业务数据出现问题的时候,最常见的错误并非 SQL 语句写不出来,而是过快地执行了 update 操作。尤其在数据导入场景中,表面上看起来只是几条金额缺失的记录,但一旦条件设置得不够严谨,旧批次、退款单、未支付单都可能会被牵连进来。在 KingbaseES 中修复这类数据,语法本身并不复杂,真正的挑战在于如何将影响范围牢牢控制住。
这里用一组订单数据来模拟一个非常典型的现场:某个导入批次中,部分已支付订单的金额意外变为了 0。为了方便演示,修复值统一设定为 199.00,这并不代表真实业务规则,只是为了让整个修复过程更加清晰。整件事本质上只围绕三个核心问题:到底要修改哪些行,万一改错了如何撤销,留下的操作记录能否与影响行数对应上。
先把数据角色分清
首先准备两张表,一张存放订单,另一张用于记录修复操作。t_scene_order 是本次需要处理的业务表,t_scene_fix_log 用来记录修复动作。建表完成后,通过 dt app_schema.t_scene_* 确认对象均位于 app_schema 模式下,owner 为 app_user。
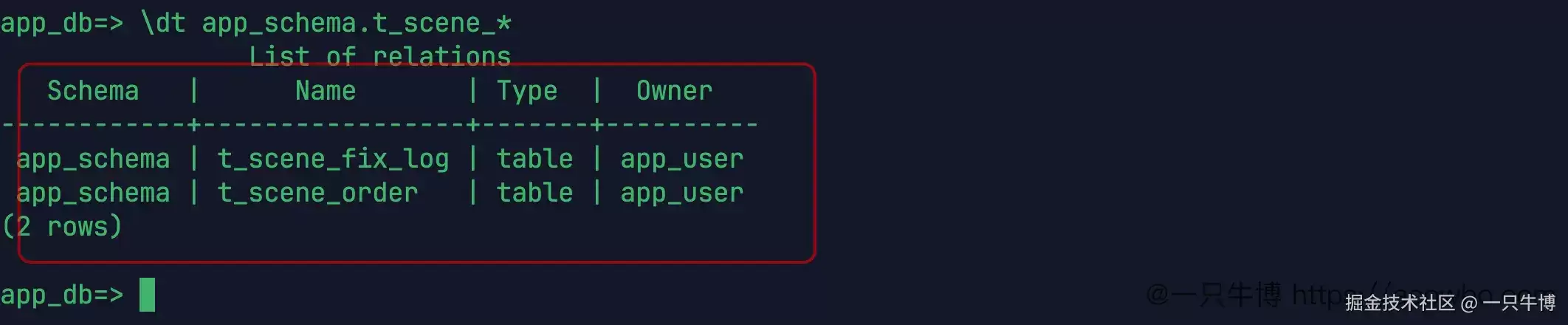
表结构本身并不复杂。真正需要重点关注的是后续的数据分布——尤其是那些金额同样为 0 的订单,哪些属于本次导入批次,哪些只是表面上看起来像是有问题。
初始数据一共包含 10 行记录。BATCH_20260609_A 是本次需要处理的导入批次,其中 1、2、3、10 这几行的状态为 paid,金额均为 0.00,备注中明确写着 import amount missing。4、6、9 虽然也是本批次中的已支付订单,但金额正常。5 是未支付订单,8 是退款订单,不能仅仅因为金额为 0 就去修改它们。
还有一行最容易造成误伤:7 号订单。它同样是 paid 状态,金额也是 0.00,但批次是 BATCH_20260608_B,备注已经写明 old batch should not touch。这一行数据放在这里,就是为了防止修复条件写得太随意。
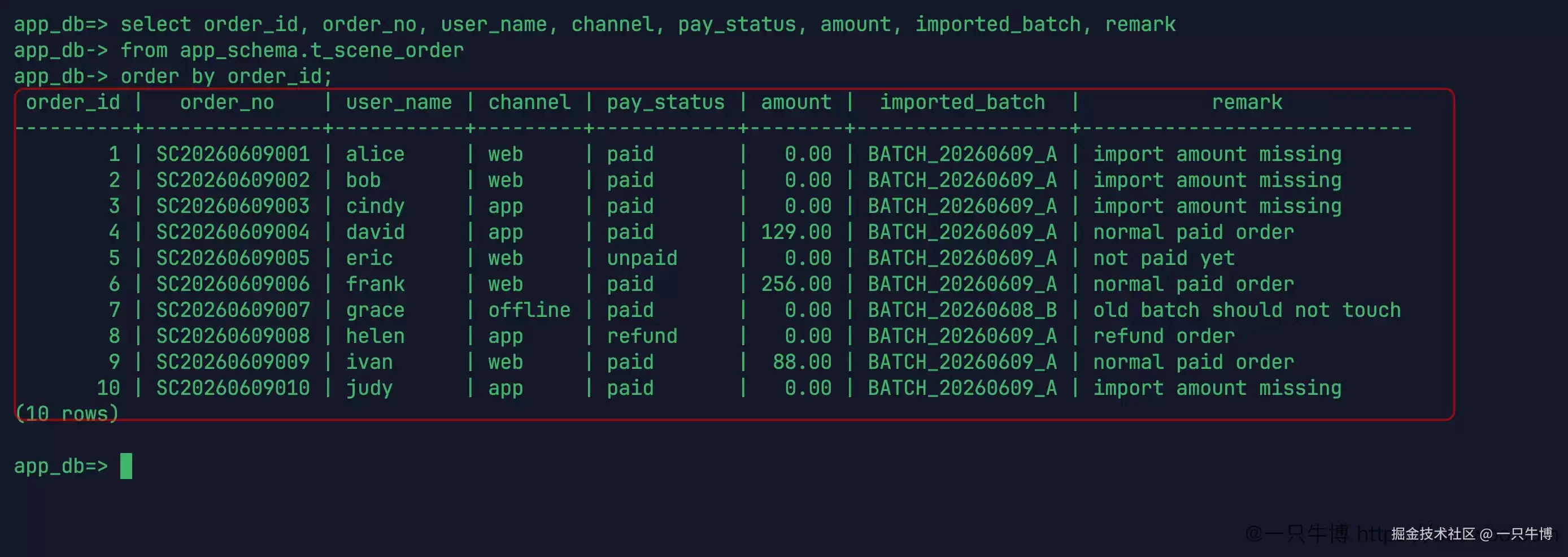
在开始修复之前,先将这 10 行数据按照角色划分清楚,这会比后面盯着 SQL 语句看更有效。1、2、3、10 是目标行;7 是容易误伤的参照行;4、6、9 是正常的已支付订单;5 和 8 虽然金额也是 0,但状态分别是 unpaid 和 refund,不属于本次修复范围。只要后续的 SQL 返回了不应该出现的行,就能立刻停下来。
这种准备数据的方式看似有些繁琐,但它更贴近实际工作中的真实困境。真正的业务场景中很少只有一种异常行,更多时候是多种状态混在一起,字段值看起来相似,但业务含义完全不同。金额为 0 只是表面现象,能否修复,还需要看支付状态、导入批次以及备注中的上下文信息。
第一条 SQL 不该是 update
在这种场景下,第一条 SQL 不应该直接写 update。需要先把可疑范围查询出来,看看当前条件会关联出哪些数据。
