1. 背景:让 AI 接管训练全过程
最近在业余时间尝试用 YOLO26 训练一个目标识别模型。最初的想法非常直接——不仅仅是让 AI 写出训练脚本,而是希望它能串联起一整条自动化链路:
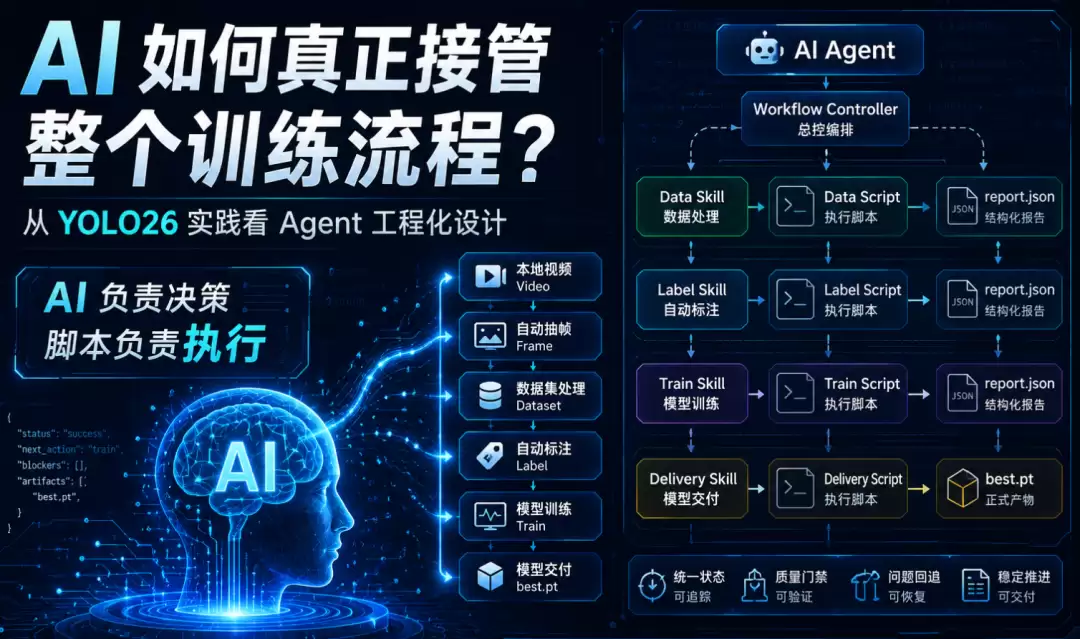
本地视频 -> 自动抽帧 -> 图片质量筛选 -> 去重 -> 自动标注 -> 标注质量检查 -> YOLO 数据集打包 -> 训练预检 -> 链路验证 -> 正式训练 -> 模型交付这个流程看上去清晰明了,但真正上手就会发现:问题不在于“让 AI 写代码”,而在于如何“让 AI 稳定推进复杂流程”。
2. 遇到的核心痛点
痛点一:项目一大,AI 容易乱
在单点任务上,AI 确实表现出色。编写抽帧脚本、解释训练报错、补充参数校验等都很顺手。但一旦流程拉长,AI 就开始混乱:上一轮还在处理数据,下一轮就窜去修改训练参数;看到日志里的 success,就误以为整个阶段已经完成;分不清 dry-run、链路验证和正式训练的区别;甚至不知道某个报错应该回到数据阶段处理,还是直接丢给训练阶段。
痛点二:输出不统一,AI 很难接力
每个阶段如果都按自己的方式输出结果——有的只写日志,有的打印一段文本,有的生成零散文件,有的连下步建议都不给——那么 AI 每次都得重新理解上下文。问题不是它不会处理,而是缺乏稳定的标准可读格式。
痛点三:一个 Skill 根本不够
刚开始容易想:写一个完整的 Skill,把所有规则塞进去。可项目复杂后,这个 Skill 会越来越臃肿——数据处理规则、自动标注规则、训练规则、交付规则全堆在一起。最后它更像一份超长的说明书。AI 仍然可能漏读、误读,或者把不同阶段的规则混着用。
痛点四:光靠文字约束不够
提示词可以提醒 AI 该做什么,但真正执行时,文字约束太不稳定。判断图片是否达标、标签是否生成、数据集是否可训练、模型是不是正式产物——这些不能依赖 AI 的主观理解,必须交给脚本和验证器来处理。
3. 设计转向
后来调整了思路。核心变化是:不再追求让 AI 更自由,而是让整个流程更可控。AI 不再凭感觉判断“这一步是否成功了”,而是走这样一个路径:
调用脚本 -> 读取结构化结果 -> 判断下一步 -> 必要时回退到对应阶段这样一来,AI 的角色从“自由操作员”转变为“流程协同者”。
4. 怎么把流程做稳
先拆阶段
把整个 YOLO26 训练过程拆分成几个清晰的阶段:
| 阶段 | 只负责什么 |
|---|---|
| 数据采集 | 从本地视频抽帧、筛选、去重 |
| 数据处理 | 自动标注、检查标签、打包 YOLO 数据集 |
| 模型训练 | 训练预检、链路验证、正式训练 |
| 总控编排 | 串联阶段、保存状态、判断下一步 |
