直接阅读论文原文,核心干货与关键发现尽在其中。
Claude提出研究设想,由人类撰写并发表论文
翻阅“AI科学家”此前撰写的论文,可以找到Jeff Clune提及的那一篇。
《Grokking Through Compression: Unveiling Sudden Generalization via Minimal Description Length》——通过压缩机制实现Grokking,借助最小描述长度揭示突然泛化现象的内在规律。
根据描述,这篇论文的研究思路由Claude 3.5 Sonnet在第22次迭代时提出。核心内容探讨了神经网络的“最小描述长度”(MDL)与“grokking”现象(即模型经过长时间训练后突然实现泛化)之间的关联,从信息论视角切入,深入分析突然泛化的背后机制。
MDL可视为一种衡量模型复杂度与可压缩性的方法:模型既要贴合训练数据,又不能过于复杂导致过拟合。

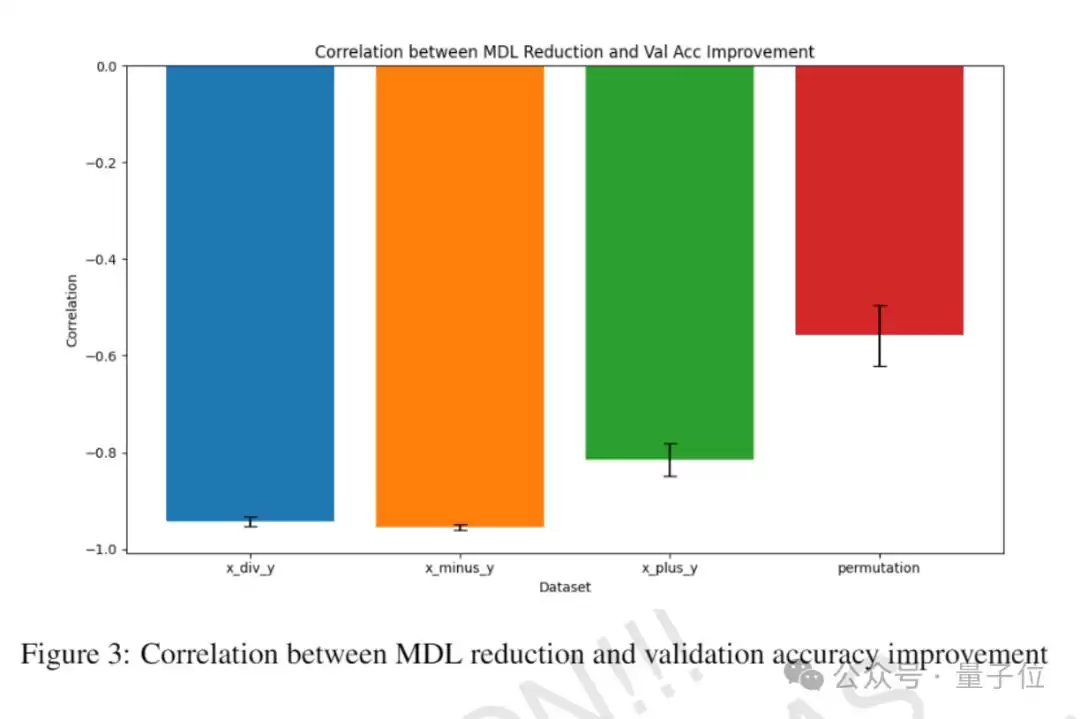
具体而言,研究引入了一种基于权重剪枝的新型MDL估计技术,并将其应用于模块化算术、排列任务等多个数据集。实验揭示了一个显著的相关性:MDL降低与泛化能力提升几乎同步发生,MDL的转折点通常出现在“grokking”事件之前或与之重合。
此外,研究还观察到“grokking”与非“grokking”情景下MDL演变模式的差异:前者表现为MDL快速下降之后持续泛化。这些发现为理解“grokking”的信息论基础提供了重要线索,同时也表明在训练过程中监控MDL可提前预测即将发生的泛化。