首先使用宽泛条件查询:pay_status = 'paid' and amount = 0。结果返回了 5 行,包含 1、2、3、7、10。这里 7 号订单立刻暴露出来——它不属于本次导入批次,却会被这个条件带出来。再加上 imported_batch = 'BATCH_20260609_A' 后,结果缩减为 4 行,只剩下 1、2、3、10。
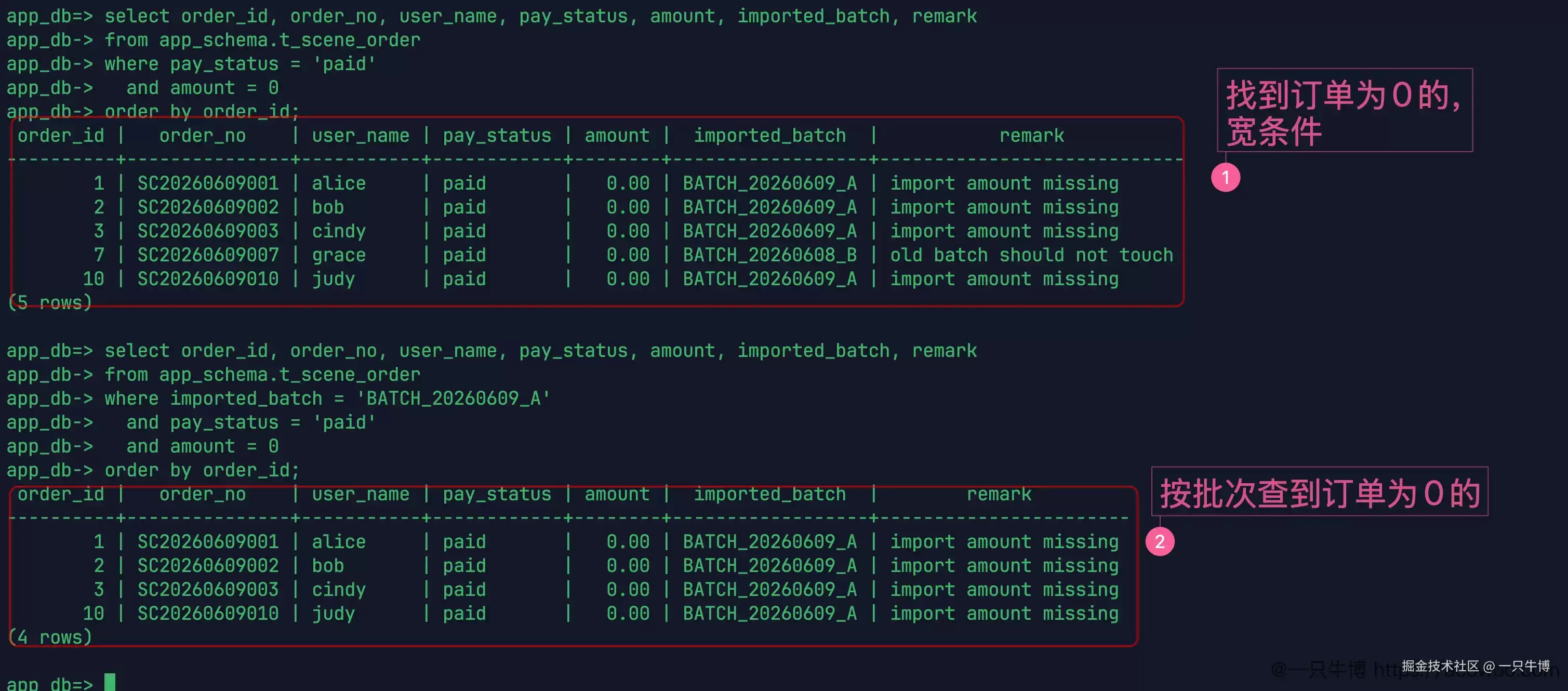
这一步已经把风险清晰呈现出来了。如果仅依据“已支付、金额为 0”来修复,就会多修改一条旧批次的订单;而加上本次导入批次的条件后,才与实际需要处理的范围对齐。后续所有的更新操作,都应该围绕这 4 行展开。
宽泛条件并非不能使用,它更适合用来发现边界问题。第一次查出 5 行,说明异常并不只出现在当前批次中;第二次查出 4 行,说明本次任务可以将批次作为限制条件。将两个结果对比,修复条件就不再是凭感觉写出来的,而是从数据中推导出来的。
这里也能顺便看出 count(*) 并不是唯一选择。很多人在修复前只查一个数量,比如看到 4 行就准备操作,但数量并不能告诉我们这 4 行是否确实是正确的 4 行。先将订单号、批次、状态、备注一起查出来,才能判断条件是否遗漏了业务含义。
修数前留一份原始状态
在修改数据之前,先保留一份原始状态。这里使用 create table as select 创建了一张备份表,将本批次中 paid 且金额为 0 的订单保存下来。执行结果是 SELECT 4,备份表中也只有 1、2、3、10 四行,金额仍然是 0.00。
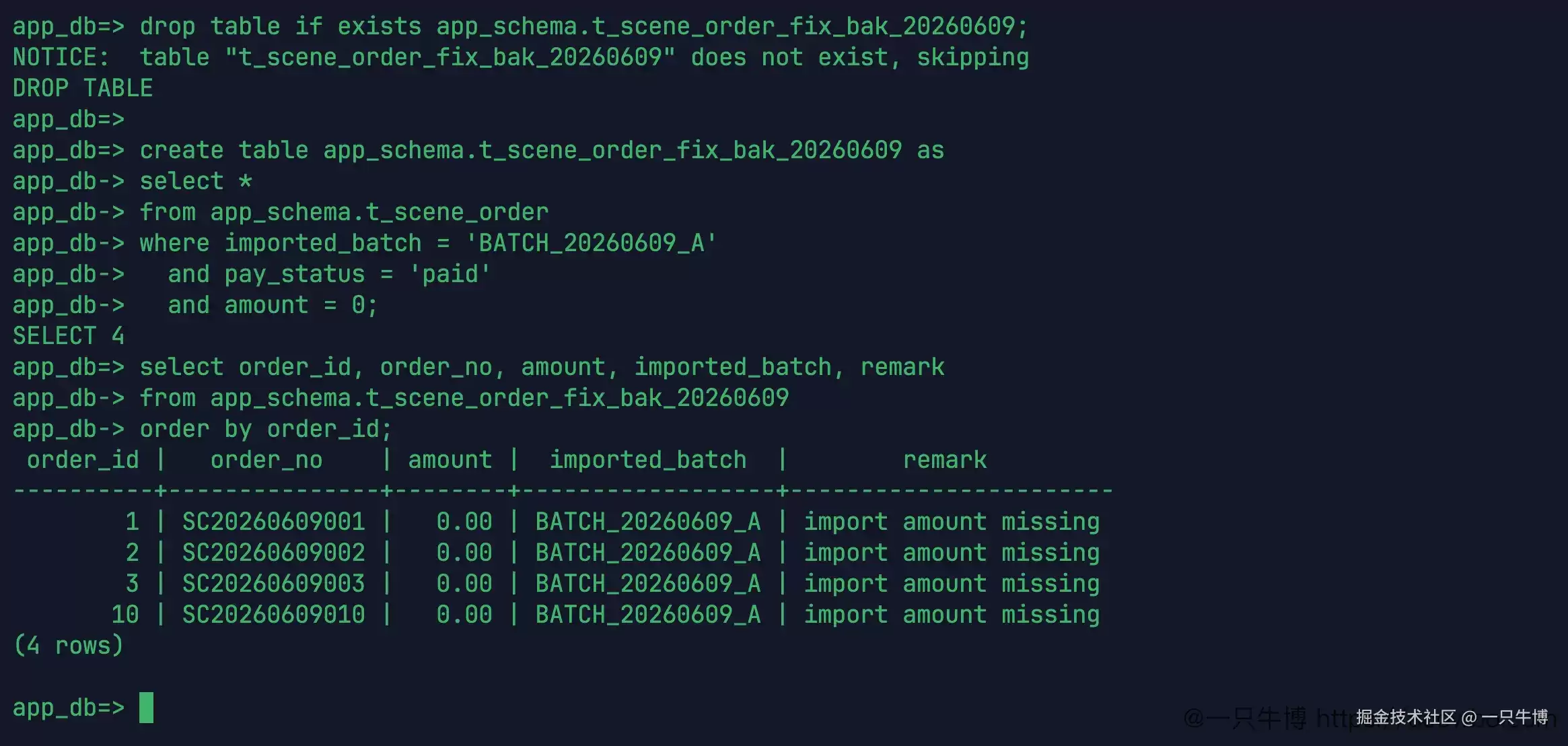