关键不是拆得有多细,而是边界要清晰。数据阶段不训练模型,训练阶段不回头修改标签,总控阶段不直接处理图片、标签和模型文件。
再拆 Skill
一个大 Skill 不够,就拆成多个薄 Skill。每个 Skill 只回答三个问题:这个阶段负责什么?入口脚本是什么?应该读取哪个结果文件?复杂规则不写进 Skill,而是放进脚本、验证器和统一报告里。这样 Skill 不会变成冗长的提示词,AI 也更容易按边界行动。
统一输出标准
为了让 AI 稳定接力,每个关键阶段都输出同一组字段:
status(当前状态)、next_action(下一步动作)、blockers(阻塞原因)、artifacts(关键产物)这几个字段解决了很多问题。AI 不需要从长日志里猜状态,人也能快速知道:当前完成了吗?卡在哪里?下一步该做什么?关键文件在哪里?
5. 强脚本比强提示词更重要
在这个项目里,脚本不是辅助工具,而是流程的裁判。抽帧脚本不仅抽取图片,还会判断清晰度、曝光、重复度、数量是否达标。数据处理脚本不仅生成标签,还会评估自动标注质量是否可接受、X-AnyLabeling 工件是否生成、YOLO 数据集结构是否可训练。训练脚本不仅启动训练,还区分 dry-run、链路验证和正式训练,以及哪个 best.pt 才能交付。
这些判断如果只靠 AI 看日志,稳定性很差。放进脚本后,每一步都有明确结论:能继续、需要等待、已经阻塞、还是应该回退。AI 只需要读取这个结论,再协调下一步。
6. 总控 Agent 的作用
阶段拆开之后,需要有一个角色把它们串联起来——这就是总控 Agent。它不直接处理图片,不直接修改标签,也不直接改动模型结果。它只做几件事:记录当前运行状态,调用对应阶段脚本,读取统一 JSON 报告,根据 blocker 判断问题归属,决定下一步是继续、等待还是回退。
总控 Agent 更像一个流程调度者。项目越大,越不能让它随意发挥——要给它轨道,让它沿着轨道推进。
7. 这件事对团队有什么启发
这个 YOLO26 项目只是一个例子。真正有价值的是背后的 AI 协作方式。过去使用 AI,更多是点状提效:写个脚本、补个参数、解释个报错。但当任务变成复杂长流程时,只会写代码远远不够。还需要设计:阶段边界、输出标准、状态恢复、质量门禁、责任回退、最终验收。
这套方式的价值在于:它比编写更长、更复杂的提示词更可靠。
8. 结论
这次 YOLO26 训练实践带来的最大启发是:如果没有边界,AI 会乱;如果没有统一输出,AI 会猜;如果只有一个大 Skill,AI 会被长文本拖住;如果只靠文字约束,AI 仍然可能越界。
更可行的方式是:
多个薄 Skill 负责引导,强脚本负责执行和判断,统一 JSON 负责状态交接,总控 Agent 负责协调。



