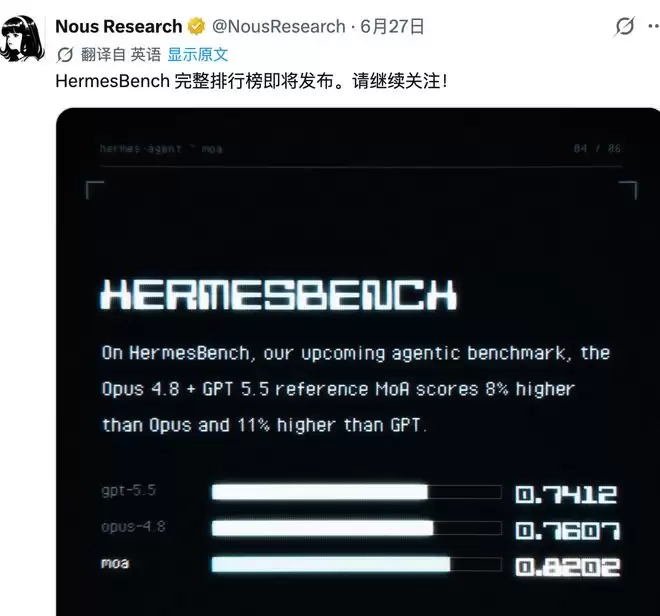
顶尖闭源大模型要么遭到封禁,要么总存在难以解决的实际问题。面对这种情况,用户该如何应对?近日,Hermes Agent 正式上线 MoA(多智能体混合)功能,允许用户自由组合多种模型,将其作为一个虚拟模型来使用。在 Nous Research 即将公布的基准测试中,这一混合模型的评分甚至超越了 Opus 4.8 和 GPT-5.5。
一、Fable 5、Mythos 5 被禁,多模型组合成为行业趋势
Nous Research 在官方推特上如此表态:“最强大的模型总是受限的,只有极少数人才能获得访问权限。”这句话毫不掩饰地指向了 Fable 5 等模型遭到封禁的事件。

在这一背景下,MoA 的终极目标非常明确:利用开源模型的组合达到顶尖闭源模型的水准。正如 Hermes Agent 联合创始人 Teknium 所说,团队正在测试各种开源模型组合,探索是否能用成本更低的模型实现 Opus 级别的效果。
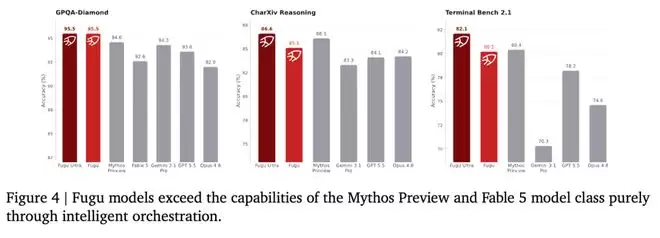
这种思路其实早有先例。例如,此前日本 AI 独角兽 Sakana AI 发布的 Sakana Fugu 系列编排器模型,会根据具体任务选择最合适的模型来处理,与 MoA 有异曲同工之妙。
MoA 的技术基础也并不新鲜。2024 年 6 月,Together AI 曾发表论文《Mixture-of-Agents Enhances Large Language Model Capabilities》,其核心思路是多 LLM 组合,每一层模型都会参考上一层的输出结果,再继续生成自己的回答。同时,论文将模型划分为两类,即现在 Hermes 所使用的参考模型和聚合模型。