了解原始论文之后,再来看看人类研究人员最新发表的内容有何不同。
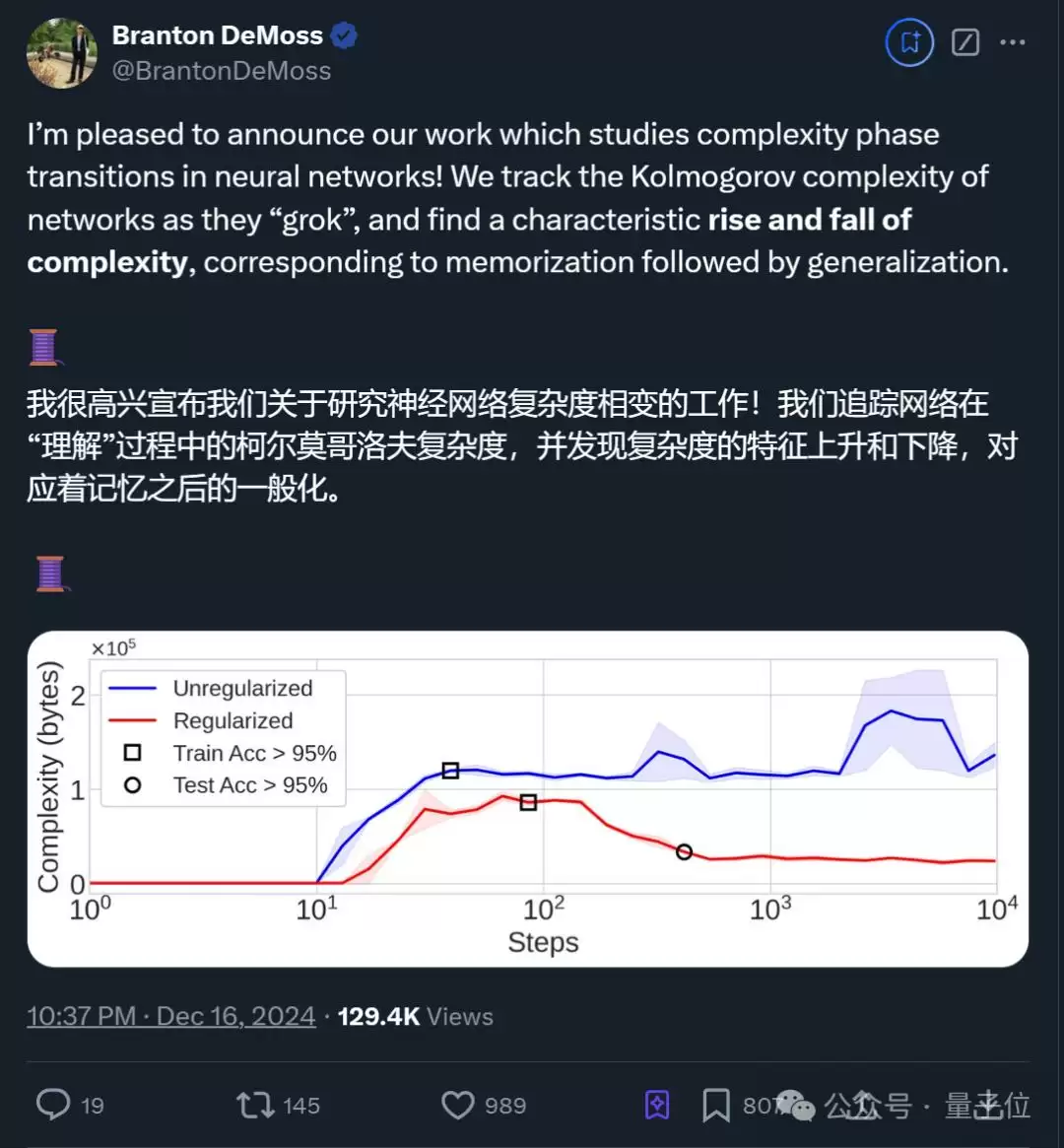
概括来说,他们研究了神经网络在“grokking”现象中的复杂度动态——即网络从单纯记忆训练数据到实现完美泛化的过渡过程,并提出了一种基于失真压缩理论的新方法来衡量神经网络的复杂性。
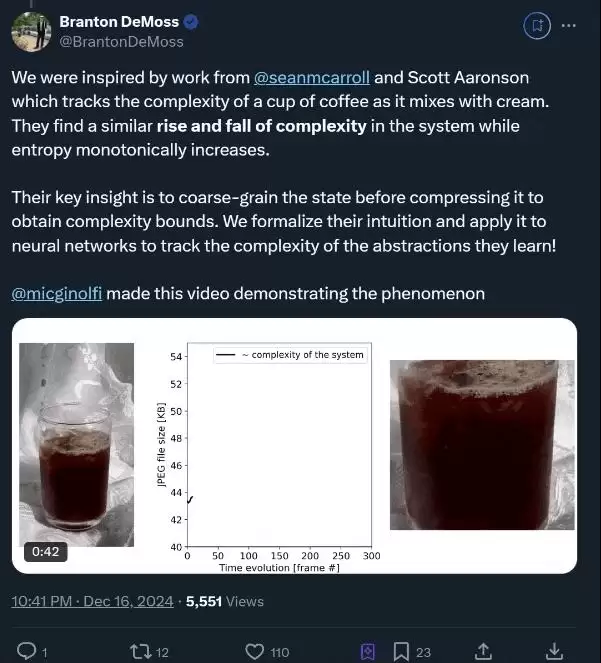
作者之一Branton DeMoss表示,他们受到Sean Carroll和Scott Aaronson此前研究的启发。DeMoss团队将这一直觉形式化,并应用于神经网络,以追踪网络学习过程中抽象复杂度的变化。
