摘要
在数据中台建设中,异构数据集成这件事,说它是耗时最长、不确定性最高的环节,应该不会有人反对。这篇文章打算从架构层面重新审视这个问题,并提出一个核心原则:采集与治理并行。具体来说,我们会重点讨论治理模块如何解耦、旁路监测怎么落地、以及规则嵌入数据管道这三条关键技术路径。不聊特定厂商的实现,只聚焦架构层面“应该怎么做”的通用设计方法,希望能给企业技术决策者和架构师提供一个可参考的框架。
一、问题的架构层面审视
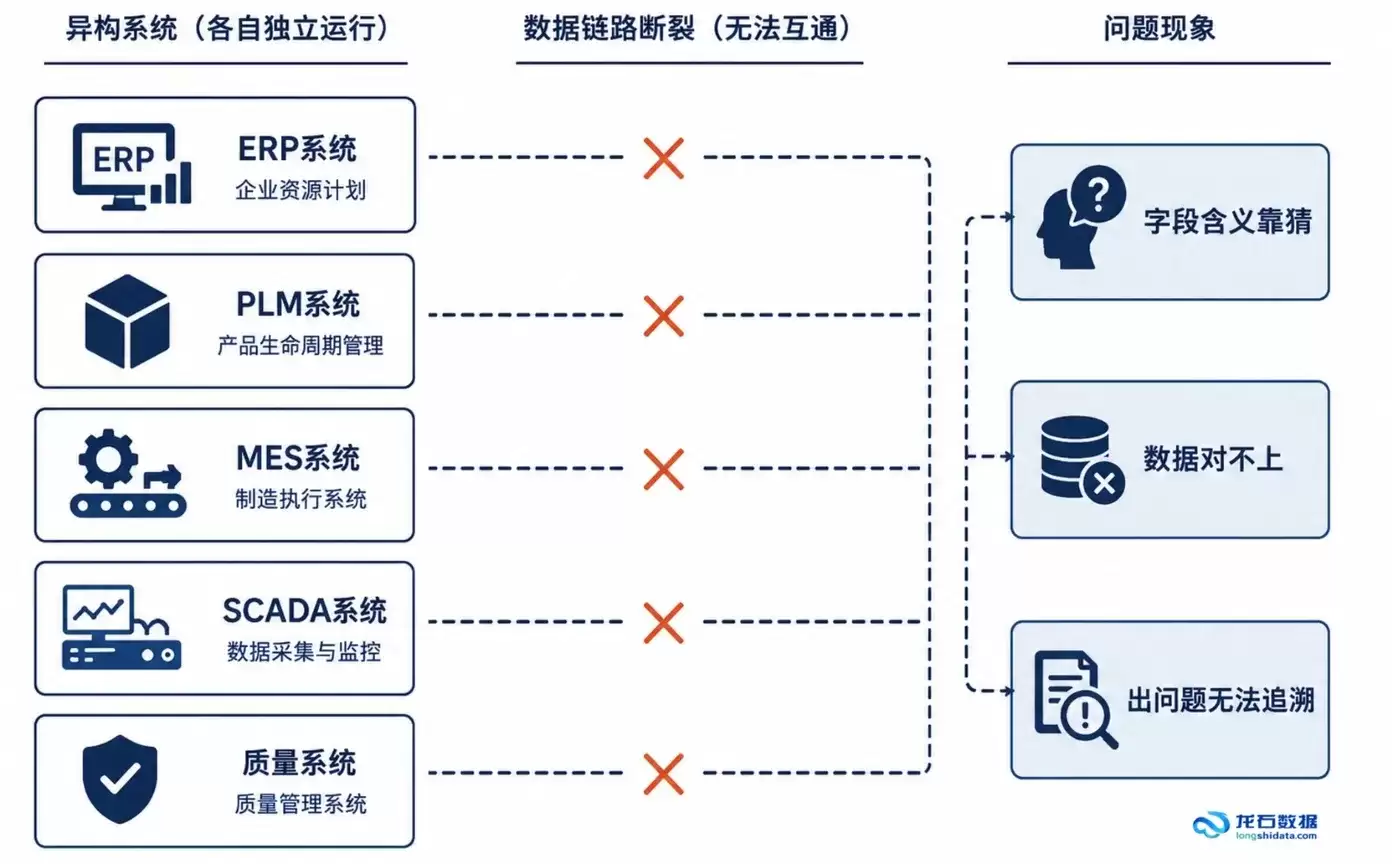
1.1 异构数据源不是技术问题,是架构复杂度问题
企业IT环境里,异构数据源是个既定事实。Oracle、MySQL、SQL Server、PostgreSQL,再加上各种国产数据库、SaaS系统的API、消息队列的数据流——一个中等规模的企业,通常要管理5到15套异构系统的数据。
从架构角度看,这带来的其实是连接管理的组合复杂度。每增加一类数据源,不只是多一个连接器那么简单。你需要维护独立的驱动依赖、处理不同的字符集编码策略、配置不同的连接池参数和容错重试机制。当数据源规模突破两位数时,连接管理的运维成本就成了一道绕不过去的架构命题。
1.2 语义对齐是异构集成的核心瓶颈
更深层的问题在于跨系统的语义一致性。ERP系统里的“客户名称”、CRM系统里的“客商名称”、财务系统里的“往来单位”——它们指向同一个业务实体,但字段命名、数据类型、长度约束却各不相同。一个核心业务表可能包含数十甚至上百个字段,语义对齐需要业务人员的确认和参与,这部分工作无法完全靠技术手段自动化。
这揭示了一个关键的架构洞见:异构数据集成本质上不是一个传输问题,而是一个语义治理问题。
1.3 数据流转与质量管控的传统矛盾