具体来说,当用户提出问题时,参考模型会先分析问题并提供参考意见,随后由聚合模型进行综合判断,调用工具执行具体任务。参考模型仅负责生成意见,不使用任何工具,也不执行任何命令。这种模式能够充分发挥不同模型的独特优势——让擅长规划的模型出谋划策,让长于执行的模型落实行动。
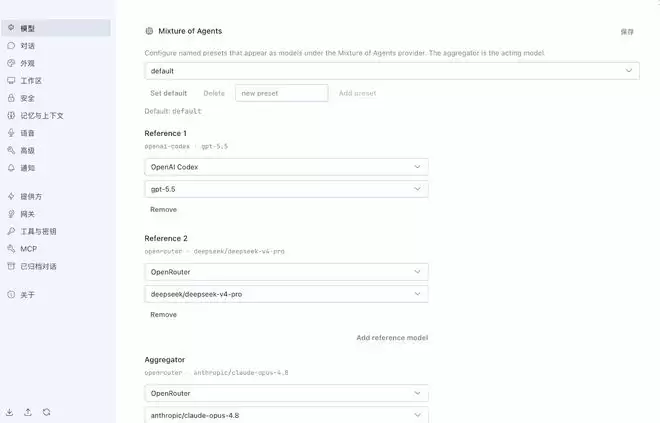
使用这一模式也十分简便。以桌面版为例,在设置中打开模型选项,向下滚动即可看到“Mixture of Agents”选项,直接选择想要使用的模型组合即可。默认配置为两个参考模型加一个聚合模型,用户也可以手动添加更多参考模型。
二、实际测试:游戏制作更流畅,Token 消耗差异不大
海外博主进行了针对性实测,采用两种组合方式分别生成了游戏和交互页面。结果发现,MoA 的任务完成时间并不一定会延长,具体取决于模型选择,同时 Token 消耗量也没有想象中那么惊人。
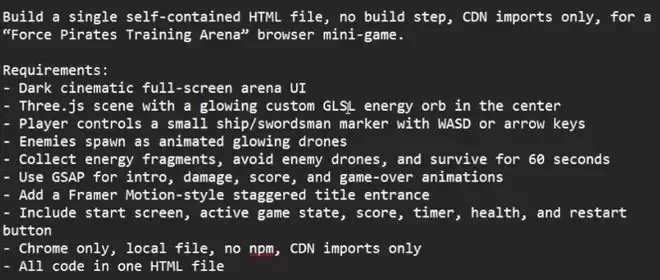
博主首先测试了小游戏制作,使用 Three.js 开发一个原力海盗训练竞技场游戏。作为对照组,先使用单一模型 glm-5.2 进行测试,输入提示词:
Hermes 花费 0.38 美元,耗时 13 分钟完成了游戏。单一 glm-5.2 生成的整体效果尚可,但移动速度和流畅度存在明显问题——飞船很难躲避敌人攻击,可玩性较差。

随后博主启用了 MoA 模式,使用 kimi-k2.6 和 minimax-m3 作为参考模型,glm-5.2 作为聚合模型,输入相同的提示词。
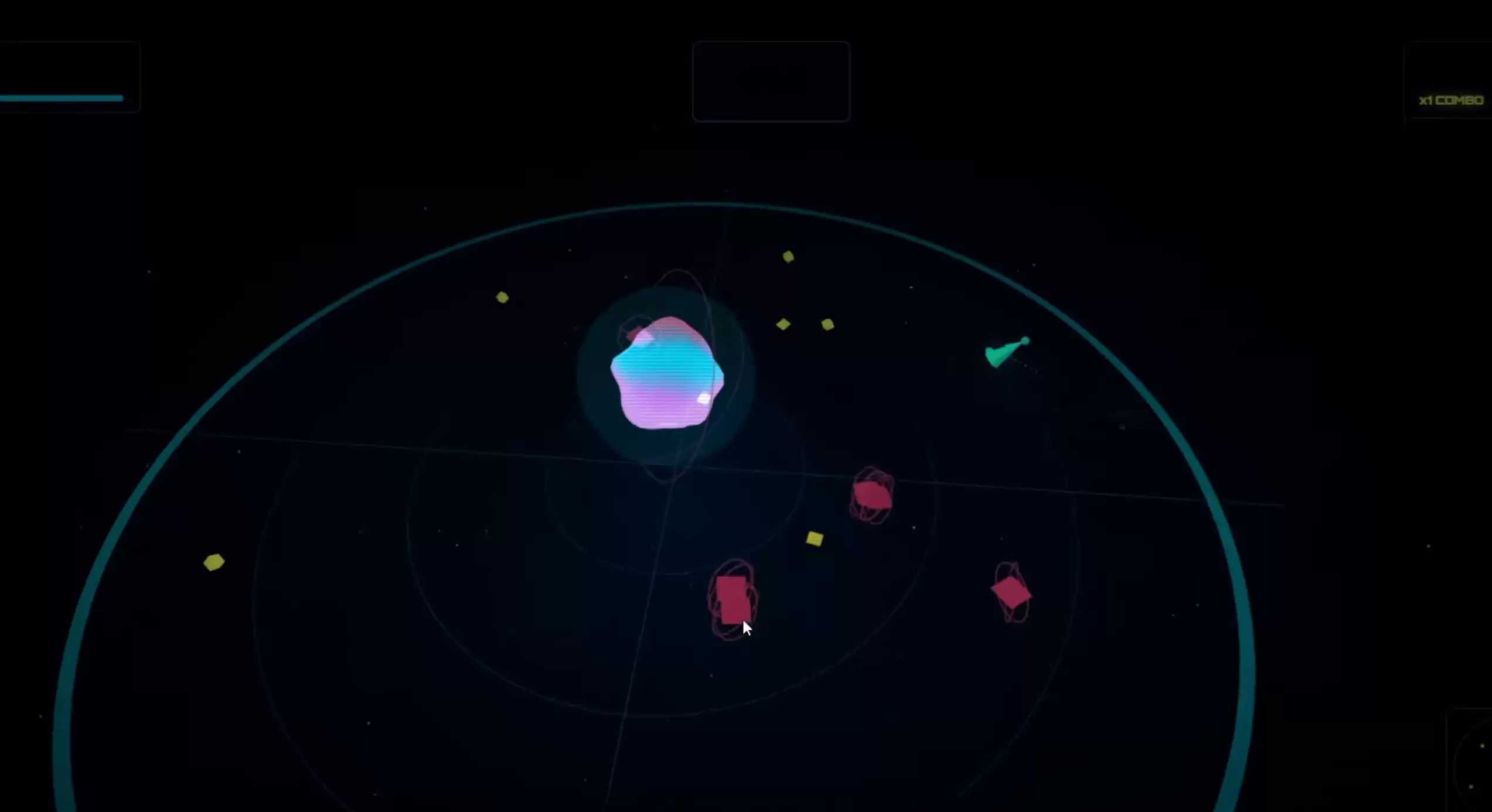