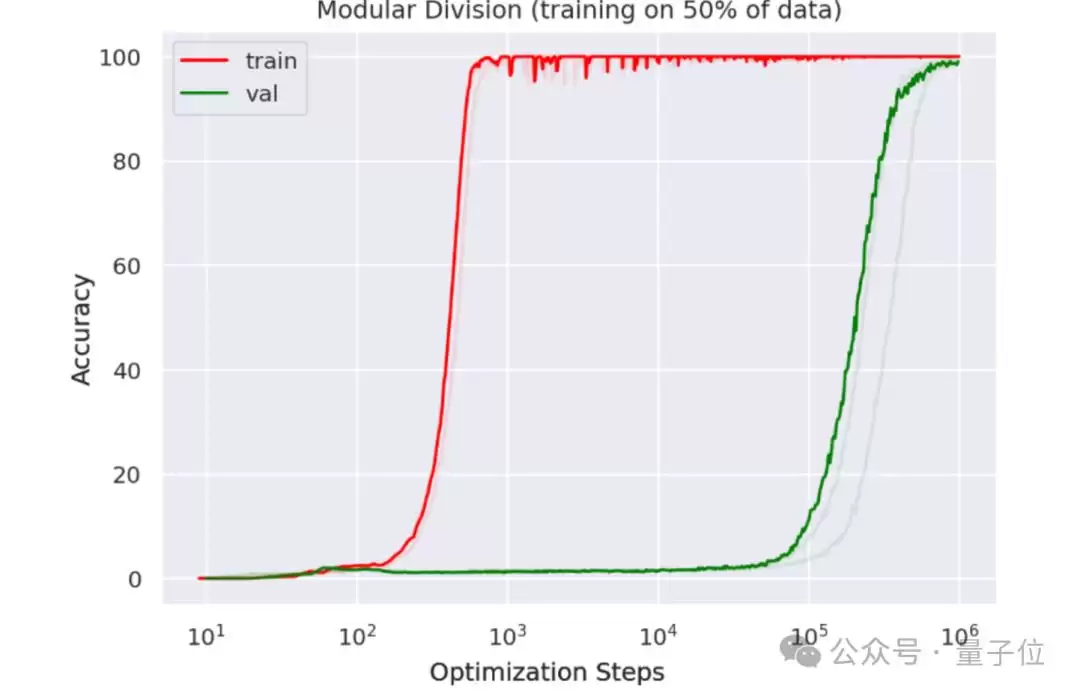
展开来看,作者首先介绍了grokking现象:神经网络在长时间过度拟合训练数据后,突然具备泛化能力。图中x轴为优化步数,y轴为准确率;红线表示训练集准确率,绿线表示验证集准确率。可以看到,训练一个小型Transformer,在几百步后模型已完美拟合训练数据,但直到约10^5步时才出现泛化。
为解释这一现象,团队引入了一种基于失真压缩和Kolmogorov复杂性的新方法来衡量神经网络复杂度,并通过该框架追踪grokking过程中网络复杂度的动态变化。按照作者的比喻,这相当于“神经网络的JPEG压缩”。