传统架构里,数据采集和质量管控通常是串行关系——数据先进来,后面再治理。这种模式在实践中缺陷挺明显:数据一旦入库并被下游任务消费,质量问题就会迅速扩散到报表、指标和分析结果中。等发现的时候,已经很难区分哪些数据是可信的、哪些已经受到了污染。
二、架构设计原则
2.1 核心原则:采集与治理并行
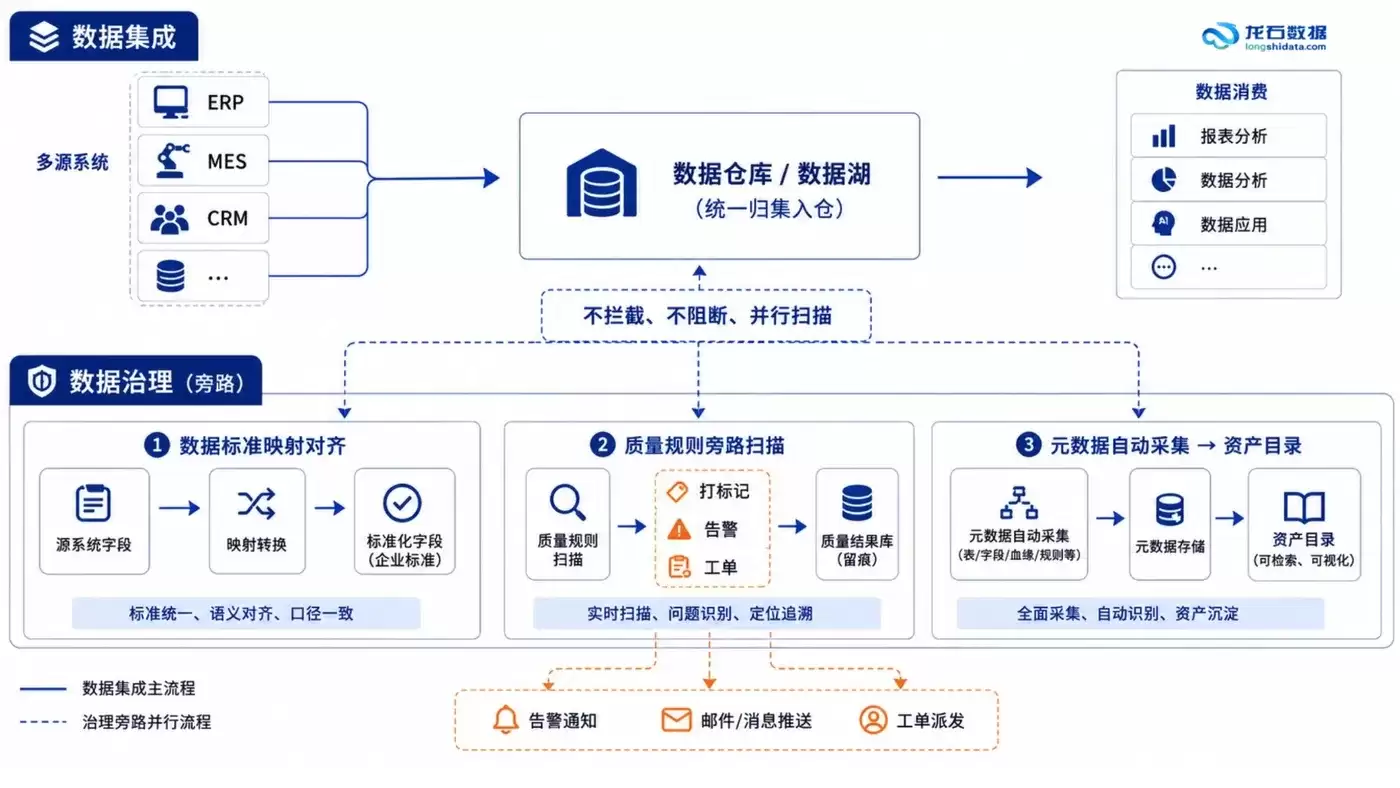
异构数据集成架构的核心设计原则很明确:数据的采集层与治理层应当解耦且并行运作,而不是先后串行。这意味着架构要在数据入库的同时,就启动标准映射、元数据采集和质量扫描。
2.2 治理模块解耦:采集链路保持轻量
在采集链路中,不宜嵌入复杂的转换逻辑或校验阻断能力。数据应以原始形态入库——这个设计选择的理由有三:一是保留原始数据有利于事后审计追溯;二是避免因中间环节的逻辑错误导致问题排查困难;三是可以降低采集链路的复杂度,提升系统稳定性。
治理动作——语义对齐、格式标准化、编码转换——应该在独立的治理层完成,以对照关系(而不是覆盖写)的形式建立标准字段与源字段的映射。这意味着:原始数据始终保留,治理结果作为附加层叠加在上面。
2.3 分层解耦的具体表现
| 层次 | 职责 | 对数据流的影响 |
|---|---|---|
| 采集层 | 多源连接、数据接入、原样落库 | 不拦截、不转换数据流 |
| 治理层 | 标准映射、元数据采集、血缘构建 | 并行运行,不影响数据流 |
| 质量层 | 质量规则扫描、异常标记、告警 | 旁路模式,不阻塞数据流 |
| 资产层 | 数据目录、资产检索、权限管控 | 消费治理层和质量层的产出 |
三、三项关键技术路径
3.1 路径一:治理能力组件化
数据标准管理、元数据管理、主数据管理——这三项治理能力应当作为独立的架构组件来设计,而不是嵌入到采集链路中。
标准管理组件承担字段到业务语义的映射对齐职责。它在治理层维护标准字段与各源系统字段的对照关系表,不修改源数据。当源系统字段发生变更时,只需更新对照关系,不影响已入库的数据。
元数据管理组件实现自动化的元数据采集——表结构、字段定义、分区信息等在数据入库时自动记录。更关键的是构建数据血缘关系:记录每一份数据从哪个源系统来、经过了哪些处理、被哪些下游任务消费。
主数据管理组件解决的是跨系统的实体唯一标识问题——同一客户、同一物料、同一供应商在不同系统中的编码,如何统一识别和关联。
这三者的共同特征是:以元数据驱动的方式运行,通过声明式配置而非硬编码来实现治理逻辑。
3.2 路径二:旁路监测架构模式
质量管控不应嵌入到数据流转的主链路上。正确的架构模式是“旁路监测”——质检服务作为独立组件,通过订阅数据变更事件来触发质量扫描。
这一模式的技术特征很清晰:
- 异步非阻塞:质检任务与数据写入并行执行,互不依赖。
- 精确到记录的异常定位:扫描结果定位到“哪个系统的哪张表的哪个字段的哪些记录”,而不是粗粒度的表级报告。
- 分级响应策略:支持标记、告警、工单、阻断等多种异常处理方式,按场景灵活选择。
- 声明式规则配置:质量规则以配置形式定义,支持字段级、表级、跨表级三种粒度。
旁路监测模式的架构价值在于:它在保持数据流转效率的前提下,实现了质量问题的可发现性和可追溯性——这两个在传统架构中很难兼得的目标。
3.3 路径三:规则嵌入数据管道
在旁路监测的基础上,还可以进一步将质量规则嵌入到数据管道的生命周期中。
具体做法是:数据管道在启动前,检查所涉及数据源的最新质量扫描结果。如果存在未修复的严重问题,管道可以选择延迟执行或跳过受影响的数据分区。这相当于在数据管道的调度层面增加了一层质量感知的前置校验。
此外,在数据接入前对源端数据做一轮预检,也是一种可选的增强做法。预检能帮助团队在正式接入前摸清源端数据质量底数,有问题的可以推动源头系统先修复。这不改变主架构,而是作为质量前置的可选环节。