这次 Hermes 花费 0.47 美元,耗时 35 分钟——成本略高,时间接近原来的三倍。然而,MoA 模式生成的游戏效果明显更优,移动速度、流畅度以及关卡设计的合理性都远超单一模型的输出。
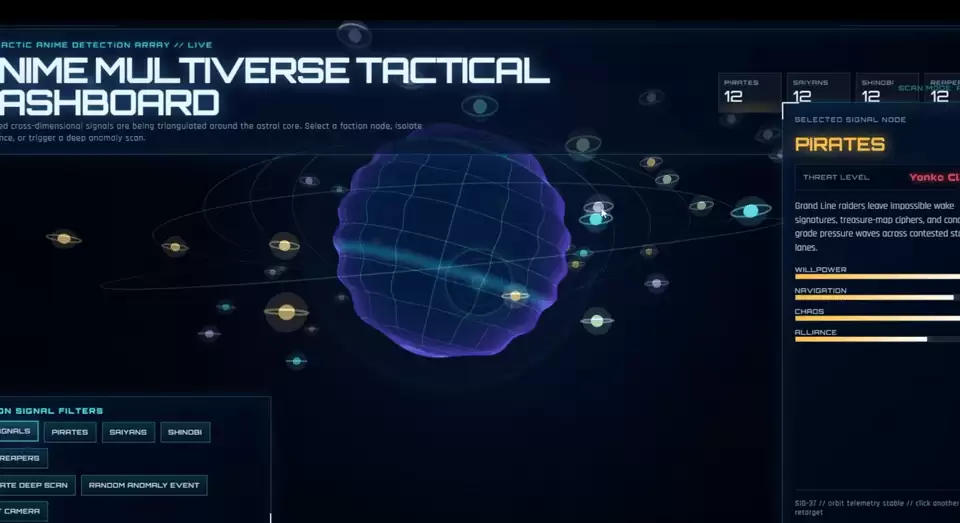
随后博主又用顶尖闭源模型 GPT-5.5 进行了测试,这次要求 Hermes 生成一个可交互的动漫多元宇宙仪表盘,涵盖火影忍者、海贼王、龙珠等 IP。对照组依然使用单一模型 GPT-5.5 执行任务。由于是订阅制,博主坦言无法核算成本。
Hermes 用了接近 7 分钟完成任务。生成的仪表盘中间光球周围的光圈略显简单,缺乏质感,但交互非常流畅。

随后博主使用三个 Grok 模型作为参考模型,GPT-5.5 作为聚合模型进行了同样测试。出乎意料的是,MoA 模式下 Hermes 的生成速度反而更快——推测是因为采用了 Grok 快速模型。
这次生成的仪表盘质感明显提升,中间光球设计感很强,整体交互非常丝滑,点击不同星球还能实现远近景切换。
结语:未来竞争的核心,不止于模型本身
过去,大模型领域的竞争几乎都围绕“谁家的模型更强”展开,用户需要不断切换模型,在编程、写作、推理等不同场景中寻找最合适的那一个。
但 MoA、Sakana Fugu 已经在另一条路上探索:与其等待一个“全能模型”,不如让多个擅长不同能力的模型协同完成一项任务。
这种走向“编排”的趋势,实际上恰好契合了 Agent 的核心需求——模型是底层能力,Agent 负责组织不同模型协作,让规划能力强的模型负责思考,让执行能力强的模型负责落地。
当然,目前 MoA 需要承担更高的推理成本,部分任务耗时也会明显增加,并非所有场景都适合开启。但随着推理成本持续下降、开源模型能力不断提升,多模型协作很可能成为 Agent 未来的默认工作模式。