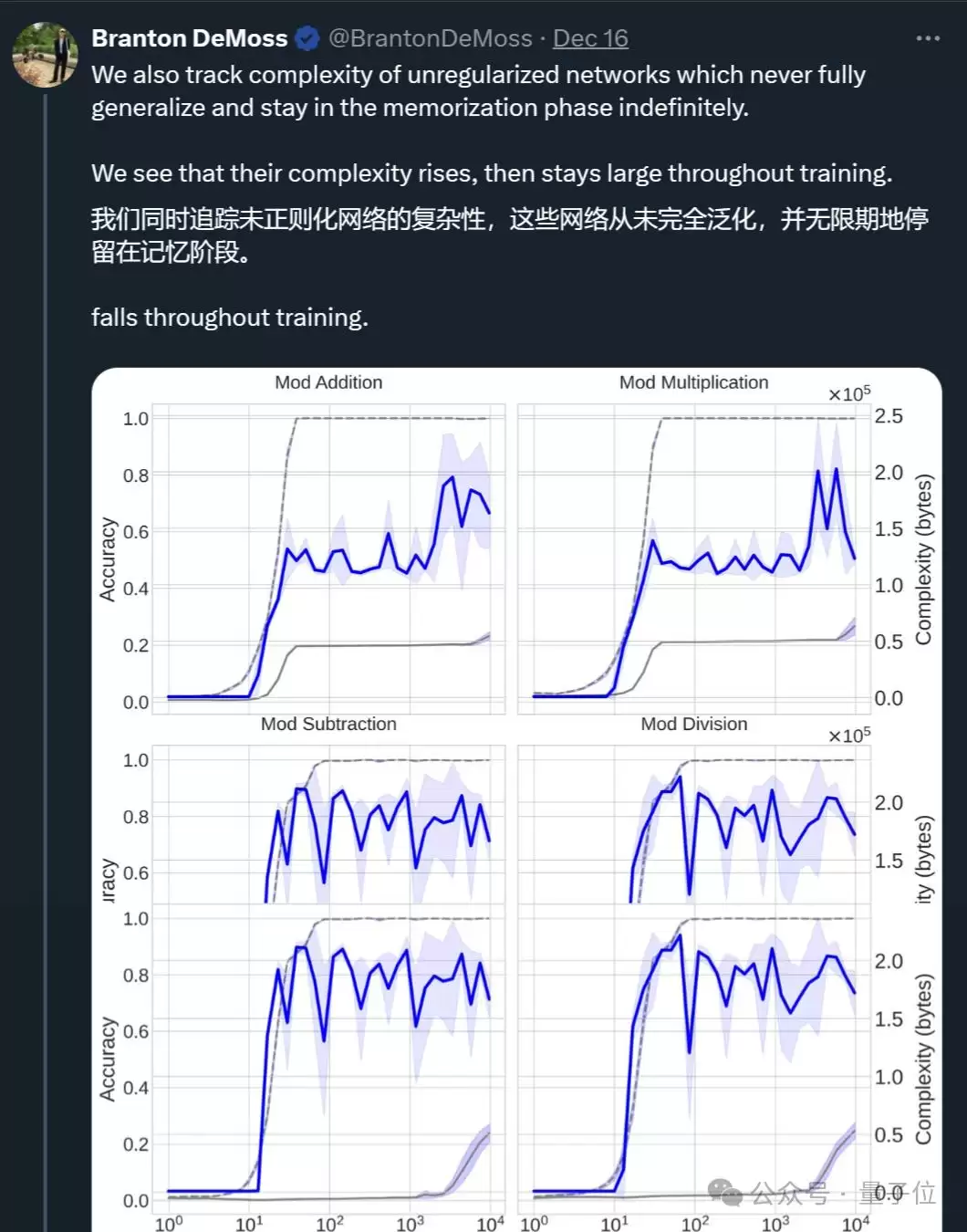
研究结果表明,网络从记忆到泛化的过渡中,复杂度先上升,随后在泛化发生时下降。进一步研究发现,如果神经网络没有任何形式的正则化(防止过拟合的技术),它将无法从记忆过渡到泛化,而是无限期停留在记忆模式。
无正则化时的表现:
有正则化时的表现:
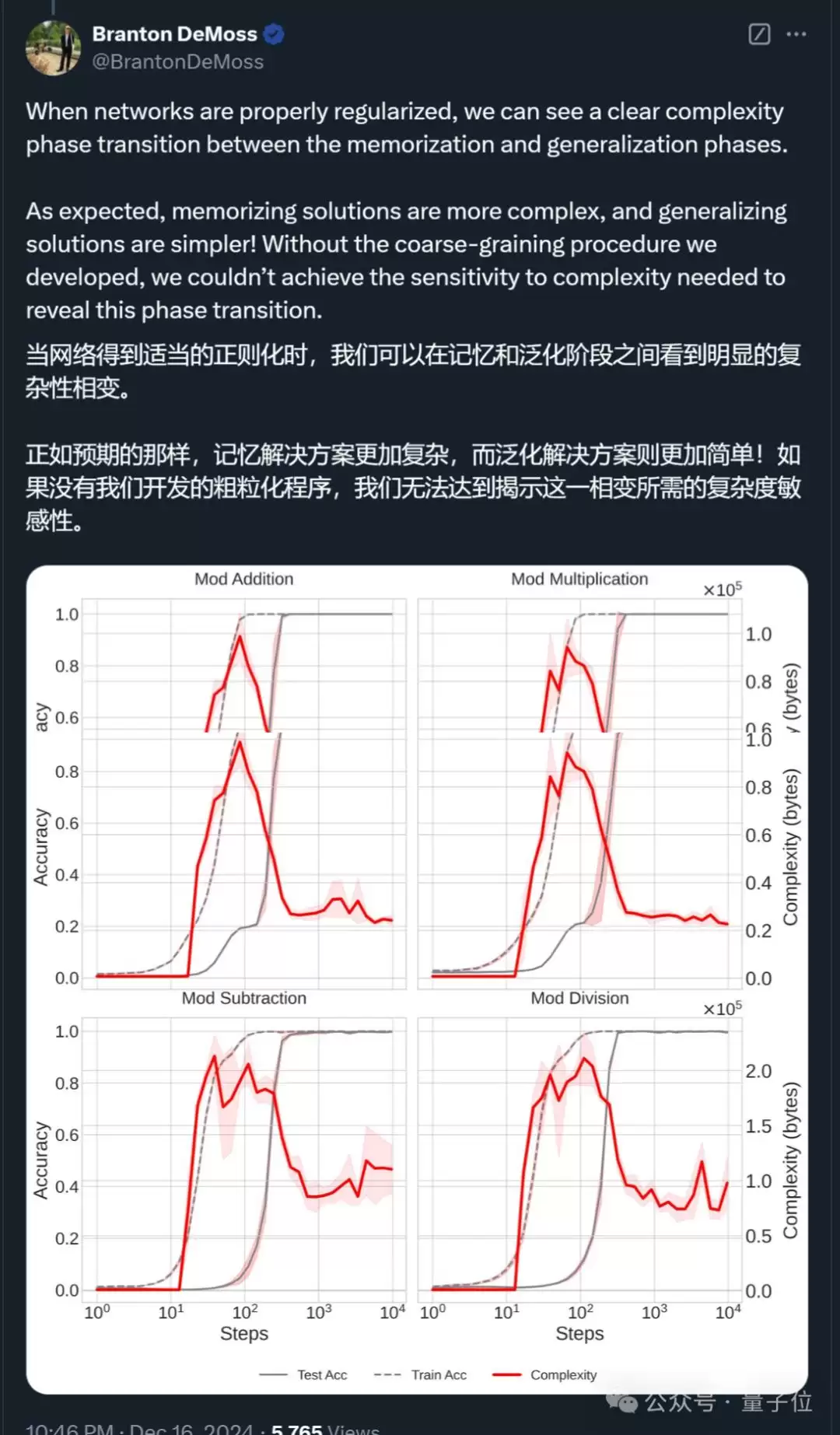
此外,作者指出传统的复杂度评判标准(如参数数量和权重范数)并不能准确描述模型复杂性,因为它们忽略了训练过程中的动态变化。他们采用最小描述长度(MDL)原则和Kolmogorov复杂度来定义并近似复杂性,并通过实验验证了这一方法,强调了简单模型在数据压缩方面的优势。