四、架构设计的权衡
异构数据集成架构设计中,有几个关键权衡需要明确:
灵活性与一致性的平衡。 采集链路保持轻量和通用性,治理层则承载业务特定的语义逻辑。这种分层分离,让架构在适应不同业务场景的同时,保持核心链路的稳定性。
实时性与完整性的平衡。 批量集成可以提供更全面的数据质量校验,而实时集成则要求更轻量的校验策略。架构需要同时支持两种模式,让业务需求来决定数据时效性,而不是让架构限制业务选择。
自动化与人工判断的平衡。 字段映射的自动化,受限于跨系统语义差异的复杂性——工具可以处理技术层面的适配,但业务语义的确认仍然需要人工参与。架构设计应当将人工判断定位为治理流程的标准环节,而不是例外情况。
五、总结
异构数据集成问题,本质上是一个架构设计问题,而不是工具选型问题。核心要点可以归结为:
- 采集与治理分层解耦: 采集链路保持轻量,治理能力以独立组件并行运作。
- 旁路监测保障质量: 质检不与数据流转争抢资源,但确保问题可发现、可定位、可追溯。
- 元数据驱动的声明式治理: 标准映射、血缘构建、规则校验均以配置而非代码驱动,降低长期维护成本。
衡量一个数据中台集成架构是否成熟,不在于它能接多少种数据源,而在于每接入一个新的数据源,治理能力是否能同步跟上——这才是异构数据集成的架构性解法。
参考来源
[1] 国家标准化管理委员会.《数据管理能力成熟度评估模型》(GB/T 36073-2025, DCMM 2.0). 国家标准全文公开系统.
[2] 国家标准化管理委员会.《信息技术 数据质量评价指标》(GB/T 36344-2018). 国家标准全文公开系统.
[3] DAMA International.《DAMA数据管理知识体系指南》(DAMA-DMBOK). dama.org.




