深入了解人工智能模型中预训练与微调的核心机制,探究机器学习如何推动自然语言处理实现高效落地。
本文重点:
1. 预训练的基本概念及其在自然语言处理中的关键作用
2. 微调的定义以及针对特定任务优化的重要性
3. 预训练与微调相结合如何显著提升AI模型的综合性能
预训练与微调是现代深度学习模型的两大支柱技术。两者相辅相成,使机器在处理复杂任务时能够展现出更高的效率与精准度。预训练赋予模型广泛的语言理解基础,而微调则专注于在具体应用场景中精调优化,持续提升表现。
- 1. 什么是预训练?
- 1.1 预训练的核心要点
- 1.2 生活化类比
- 2. 什么是微调?
- 2.1 微调的核心要点
- 2.2 生活化类比
- 3. 预训练与微调的主要区别
- 4. 总结
近年来,人工智能在多个领域取得了突破性进展,尤其在自然语言处理方面表现尤为突出。这一切的背后,预训练与微调技术扮演着不可或缺的基石角色。
简而言之,预训练是让模型在海量通用数据上先进行“预习”,帮助其掌握语言的结构与语义规律;而微调则是在此基础上,利用特定任务的数据进行定向优化。二者结合,机器便能在不同应用场景中更准确地理解文本内容、更自然地生成语言。
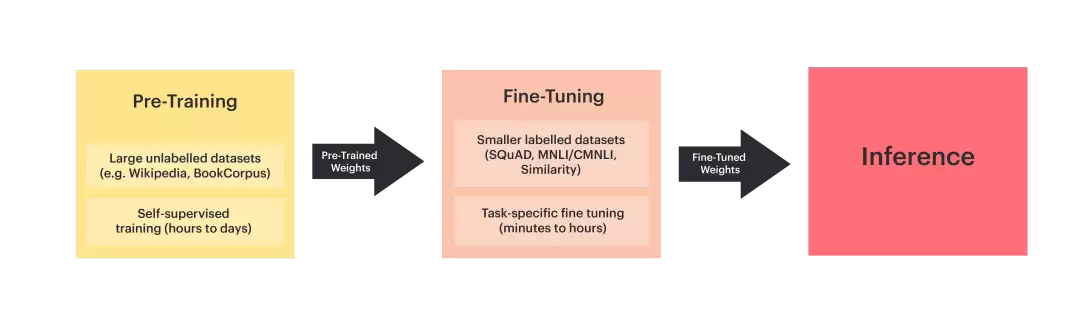
1. 什么是预训练?
预训练是指将模型在大量通用数据上先行训练,使其习得普适性的知识,尤其在自然语言处理领域更是如此。大型语言模型的预训练阶段,相当于教会模型如何理解并生成文本的第一步。
可以将其想象成阅读海量书籍、文章和网页,从中学习语法、事实以及常见的语言模式。在该阶段,模型通过不同的预训练策略——例如自回归语言建模与掩码语言建模——来把握文本结构。举例来说,自回归模型(如GPT)通过预测下一个token来学习文本的连贯性;而BERT这类模型则通过遮盖部分token并还原原始值,增强对上下文的深层理解。
需要指出的是,此时模型并未像人类一样真正“理解”语义——它仅仅是在识别统计模式与概率分布。
预训练的目标是让模型习得丰富的语言表征,涵盖语法、语义、上下文关联等方面。这样一来,当面对文本分类、内容生成、翻译等各类下游任务时,模型便具备更强的泛化能力。
- 语言知识:预训练侧重于从不同领域获取广泛的语言知识,显著提升了模型的多功能性与适用性。这种宽泛的理解使语言模型能够从容应对各类任务。
- 微调的基础:预训练过程构建了坚实的知识基底,为后续的微调工作铺平道路。这一基础对于模型适应特定任务至关重要,使其能够无缝对接各种实际应用场景。
- 理解复杂关系:预训练使大型语言模型具备解析文本中复杂句法与语义关系的能力,这极大地提升了模型在下游应用中的表现,输出的内容更为连贯、更贴合语境。
值得一提的是,FineWeb数据集作为大规模、高质量的网页文本数据集,常被用于训练大型语言模型。该数据集主要源自互联网上的开放网页,经过严格的清理与筛选,确保了数据的高质量、强相关性与多样性。这类优质数据集对提升AI模型的整体性能大有裨益。
1.1 预训练的核心要点
尽管预训练成果显著,但仍面临诸多挑战。首先,该阶段需要海量的计算资源与庞大数据,能耗较大,可持续性值得关注。其次,预训练产出的模型往往比较“通用”,未必能完美契合特定任务的要求。因此,如何在保留预训练通用知识的同时,提升模型在具体任务上的表现始终是一大难题。此外,确保模型学到具备泛化能力的语言模式,而非过度依赖某个特定数据集——这一平衡对模型处理多样化的下游任务至关重要。
1.2 生活化类比
可以将预训练想象成学生在进入大学前接受的通识教育课程。这些课程不针对某个具体专业,却能让学生对各类知识形成广泛认知。例如学习语文、数学、历史,打下扎实的能力基础。等到学生进入医学、计算机等特定专业后,再根据专业需求深入钻研——这恰好对应了预训练与微调的关系。
经过预训练的模型,已经在海量文本数据上完成了训练,但尚未针对特定任务进行调整,这种模型通常被称为基础模型。
2. 什么是微调?
微调是在预训练的基础上,利用特定任务的数据集对模型进行进一步训练。预训练旨在赋予模型广泛的语言能力,而微调则致力于让模型在某一具体任务上实现专项优化,例如情感分析、机器翻译或文本生成。通过微调,模型能够在特定任务中展现出更高的精度与性能。
这一过程涉及几个关键目标:
- 任务优化:根据特定任务的数据调整模型权重,优化模型在该任务或领域的表现。
- 准确性与相关性:在法律文件分析、客户服务或医疗转录等专业场景中,提升输出的准确性与相关性。
- 减少偏见:降低预训练过程中可能无意强化的偏见,使模型在实际应用中更加准确、更加合乎伦理标准。
2.1 微调的核心要点
微调面临的挑战同样不容忽视。一方面,需要确保在特定任务上取得高性能,同时不能遗忘预训练阶段习得的通用知识。另一方面,当微调数据量较小时,模型可能难以充分学习任务的特定特征。尤其当微调数据与预训练数据在领域、任务形式、语言风格或标签分布上差异较大时(即存在分布偏移),模型可能无法很好地泛化到新任务,从而影响微调效果。
2.2 生活化类比
微调就像大学生在专业课上的学习。学生已经具备了通识基础,现在需要专注于特定学科,进行深入研究。比如从“医学通识”转向“临床诊断”或“生物化学”等专业知识。在这一过程中,学生会根据未来的职业目标,聚焦具体的学习内容——这正对应了微调的精髓。
3. 预训练与微调的主要区别
预训练与微调最大的区别在于各自的目的与训练流程。预训练旨在让模型掌握语言的基本规律与结构,通常在超大规模通用数据集上进行,目标是获取广泛的知识。而微调则是在特定任务的数据集上继续训练,目标是让模型针对具体任务做出最优化调整。
预训练侧重学习广泛的语言表征,包括语言结构、语义关系与常识推理,使模型具备强大的泛化能力;而微调则着重于针对特定任务或领域进行定向优化,提升在具体任务上的精度与表现。前者通常需要大规模的计算资源投入,后者则更关注如何利用少量数据高效地调整模型。
4. 总结
预训练与微调是现代人工智能模型的核心技术,二者相互配合,使机器在处理复杂任务时更高效、更精准。预训练为模型提供了广泛的语言能力基底,微调则确保模型能够针对特定任务进行细化和优化。随着技术的持续演进,这些方法将在更多领域释放潜力,推动人工智能不断向前发展。