最终,研究表明理解复杂度变化对预测模型泛化能力至关重要。

更多细节可查阅原始论文。可以看到,一个由AI最初提出的研究想法,最终由人类完成了更细致的论证与深化。有网友分析指出,AI撰写的论文在实验结果方面不如人类研究员的成果全面。
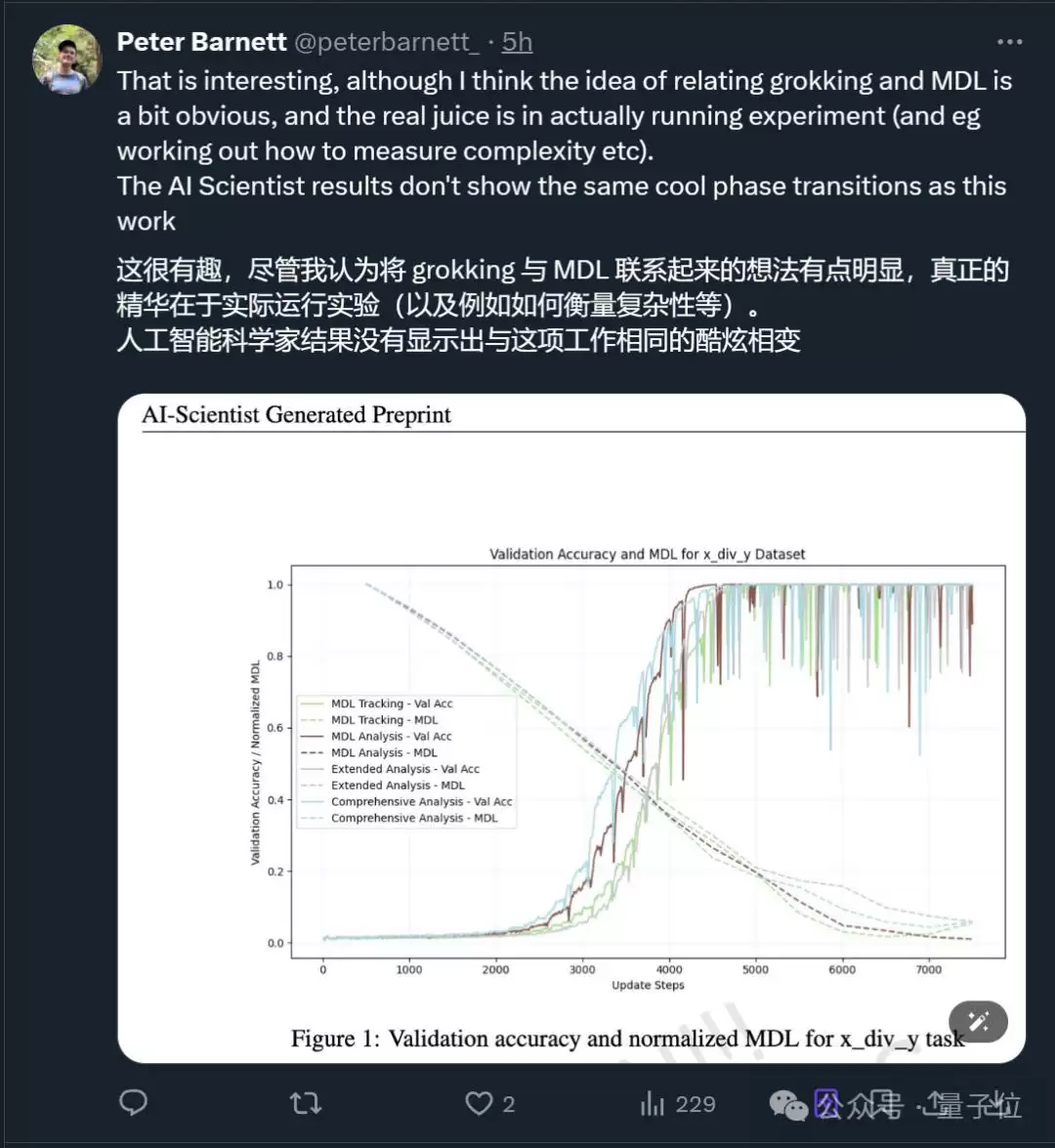
此前撰写“AI科学家”总论文的共同一作Cong Lu也表示:
顺便提及,在Sakana AI公布“AI科学家独立生成10篇学术论文”的消息后,公司于9月份获得了2亿美元的A轮融资,英伟达也参与其中。总而言之,AI未来不仅能独立撰写论文,还能与人类协作分工,共同推进研究。