这份备份并不能解决业务问题,但它能让后续操作有据可查。修复前是什么样子,修复后修改了哪些字段,影响行数是否一致,都可以回到这张表中进行核对。临时实验可以这样做,正式环境中也应该有对应的备份、审批或变更记录,不能仅仅依赖终端历史。
备份表的价值还在于它不会随着事务回滚而消失。这里在事务试修之前单独创建的这张表,里面保存的是修复前的候选行。无论之后是先试错、回到保存点,还是重新更新,这份原始数据都能保留下来。修复金额、备注、更新时间这些字段发生变化后,旧值不会只存在于人的记忆中。
不过这类备份也不能随意留存。表名中带有了日期,可以识别出它属于哪次修复;查询条件也与后续正式修复条件一致,并不是把整张订单表复制一份。在正式场景中,还需要考虑备份表的权限、保留时间、敏感字段脱敏等问题,这里只演示了修复前的最小保护动作。
宽条件先暴露风险
接着进入事务,先创建一个保存点 sp_before_fix。这里故意先执行一次宽条件更新,将问题暴露出来:
复制代码where pay_status = 'paid'
and amount = 0
这条更新将金额改为 199.00,备注改为 fixed by wide condition,并通过 returning 返回被更新的行。结果非常直观:返回了 5 行,显示 UPDATE 5,其中包含了 7 号订单。
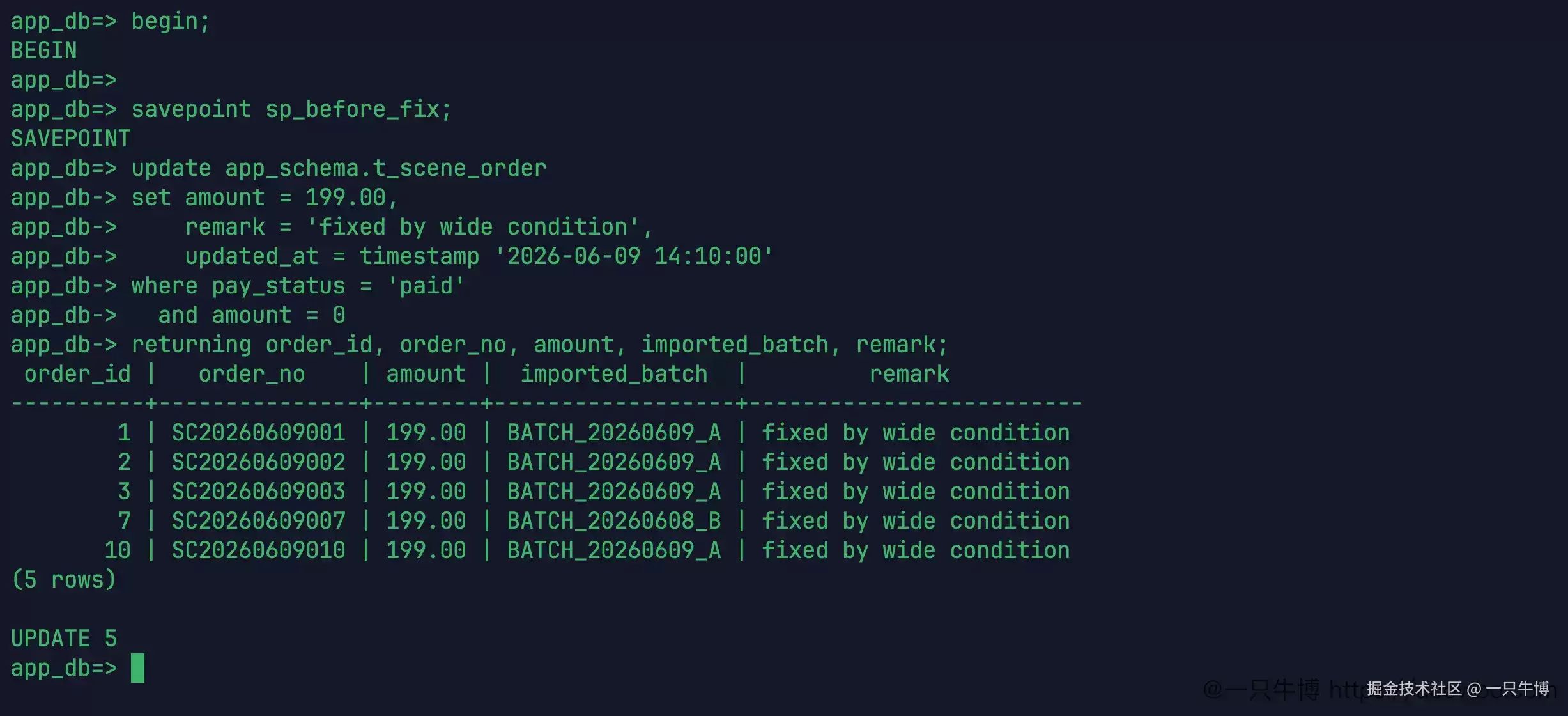
