前言:
在C++开发中,我们对基本数据类型的边界(如
int、float、double的内存占用与精度)以及位运算早已烂熟于心。可一旦切换到数据库领域,尤其是 MySQL,数据类型的选型和底层表现就成了另一个维度的关键问题。选错了类型,轻则浪费磁盘和内存,重则在高并发下让金融计算精度失真,或者直接因为越界插入而报错。这篇文章就从底层原理出发,结合越界测试,把 MySQL 数据类型系统彻底讲透。
一. MySQL 数据类型分类
MySQL 的数据类型体系相当丰富,大体上可以分成四大核心板块:
| 分类 | 核心类型 | 适用场景 |
|---|---|---|
| 数值类型 | BIT、TINYINT、INT、BIGINT、FLOAT、DECIMAL | 存储数字(年龄、金额、计数等) |
| 字符串类型 | CHAR、VARCHAR、TEXT、BLOB | 存储文本(姓名、地址、大文本、二进制数据) |
| 日期时间类型 | DATE、DATETIME、TIMESTAMP | 存储时间(生日、创建时间、时间戳) |
| 特殊字符串 | ENUM(枚举)、SET(集合) | 固定选项(性别、爱好、状态等) |
| 二进制类型 | BLOB | 存储图片、文件等二进制数据 |

二. 数值类型
数值类型是日常用得最多的,核心关注点在于范围和精度——范围溢出、精度丢失,都是线上事故的常见源头。
2.1 整数类型(BIT/TINYINT/INT/BIGINT)
整数类型按字节数分为五档,每档都支持 UNSIGNED(无符号)修饰,默认是有符号的:
| 类型 | 字节 | 最小值 (带符号 / 无符号) | 最大值 (带符号 / 无符号) |
|---|---|---|---|
| TINYINT | 1 | -128 / 0 | 127 / 255 |
| SMALLINT | 2 | -32768 / 0 | 32767 / 65535 |
| MEDIUMINT | 3 | -8388608 / 0 | 8388607 / 16777215 |
| INT | 4 | -2147483648 / 0 | 2147483647 / 4294967295 |
| BIGINT | 8 | -9223372036854775808 / 0 | 9223372036854775807 / 18446744073709551615 |
实战中的关键点:
- 尽量避免使用
UNSIGNED。无符号类型虽然能扩大正数范围,但插入负数会直接报错(比如TINYINT UNSIGNED插入 -1),而且跟有符号类型做混合运算时容易出逻辑上的幺蛾子。与其提心吊胆,不如直接上更大的整数类型——比如用INT代替TINYINT UNSIGNED,或者干脆一步到位用BIGINT。
2.1.1 TINYINT 越界测试与 Unsigned 机制
TINYINT 只占 1 个字节,有符号范围 -128~127,无符号范围 0~255:
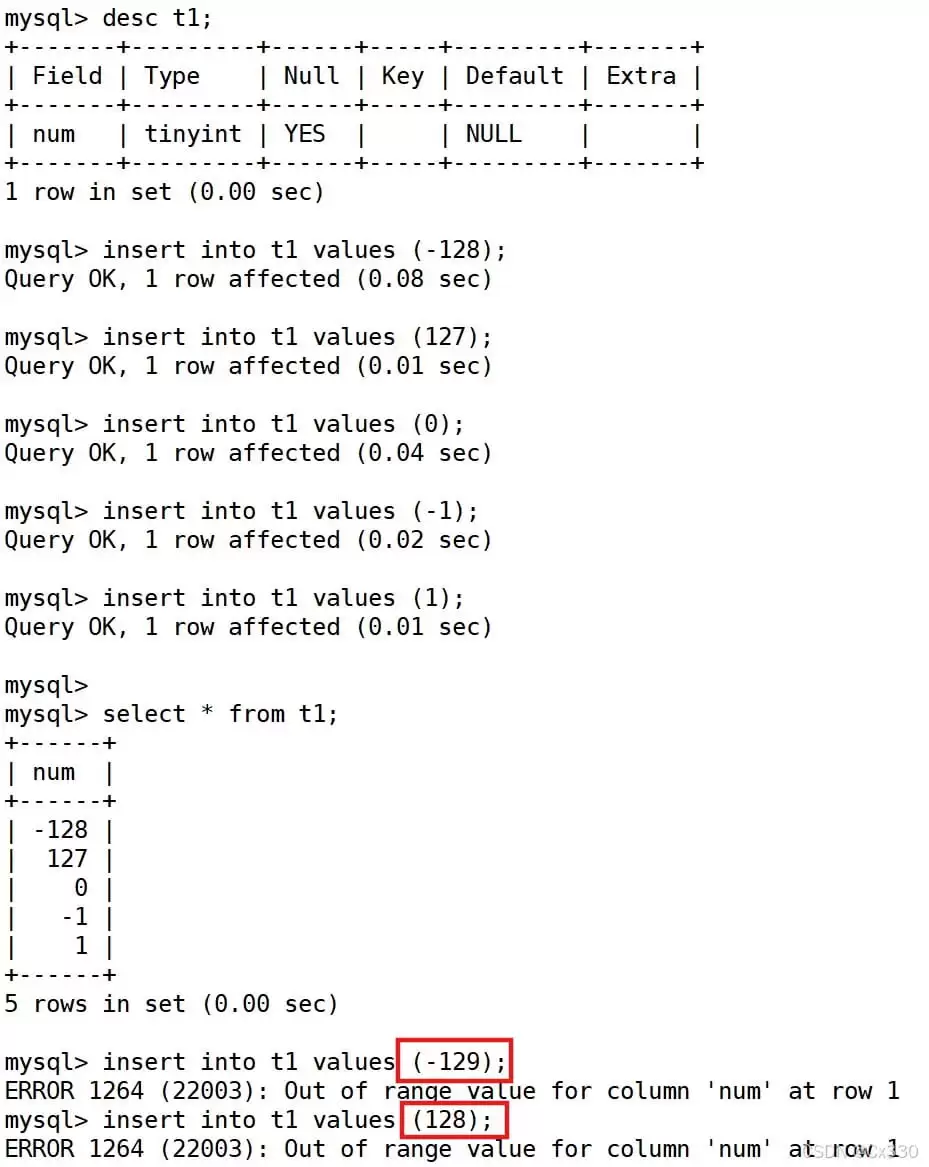
一个值得注意的避坑建议:尽量少用
UNSIGNED。假设你用一个INT UNSIGNED存数据,上限虽然翻了一倍,但如果业务增长远超预期,照样会溢出。还不如在设计之初直接选BIGINT,省得后面在线改表,那叫一个痛苦。
2.2.2 BIT 类型
语法:BIT[(M)],M 表示每个值的位数(Bit),范围 1-64。如果省略 M,默认就是 1 位。
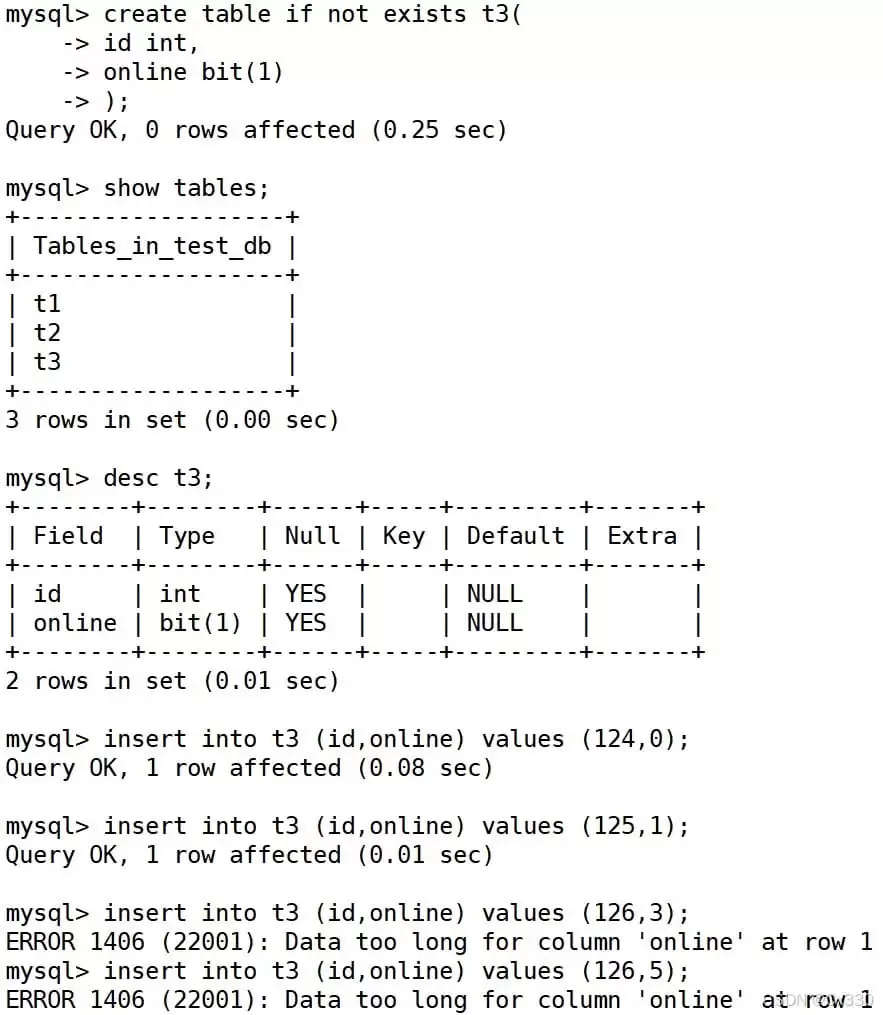
奇妙的 ASCII 显示现象
在终端里查询 BIT 类型时,有时会发现值“神秘消失”或者显示得很奇怪:
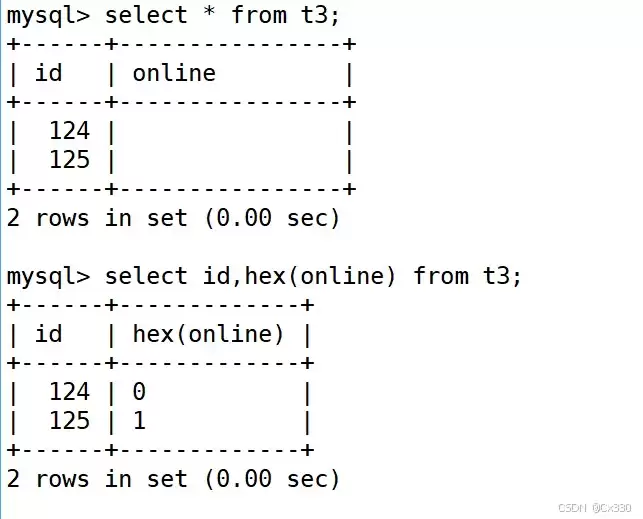
原因并不复杂:BIT 字段在终端显示时,是按照对应的 ASCII 码字符来渲染的。比如下面这个例子:
mysql> insert into tt4 values (65, 65); -- 65 对应的 ASCII 字符是 'A' mysql> select * from tt4; +------+------+ | id | a | +------+------+ | 10 | | | 65 | A | -- 此时显示出了字符 'A' +------+------+
2.1.3 INT/BIGINT 对比测试
-- 1. INT存储手机号(越界测试) CREATE TABLE test_int(phone INT); INSERT INTO test_int VALUES(13800138000); -- 报错:Out of range value for column 'phone' at row 1(INT最大值2147483647 < 13800138000) -- 2. BIGINT存储手机号(成功) CREATE TABLE test_bigint(phone BIGINT); INSERT INTO test_bigint VALUES(13800138000); -- 成功 SELECT * FROM test_bigint; +-------------+ | phone | +-------------+ | 13800138000 | +-------------+
2.2 小数类型(FLOAT/DOUBLE/DECIMAL)
2.2.1 FLOAT 类型
- 语法:
FLOAT[(M, D)] [UNSIGNED],M 指定显示长度(含小数点),D 指定小数位数。占用 4 字节。 - 截断与四舍五入测试:
-- 定义 float(4,2),表示范围在 -99.99 到 99.99 之间 mysql> create table tt6(id int, salary float(4,2)); mysql> insert into tt6 values (100, -99.99); -- 边界插入 mysql> insert into tt6 values (101, 99.991); -- 多出的一位小数四舍五入被拿掉 mysql> select * from tt6; +------+--------+ | id | salary | +------+--------+ | 100 | -99.99 | | 101 | 99.99 | +------+--------+
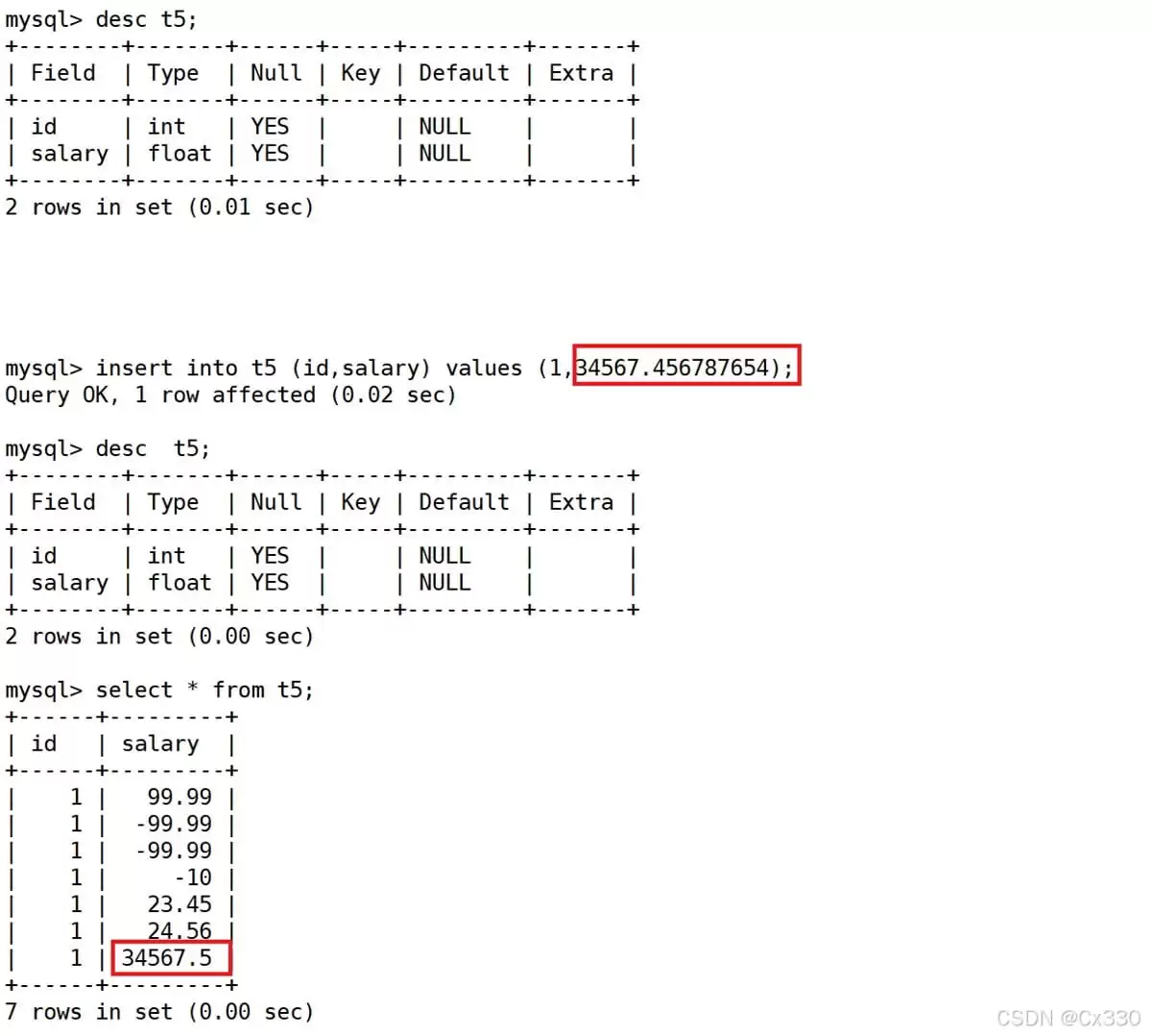
不妨思考一下:如果定义为 FLOAT(6,3) 有符号,它的数值范围是多少?答案是 -999.999 到 999.999。如果换成 FLOAT(4,2) UNSIGNED,范围就是 0 到 99.99(负数会被拦截)。
2.2.2 DECIMAL 类型与精度大PK
商业计算对精度要求极高,这时候就得请出 DECIMAL 了。
- 语法:
DECIMAL(M, D) [UNSIGNED] - 限制:整数最大位数 M 为 65,小数最大位数 D 为 30。如果 D 省略默认为 0,M 省略默认为 10。
来看一组真实的精度对比:
mysql> create table tt8 (id int, salary float(10,8), salary2 decimal (10,8)); mysql> insert into tt8 values (100, 23.12345612, 23.12345612); mysql> select * from tt8; +------+-------------+-------------+ | id | salary | salary2 | +------+-------------+-------------+ | 100 | 23.12345695 | 23.12345612 | +------+-------------+-------------+ -- 瞧!float(10,8) 存入的值被失真变成了 23.12345695!而 decimal(10,8) 依然保持绝对精确。
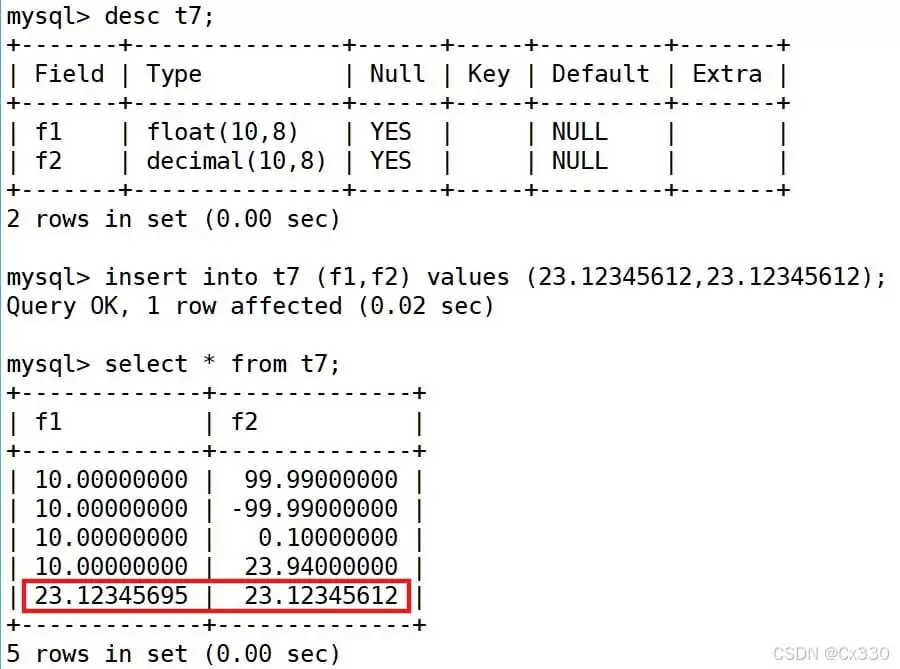
原因很简单:FLOAT 是单精度浮点数,有效精度大约只有 7 位(C++ 里也一样)。凡是跟钱、科学计算打交道的场景,直接上 DECIMAL 就对了。
三. 字符串类型
MySQL 的字符串处理主要有两种策略:定长和变长。
3.3.1 CHAR(L)
- 特点: 固定长度字符串,单位是字符(注意不是字节,汉字和英文字母都算一个字符),L 最大可取 255。
mysql> create table tt9(id int, name char(2)); mysql> insert into tt9 values (100, 'ab'); -- 成功 mysql> insert into tt9 values (101, '中国'); -- 成功(存放了两个汉字字符) -- 如果超过 255 mysql> create table tt10(id int, name char(256)); ERROR 1074 (42000): Column length too big for column 'name' (max=255); use BLOB or TEXT instead

3.3.2 VARCHAR(L)
- 特点: 可变长度字符串,L 表示最大字符长度。
- 底层上限原理(重点): MySQL 的单行最大限制是 65535 字节。而
VARCHAR的实际有效存储字节上限是 65532 字节(因为需要用 1~3 个字节来记录实际数据长度)。 - 这意味着它的最大字符长度受字符集编码的直接影响:
- utf8 编码:每个字符最多占 3 字节,所以最大 L = 65532 / 3 ≈ 21844。
- gbk 编码:每个字符最多占 2 字节,最大 L = 65532 / 2 = 32766。
-- 验证 utf8 下 L=21845 越界: mysql> create table tt11(name varchar(21845)) charset=utf8; ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBS, is 65535. -- 验证 L=21844 成功创建: mysql> create table tt11(name varchar(21844)) charset=utf8; Query OK, 0 rows affected (0.01 sec)
主流编码下的字节数
| 编码 | 一个汉字的字节数 | 说明 |
|---|---|---|
| UTF-8 | 3 字节 | 最通用的编码,网页、大多数数据库默认 |
| GBK / GB2312 | 2 字节 | 简体中文环境常用,Windows 系统常见 |
| UTF-16 (LE/BE) | 2~4 字节 | 多数常用汉字占 2 字节,生僻字可能占 4 字节 |
3.3.3 CHAR 与 VARCHAR 空间效率大比拼
假设在 utf8 编码下,我们来对比一下实际存储情况:
| 实际存储内容 | CHAR(4) 占用空间 | VARCHAR(4) 占用空间 |
|---|---|---|
abcd |
4 * 3 = 12 bytes | 4 * 3 + 1 (长度信息) = 13 bytes |
A |
4 * 3 = 12 bytes (浪费空间) | 1 * 3 + 1 (长度信息) = 4 bytes (按需开辟) |
Abcde |
数据超长,拦截报错 | 数据超长,拦截报错 |
经典选型建议(如何抉择?)
- 选 CHAR(定长): 适用于数据长度变化极小甚至固定的列,比如身份证号(18位)、手机号(11位)、MD5 密文、UUID。虽然会浪费一些磁盘空间,但由于是物理连续的内存块,读写效率极高。
- 选 VARCHAR(变长): 适用于数据长度存在明显差异的列,比如姓名、家庭地址、个人简介。在最大长度范围内,“用多少,开辟多少”,能有效节约磁盘空间。
