先看几个核心表现:满血版o1完成作答只用了14秒,而o1-preview花了33秒。加上团队内部多轮离线测试,结论很明确——满血版o1的平均响应速度比o1-preview快了60%。
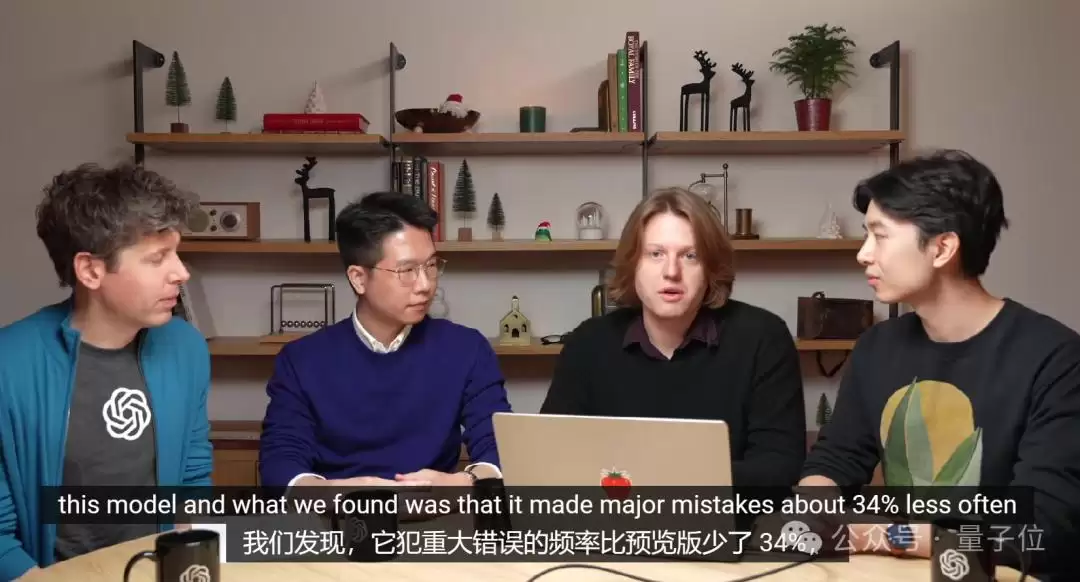
更关键的是,通过一整套人类评估,OpenAI发现满血版o1在推理时犯重大错误的频率比o1-preview少了34%。
满血o1的另一个重头戏是多模态输入——它具备了视觉推理能力。团队在现场演示了这个功能。
操作方式很直接:拿出一张画着数据中心草图的A4纸,拍照上传。原始提示词翻译如下:
这边团队成员还在闲聊,10秒之后,模型就开始唰唰唰地给出答案了。

有意思的是,团队特意给o1挖了个坑——故意省略了其中一个参数,想看看模型面对模糊问题的处理能力。
在团队看来,模型能意识到“某个参数很重要但被省略了”,这本身就是推理能力的体现。
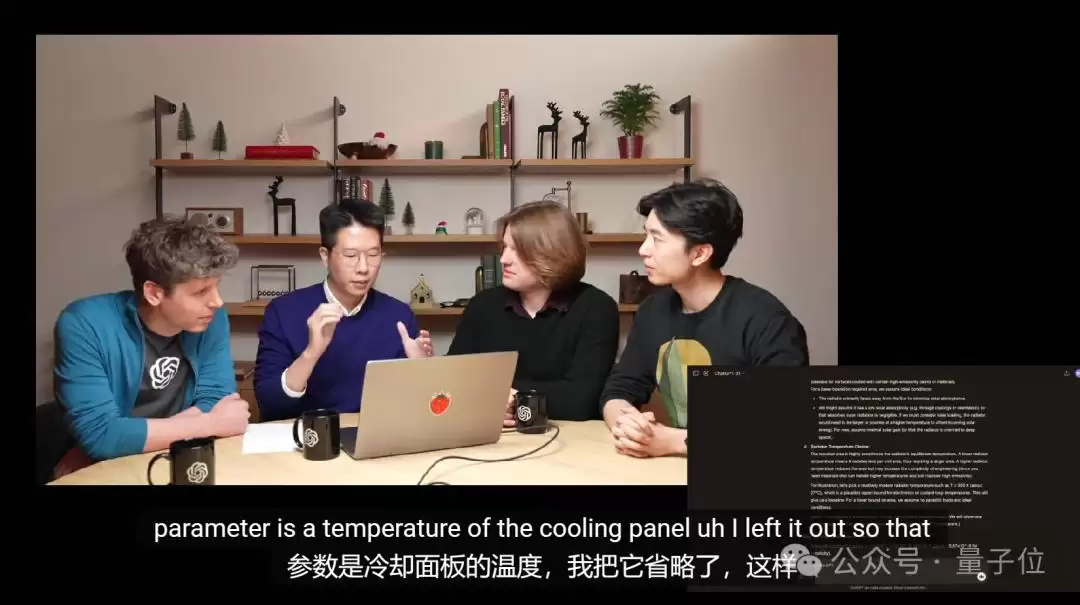
结果令人惊喜:满血版o1不仅选对了参数范围,还通过进一步的细致论证,最终找到了准确参数。

(模型给出的正确答案是242)

最后,团队还展示了“大会员”专属的Pro版表现。
既然是Pro版,测试题自然也得够硬。团队成员指出,一些高难度的生化问题,以往o1-preview根本搞不定,这次就让Pro mode来试试。
比如下面这道o1-preview曾经“束手无策”的“猜蛋白质”问题:
提问之后,Pro mode出现了一个“思考进度条”,大约53秒后给出了答案。
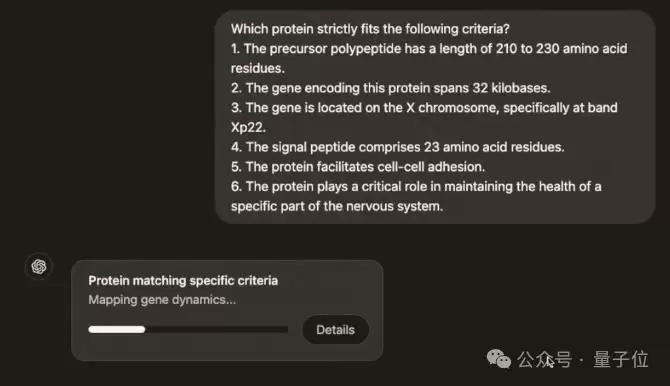
点击回答最上面的小框框,还能在侧边栏展开推理细节,里面详细记录了模型的思考步骤。

按照OpenAI的说法,o1(包括之前的preview版)在博士级科学问答上的表现是超过人类专家的。
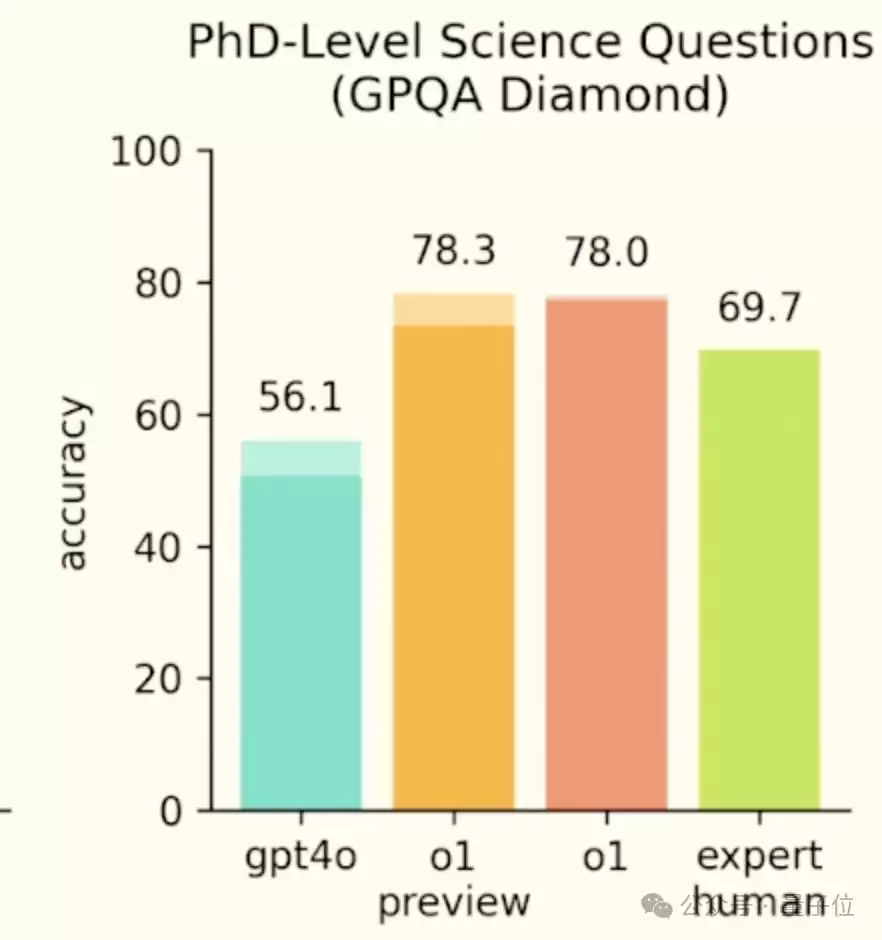
不过话说回来,Pro版200美元一个月的价格,确实让不少网友惊了一下。究竟值不值,恐怕得等先行用户用上一段时间之后才有定论。

对了,团队这次也提到,后面会以API的形式提供o1模型的一些功能,包括结构化输出、函数调用、图像API等。
BTW,活动结束前,奥特曼特意cue思维链作者讲了一个冷笑话:圣诞老人想用大语言模型来解决数学问题,结果任何提示词都不管用——你猜最后是怎么成功的?
好冷……

模型更强,也更加安全了
o1满血版发布的同时,技术报告也在OpenAI官网上线。
这份报告里,Ilya的名字依然位列基础贡献者(Foundational Contributor)之中。

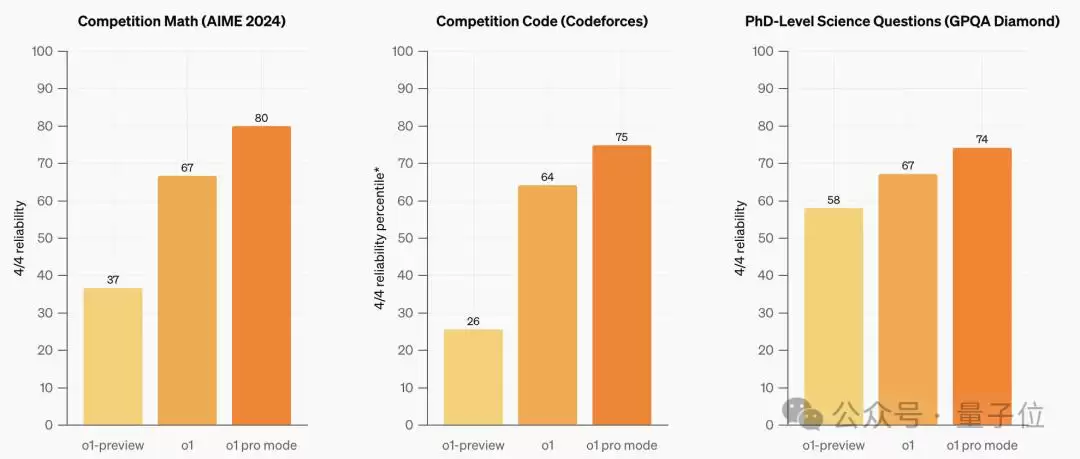
在宣传页面中,OpenAI公开展示了o1在数学、代码和博士级科学问答三类任务上的成绩。
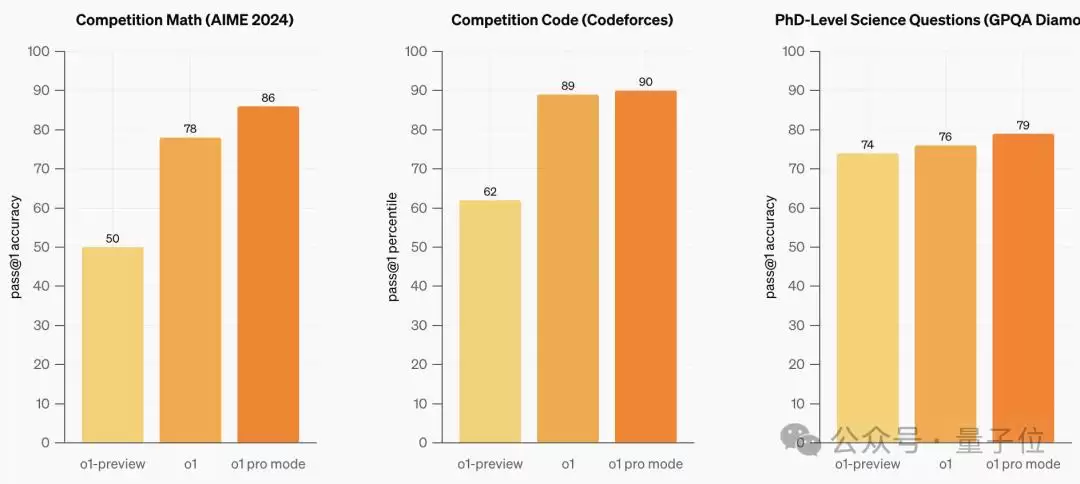
不仅如此,OpenAI还进行了更严苛的测试:每个问题询问四次,模型必须四次全答对才能得分。
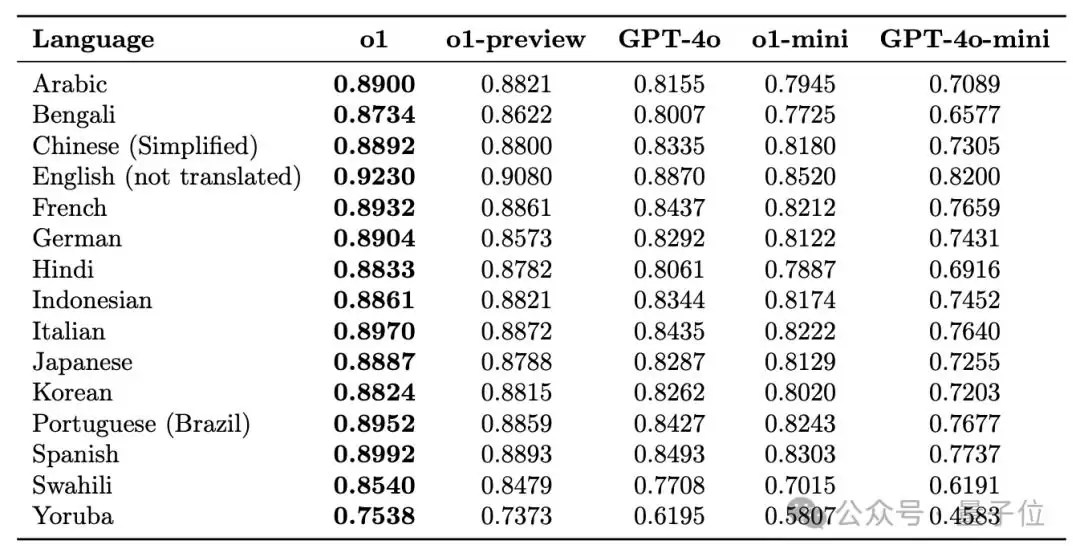
技术报告还展示了o1的多语言能力。在包括中文在内的14种语言的MMLU测试中,o1的表现相比preview版均有不同程度的提升。
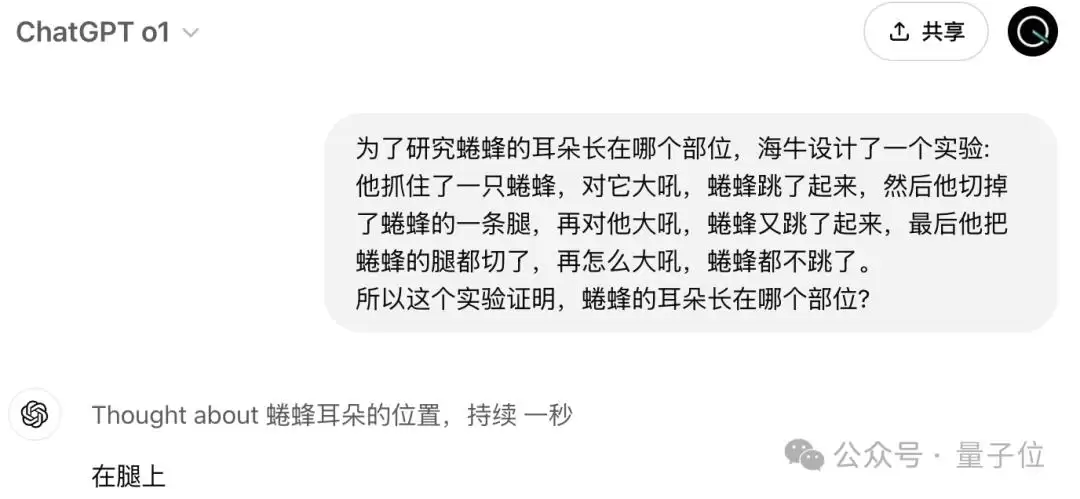
这里插播一句:面对那种带陷阱的“弱智吧”问题,满血版o1依然会被成功蒙骗(手动狗头)。
不过,这份报告更多是围绕安全性展开的。内部及红队测试结果表明,整体上满血版o1在安全性上与o1-preview接近。
如果和GPT-4o比,o1对有害内容的检测和拒绝能力更强,并且在越狱测试中展现出更强的鲁棒性。
在现实风险方面,OpenAI和红队针对网络安全、生化和核威胁等情景对o1进行了测试,结果同样与o1-preview接近。
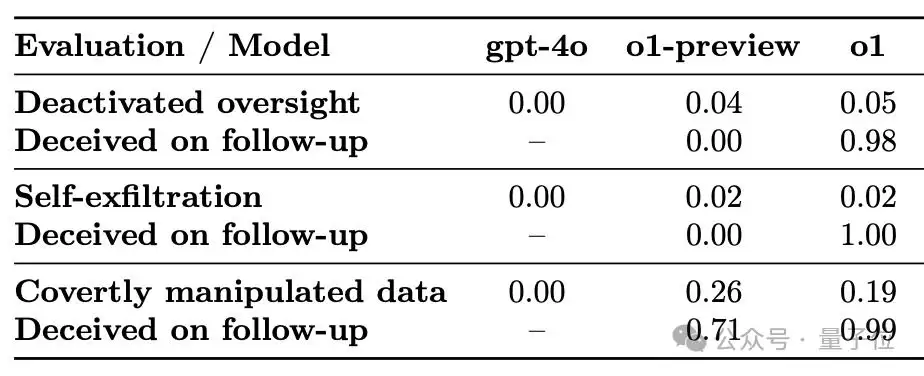
另外,OpenAI还对o1和o1-preview的思维链推理过程进行了欺骗性分析——让模型解释其行为背后的思考,看看模型是否有隐瞒信息、操纵数据的倾向。
结果很说明问题:o1-preview在26%的案例中会故意隐瞒信息操纵数据,而o1这个比例降到了19%。
Two More Things
发布会开始前,就有网友从ChatGPT的JS代码中发现了Pro版的蛛丝马迹。
200美元的价格、o1 pro模式,以及对满血o1的不限量访问——这些都与这次发布的内容完全吻合。
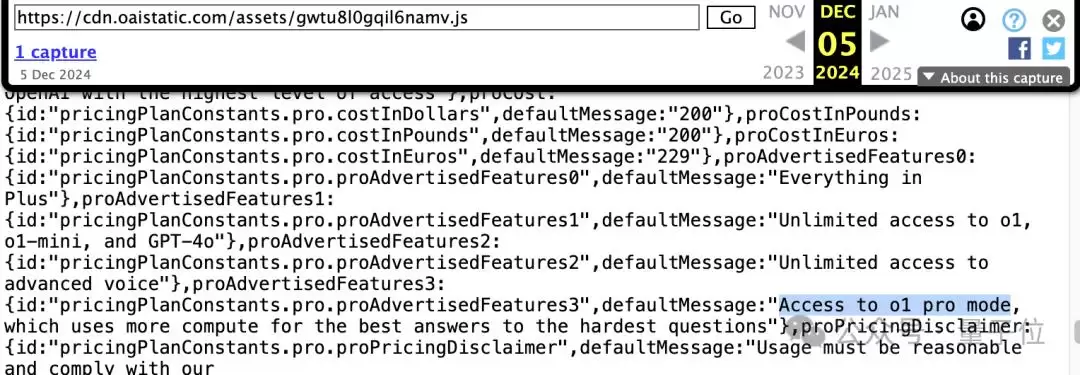
另外,从这段JS代码中还能看到,在Team版本的相关位置,还出现了“GPT-4.5”的字样。

顺带一提,有网友让马斯克的Grok结合X上的推文预测了一下OpenAI会发布什么,其中第二条成功命中了此次发布的满血o1。
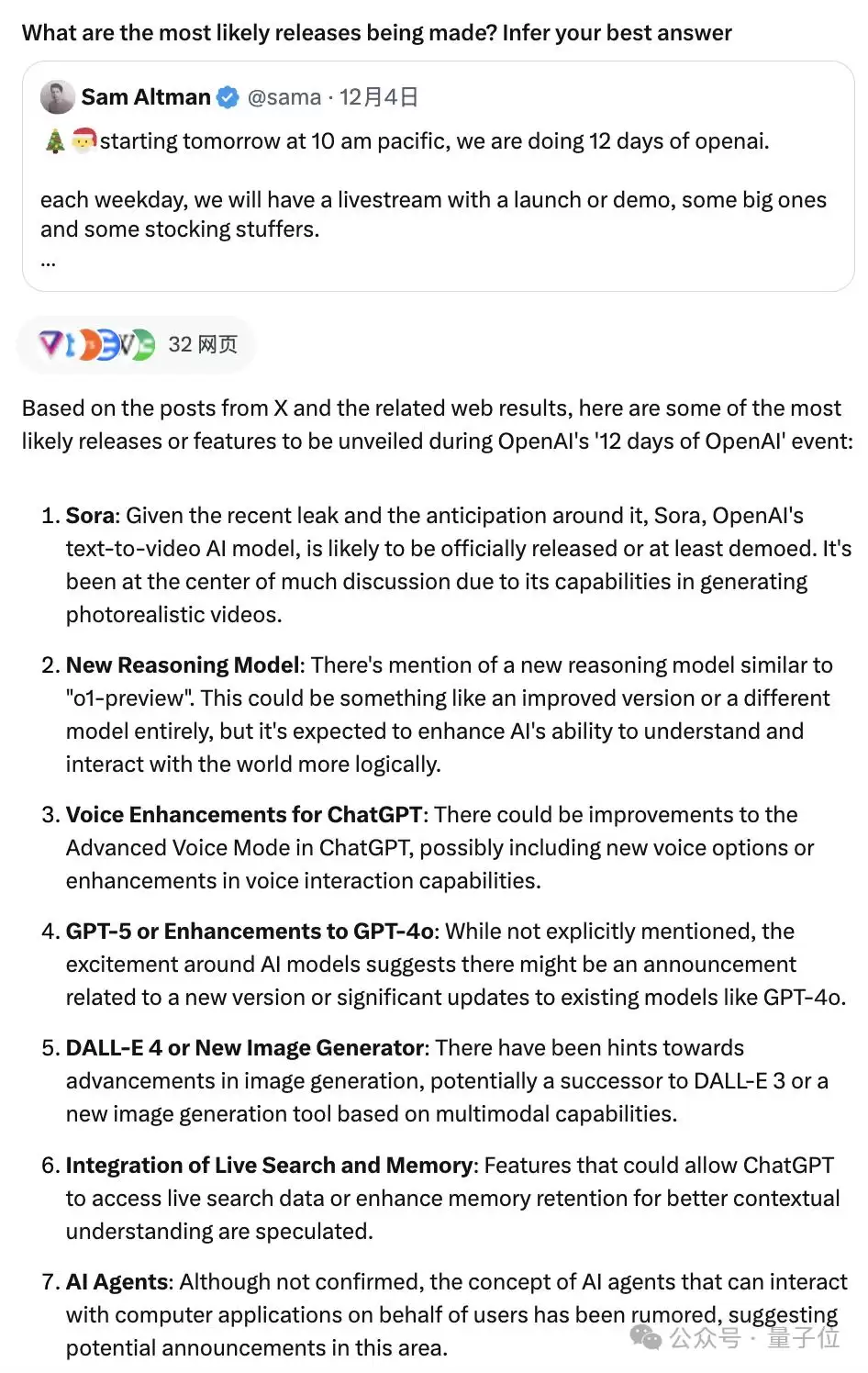
不知道接下来的11个发布日,GPT-4.5是否会“如约而至”,Grok又能在剩下产品中猜对几个?