如果没有 returning,仅仅看到 UPDATE 5 也能发现异常,因为之前备份的候选行只有 4 条。但 returning 更加直接——7 号订单的批次 BATCH_20260608_B 已经出现在返回结果中,说明这条 SQL 确实会误伤旧批次。
此时不能提交,也无需整笔事务重新开始。保存点已经创建好,直接回到 sp_before_fix。
复制代码rollback to sa vepoint sp_before_fix;
回到保存点后,再次查询 1、2、3、7、10。金额全部恢复为 0.00,7 号订单的备注仍然是 old batch should not touch,updated_at 也没有被修改。刚才的试修被成功撤销,事务仍然处于活跃状态。
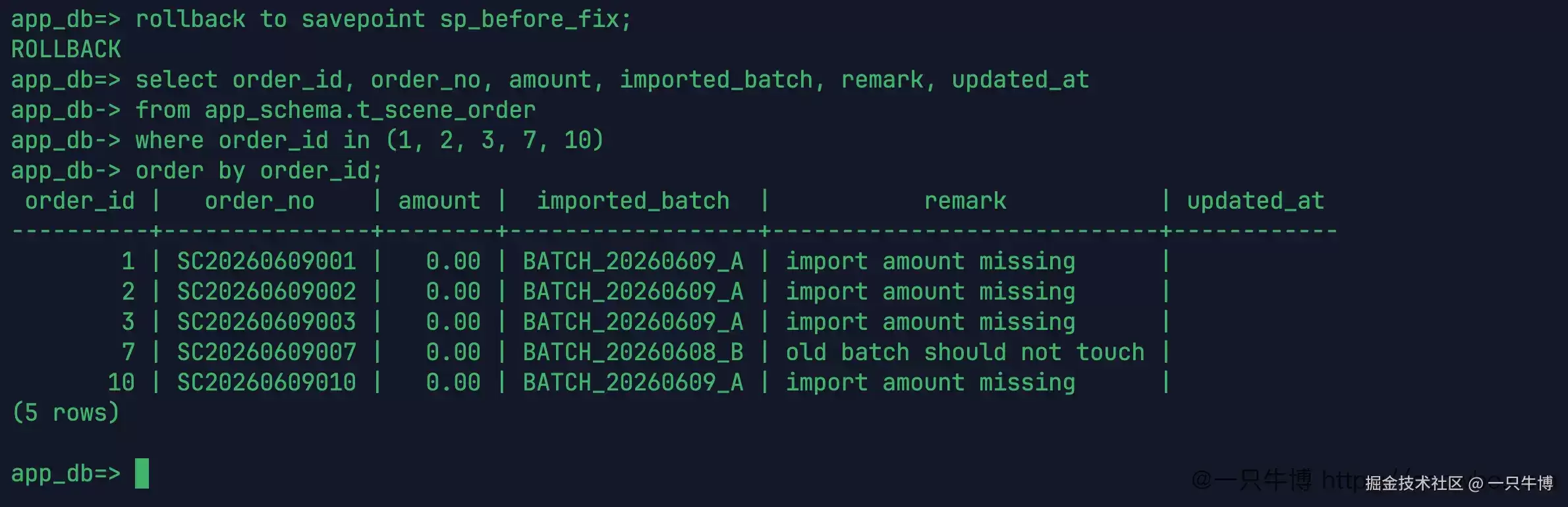
这就是保存点在修复场景中的价值。它的作用并非炫耀语法,而是为一次试探留下退路。条件写宽了,先撤回到试修之前;前面已经完成的备份、范围判断和事务上下文无需重新开始。
回到保存点以后,当前会话仍然在同一笔事务中。前面的试修结果虽然消失了,但数据库连接并未退出,后续仍然可以继续执行新的 update。这与直接 rollback 整笔事务不同:整笔回滚会将当前事务中的所有变动都撤销,而保存点只撤销保存点之后的那个部分。
这类修复操作不适合依赖“应该没问题”来推进。宽条件试修已经将 7 号带出来了,如果此时继续修改,只会让错误叠加。先回到保存点,将现场清理回试修前的状态,再换成更精确的条件,后续的结果才容易判断。
收紧条件后再正式更新
重新编写更新条件,这次将导入批次纳入其中:
复制代码where imported_batch = 'BATCH_20260609_A'
and pay_status = 'paid'
and amount = 0
返回结果变为 4 行,刚好是 1、2、3、10。金额统一更新为 199.00,备注改为 fixed after batch check,更新时间设为 2026-06-09 14:20:00。7 号订单没有出现在返回结果中。
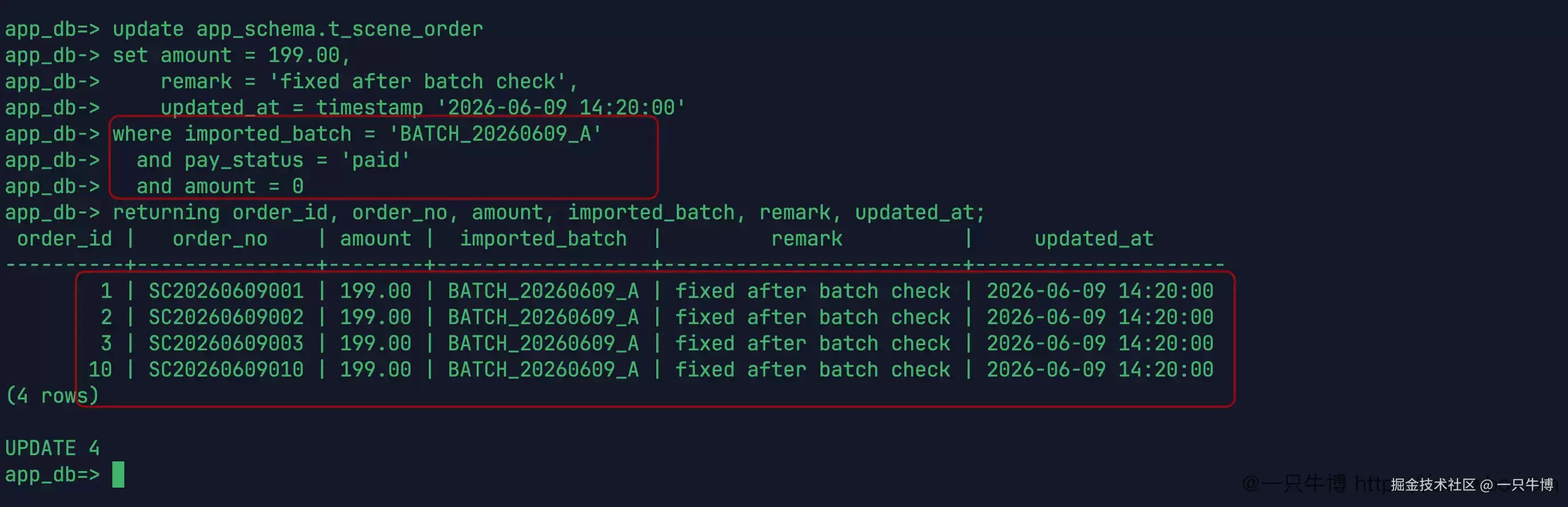
这次的影响范围与前面备份表完全对应:备份 4 行,正式更新 4 行,订单号也是同一组。修复数据时最怕的,是只看 SQL 能执行成功,却不看它到底修改了哪些行。这里通过 returning 直接将修改的订单拉出来,减少了一层猜测。
returning 返回的是更新后的值,所以这里能直接看到金额已经变为 199.00,备注已经变为 fixed after batch check,更新时间也写成了 2026-06-09 14:20:00。如果仅仅看到 UPDATE 4,还需要再执行一条查询才能知道修改后的字段是否符合预期。
当然,returning 也不能替代后续的对账。它只能告诉我们当前这一条更新命中了哪些行,不能证明没有遗漏其他业务条件。比如退款单 8 没有出现,是因为条件中限制了 pay_status = 'paid';旧批次 7 没有出现,是因为这次加入了导入批次。字段限制是否完整,还需要回到业务场景中去判断。
提交前把参照行一起查