四. 日期时间类型
日常开发中常用的日期时间类型主要有三种:
| 类型 | 格式 | 占用字节 | 特点 |
|---|---|---|---|
| DATE | yyyy-mm-dd |
3 字节 | 只存储日期 |
| DATETIME | yyyy-mm-dd HH:mm:ss |
8 字节 | 表示范围从 1000 年到 9999 年 |
| TIMESTAMP | yyyy-mm-dd HH:mm:ss |
4 字节 | 时间戳。插入或更新数据时会自动刷新为当前时间 |
4.1 TIMESTAMP 自动更新测试
-- 1. 创建表
mysql> create table birthday (t1 date, t2 datetime, t3 timestamp);
-- 2. 仅插入 t1 和 t2
mysql> insert into birthday (t1, t2) values('1997-7-1', '2008-8-8 12:1:1');
mysql> select * from birthday;
+------------+---------------------+---------------------+
| t1 | t2 | t3 |
+------------+---------------------+---------------------+
| 1997-07-01 | 2008-08-08 12:01:01 | 2017-11-12 18:28:55 | -- t3(时间戳) 自动补上当前时间
+------------+---------------------+---------------------+
-- 3. 更新 t1 的数值
mysql> update birthday set t1='2000-1-1';
mysql> select * from birthday;
+------------+---------------------+---------------------+
| t1 | t2 | t3 |
+------------+---------------------+---------------------+
| 2000-01-01 | 2008-08-08 12:01:01 | 2017-11-12 18:32:09 | -- 更新操作会同步刷新时间戳!
+------------+---------------------+---------------------+
五. ENUM 与 SET 类型
这两个类型本质上是有限制、带约束的字符串类型。
5.1 特点
- ENUM(单选): 只能在候选集合里选一个值。底层用数字编号(1, 2, 3...)存储以节省空间,最多支持 65535 个选项。
- SET(多选): 可以选择候选集合中任意多个值,各成员间用
,隔开。底层也采用数字存储,但和 Linux 文件权限类似,用比特位(1, 2, 4, 8, 16...)来映射组合。最多支持 64 个选项。
⚠️ 避坑指南:实际业务中不建议在
INSERT时用数字标号代替文本,因为可读性太差,维护起来很头疼。
5.2 案例实战:投票调查表
我们来创建一个问卷投票表:
mysql> create table votes (
username varchar(30),
hobby set('登山','游泳','篮球','武术'),
gender enum('男','女'));
5.3 数据插入与基础查询
-- 使用文本插入
mysql> insert into votes values('雷锋','登山,武术','男');
-- 混用数字代号插入('女' 对应的 enum 下标为 2)
mysql> insert into votes values('Juse','登山,武术', 2);
mysql> select * from votes where gender=2;
+----------+---------------+--------+
| username | hobby | gender |
+----------+---------------+--------+
| Juse | 登山,武术 | 女 |
+----------+---------------+--------+
核心避坑:如何查询集合中包含某一项的人?
假设表里有这些数据:
+------------+---------------+--------+ | username | hobby | gender | +------------+---------------+--------+ | 雷锋 | 登山,武术 | 男 | | Juse | 登山,武术 | 女 | | LiLei | 登山 | 男 | | HanMeiMei | 游泳 | 女 | +------------+---------------+--------+
如果用 = 去匹配“登山”的人:
mysql> select * from votes where hobby='登山'; +----------+-------+--------+ | username | hobby | gender | +----------+-------+--------+ | LiLei | 登山 | 男 | +----------+-------+--------+
问题: 结果只查出了李雷,因为等号 = 做的是完整字符串精确匹配。像雷锋、Juse 这种还喜欢其他运动的人直接被过滤掉了。
正确姿势:使用 find_in_set 函数
在 MySQL 中,要判断集合中是否包含某个元素,得用内置函数 find_in_set(sub, str_list):
- 原理:如果
sub存在于以逗号分隔的字符串str_list中,返回元素下标(从1开始),否则返回 0。
mysql> select find_in_set('a', 'a,b,c'); -- 返回 1
mysql> select find_in_set('d', 'a,b,c'); -- 返回 0
-- 完美查询出所有爱好包含 "登山" 的人:
mysql> select * from votes where find_in_set('登山', hobby);
+----------+---------------+--------+
| username | hobby | gender |
+----------+---------------+--------+
| 雷锋 | 登山,武术 | 男 |
| Juse | 登山,武术 | 女 |
| LiLei | 登山 | 男 |
+----------+---------------+--------+
结语
从底层的位运算(BIT、SET)到高精度的 DECIMAL,可以看到 MySQL 的数据类型设计和 C/C++ 的内存对齐、结构体映射高度相通。合理规划字段类型,不仅能省下大量存储空间,更能让后续的越界、精度异常 Bug 无机可乘。




