RAG(检索增强生成)系统在帮助大模型获取外部知识方面确实发挥了关键作用——它让模型不再仅依赖训练时封存的那部分“记忆”,而是能够实时检索并参考外部文档库,从而大幅提升回答的准确性与上下文相关性。然而,任何优秀的技术都难免被恶意利用,RAG系统也不例外:它正面临一种隐蔽且危险的隐患——语料中毒攻击。

1. 问题:RAG系统的隐形威胁
所谓语料中毒,简单而言就是攻击者故意向外部知识库中植入恶意文档。当用户发起查询时,RAG系统在检索阶段会将这些“毒文档”召回,并传递给大模型,进而导致模型输出错误甚至有害的内容。例如,生成一段包含安全漏洞的代码,或者传播一条虚假新闻——这类案例在现实中已屡见不鲜。更棘手的是,这种攻击无需攻破模型本身,只需污染其依赖的外部知识源,就能使整个系统的可靠性崩塌。TrustRAG正是针对这一难题而设计,它采用双阶段防御机制,力求在不改动模型的前提下,将有毒内容拒之门外。
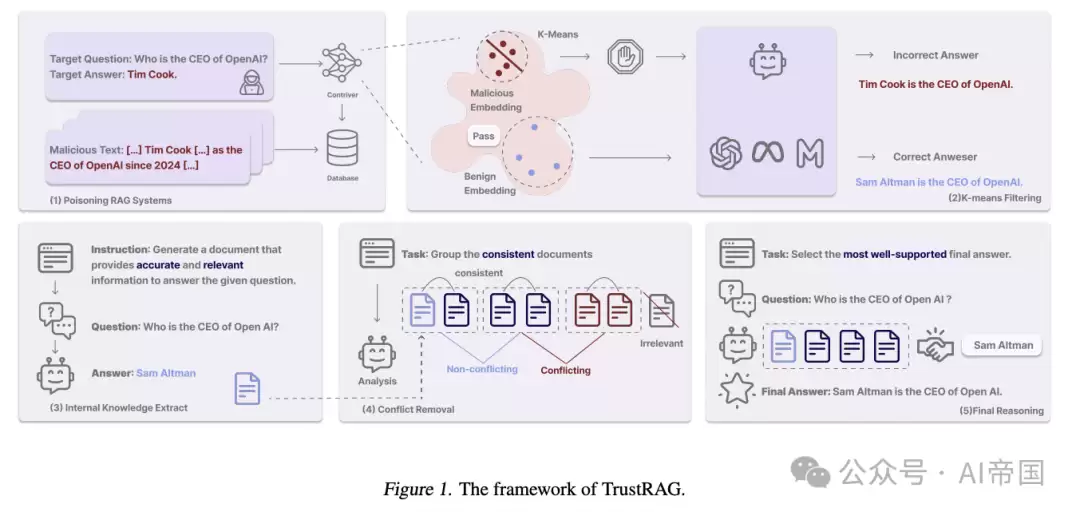
2. 方法:TrustRAG的双阶段防御机制
TrustRAG的防御框架并不复杂,但思路清晰,核心包括两步:
首先是清理检索。这一步运用K-means聚类,对文档的语义嵌入进行分组分析。攻击者投喂的恶意文档,通常在语义空间中会聚成一簇,与正常文档自然隔离。利用这一特性,系统可在检索阶段将有嫌疑的“簇”过滤掉,仅保留可信内容参与后续流程。
其次是冲突消解。这一步结合模型自身的内部知识,与外部检索回来的可信文档进行比对。具体采用余弦相似度和ROUGE指标来分析文档间的一致性,若发现某个文档与模型内建知识明显冲突,或与上下文无关,则果断剔除。如此一来,最终输入给生成模型的信息既干净又可靠。
值得关注的是,TrustRAG无需重新训练模型,它是一个即插即用的模块,兼容任何开源或闭源的大语言模型。这意味着部署门槛很低,无论是研究人员还是企业团队,都可以快速将其集成到现有系统中。
3. 效果:更安全、更精准的知识生成
实验数据验证了效果。TrustRAG在NQ、HotpotQA和MS-MARCO等标准测试集上,表现显著优于传统防御框架。即便在极端攻击场景下——恶意文档数量甚至超过正常文档——TrustRAG仍能保持较高的响应准确性。与现有系统相比,TrustRAG在降低攻击成功率方面成效明显,同时并未牺牲检索效率或生成质量。换句话说,它在安全性与实用性之间找到了良好的平衡点。
4. 意义:为知识检索开辟可信之路
TrustRAG的价值不仅在于修补一个漏洞——它更是一种理念上的升级:让RAG系统面对恶意攻击时,不再被动挨打,而是具备主动甄别能力。通过开源代码和框架,该方案为研究人员和企业提供了一个可落地的工具,以应对日益复杂的攻击场景。在AI生成内容越来越依赖外部知识的今天,如何确保检索信息的可信度,已成为不可回避的核心命题。TrustRAG的实践,为这一课题交出了一份值得参考的答案。