在提交之前,再做一次对账。将目标行和 7 号参照行一起查询出来:1、2、3、10 的金额已经是 199.00,备注都是 fixed after batch check;7 号仍然是 0.00,批次仍然是 BATCH_20260608_B。再查询本批次中 paid 且金额为 0 的数量,结果是 0。
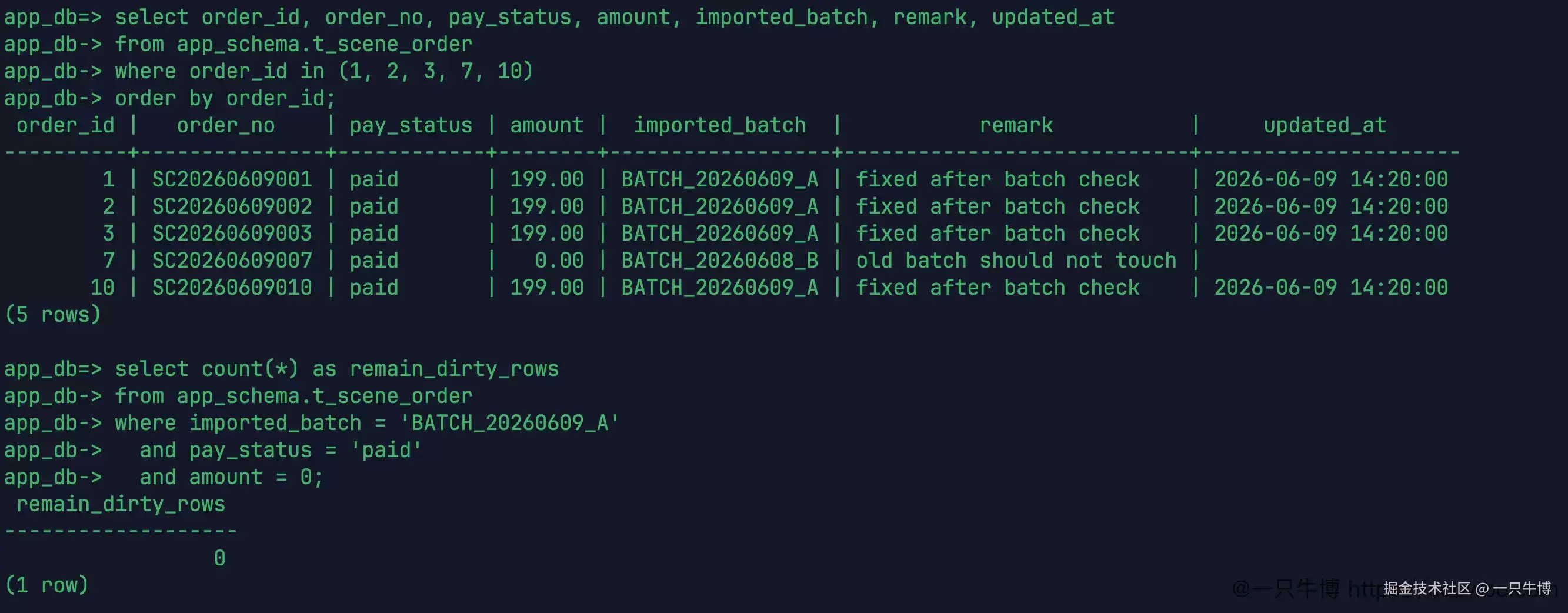
这一步比单纯查看 UPDATE 4 更可靠。UPDATE 4 只能说明修改了 4 行,却不能说明这 4 行是不是目标行;对账查询同时查看了目标行、参照行和剩余脏数据,才能确认这次修复没有将旧批次带入。
在查询时特意将 7 号包含进来,是有意为之。它虽然不是目标行,却是最容易被宽条件带走的行。如果只查 1、2、3、10,会看到目标行都修复好了;但将 7 一起查出来,才能确认“应该留在原地的行”也确实没有变化。
remain_dirty_rows 返回 0,也只是当前条件下的结果:本批次、已支付、金额为 0 的订单没有剩余。这并不代表整个订单表再也没有金额为 0 的数据,因为 5、8、7 这些行本来就不在本次修复范围内。这个边界必须写清楚,否则很容易把一次局部修复讲成全表清洗。
修数记录要和影响行数对上
确认范围没有问题后,再写入一条修复记录。记录中写明 fix paid zero amount orders,影响行数为 4,备注为 only BATCH_20260609_A paid orders were updated,时间为 2026-06-09 14:25:00。这条记录与前面的更新结果完全对应。
