2024年10月14日,智谱技术团队正式开源了两款文生图模型——CogView3和CogView3-Plus-3B,相关能力已同步集成至“智谱清言”App中。用户现在即可通过该应用直接体验这两款模型带来的高质量图像生成效果。

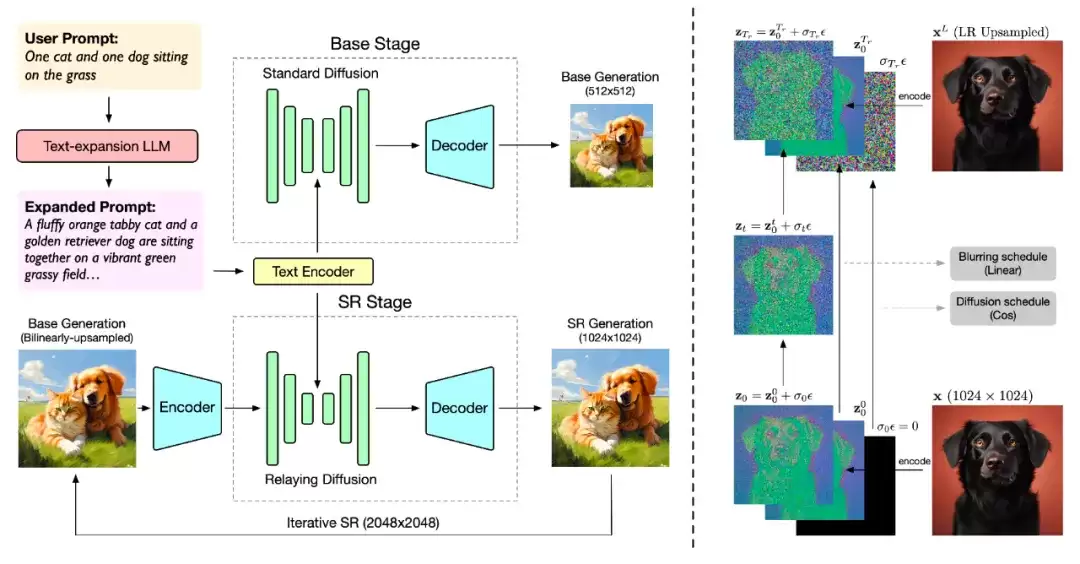
首先介绍CogView3。该模型基于级联扩散(cascade diffusion)技术,采用文本到图像的生成架构,整个生成过程分为三个阶段:
- 第一阶段:通过标准扩散过程生成512×512低分辨率图像,作为基础底图。
- 第二阶段:利用中继扩散(relay diffusion)将分辨率从512×512提升至1024×1024,实现2倍超分辨率。
- 第三阶段:再次应用中继扩散,最终输出2048×2048的高清大图。
官方公布的评估数据显示:在人工评估中,CogView3相比当前最先进的开源文本到图像扩散模型SDXL,性能领先77.0%,而推理时间仅为SDXL的约十分之一。这一效率提升极为显著。
至于CogView3-Plus,它在CogView3(已被ECCV’24收录)基础上,引入了最新的DiT(Diffusion Transformer)框架,进一步提升了整体性能。具体而言,该模型采用Zero-SNR扩散噪声调度,并融入了文本-图像联合注意力机制。与常见的MMDiT结构相比,这种设计在保持基本能力的同时,能有效降低训练和推理成本。此外,CogView3-Plus使用了潜在维度为16的VAE,这一细节对模型压缩和效率具有直接影响。
以下是相关开源地址,方便开发者直接获取和使用:
开源仓库地址:
Plus开源模型仓库: