM-5.3的评论区刷得最多的,居然还是——视觉能力。
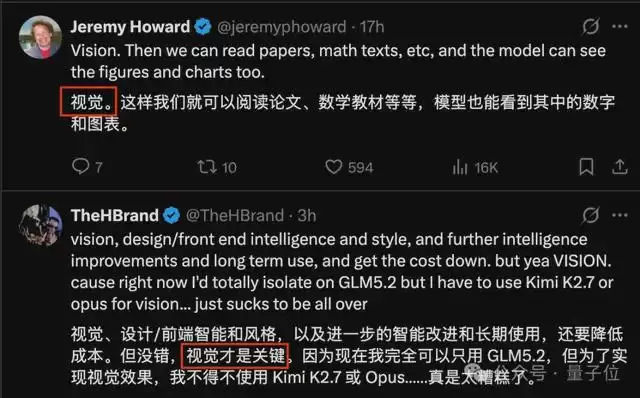
GLM的视觉之痛
两周前,智谱刚刚开源了GLM-5.2。
作为纯文本模型,它强得离谱——百万Token超长上下文、深入的逻辑推理,开源界AI编程第一名,全球第二,仅次于大名鼎鼎的神话级模型Fable-5。
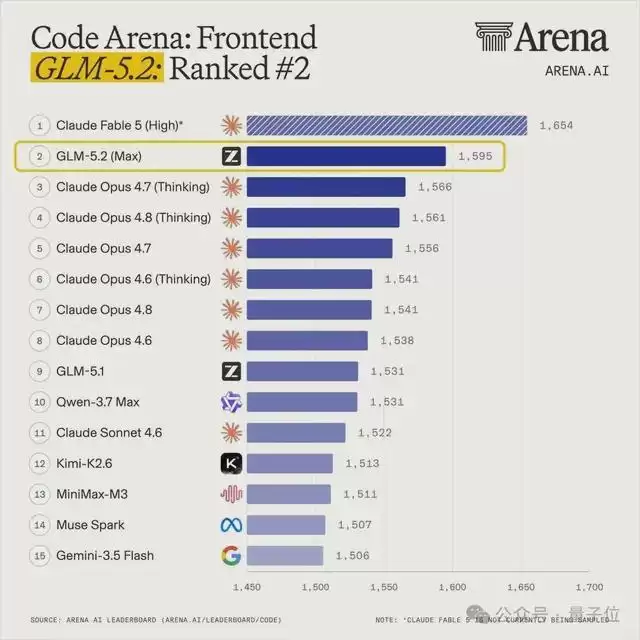
但痛点也真实得扎心:没有视觉能力。
看不了图,也造不出图。反观拿来对标的Fable-5,那是原生多模态,视觉能力应有尽有。于是GLM用户只能流下羡慕的泪水:我也想拥有……

关键在于,智谱不是做不出多模态视觉。今年4月,他们刚发布过一个叫GLM-5V-Turbo的模型:原生多模态Coding基座,从预训练阶段就把视觉和文本揉在一起,能看懂设计稿、截图、网页界面,然后直接吐出能跑的代码,主打视觉+代码+Agent一体化。
再往前看,智谱做过不少多模态模型,CogVLM视觉编码器就出自他们之手。唐杰本人发表过的视觉论文,更是一抓一大把。
所以问题根本不是有没有视觉能力,而是智谱没把视觉放进最强旗舰模型中去。
这一点从唐杰过往的发言中也有迹可循。比如去年底的大模型年终总结里,他先是肯定多模态是未来。但随即话锋一转:
问题是,当下的多模态对提升AGI的智能上界,帮助有限。可能最有效的方式还是分开发展,文本、多模态、多模态生成。当然,适度的探索这三者的结合肯定能发现一些很不一样的能力,但这需要勇气和雄厚的资本支持。
你品,你细品。唐杰这种冲在AI一线的科学家,盯着的始终还是第一性原理——模型智能。视觉可以让模型更好用,但要让模型更聪明,靠的还是复杂推理那套硬功夫。
这就是用户和厂商的视角差异。AGI对于用户太遥远了,他们更在乎的是,眼下贴张图模型能不能接住、截个屏模型能不能看懂。
于是便有了这篇推文里最微妙的拉扯:一边是科学家盯着智能天花板,觉得视觉只是锦上添花;一边是全世界的开发者齐刷刷呼喊视觉能力。
而且,对手也来势汹汹。Kimi K2.5今年1月就是原生多模态了,Qwen3.5-Omni三月份端到端把文本/图像/音频/视频全统一进一个模型;更别说国际上Gemini 3那种原生文图音视频一把抓的。
GLM旗舰款补足视觉,几乎是迫在眉睫。且等接下来端上桌的GLM-5.3。
One More Thing
最后,不妨再看看唐杰最近的一些分享,挺值得琢磨的。
(其一)

(其二)

(其三)

(其四)