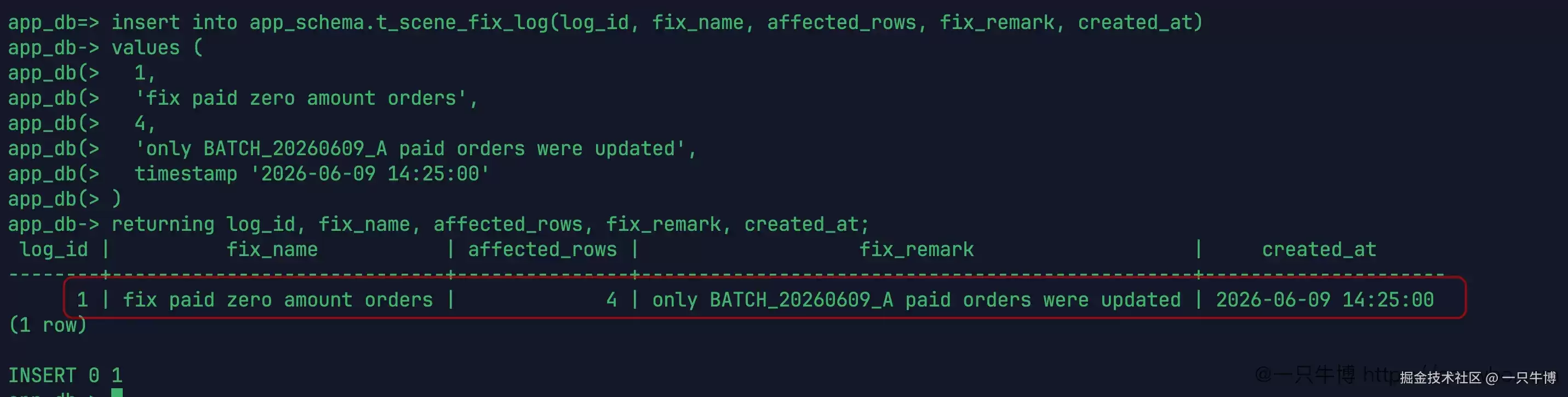
修复记录已经插入成功,返回 INSERT 0 1。这里没有将后续提交和全表终态强行写成已经验证过的内容,只按照终端中能确认的结果收尾:修复记录已经生成,提交前的对账已经确认目标行和参照行状态,记录也有对应的批次和影响行数。
修复记录中的 affected_rows 写为 4,不能随意填写。它对应的是收紧条件后的 UPDATE 4,而不是宽条件试修时的 UPDATE 5。如果这里也写成 5,记录本身就会与实际修复范围冲突;如果不写记录,事后只能从日志或者终端历史中查找,成本会高很多。
整套流程下来,开始时宽条件查出 5 行,说明直接按金额修会带上旧批次;按批次收紧后是 4 行,备份表也保存了这 4 行;事务中故意试了一次宽条件,returning 将 7 号误伤暴露出来;回到保存点后,7 号恢复原样;收紧条件再更新,返回结果只剩目标 4 行;提交前对账,剩余本批次脏数据为 0。
如果要把这次操作浓缩成一句话,那就是先将“可能有问题的数据”变成“确定要处理的数据”。这中间依赖的不是某个固定模板,而是几次核对:宽范围查一次,按批次收一次,备份一次,事务中试一次,发现多改就退回去,再把条件补齐。
以后遇到类似的修复场景,不要急着将 SQL 改到“看起来正确”就执行。先查范围,留原始状态,在事务中试一遍,用返回结果看清影响行,发现不对就回到保存点。最后再将修复结果、参照行和记录表对上。这样处理虽然多敲几条 SQL,但比一次宽条件更新之后再追查误伤要省很多事。




