我们先来看一组数据。根据思科的统计,互联网视频流在带宽消耗中占据主导地位,预计到2022年,它将消耗超过82%的消费类互联网流量。视频服务已经像水和电一样,深深融入到人们的日常生活中。
一个很现实的问题是,网络总会发生抖动,为了不让视频因此卡顿成幻灯片,自适应多码率技术已成为业界公认的“杀手锏”。例如MPEG-DASH、苹果的HLS,以及快手的LAS,其核心思路都是相同的:根据网络状态和播放情况,动态调整请求视频的清晰度(码率)。核心目标是在流畅度、清晰度和切换平滑度之间找到最佳平衡点,从而最大化用户体验。
目前的ABR算法大致分为两类:一类是“启发式”路线,依赖建立各种模型或规则来选择码率。这类算法的问题在于参数调整非常繁琐,难以适应千变万化的网络环境。另一类则更“智能”,采用了机器学习方法,让播放器在实际网络交互中自行学习一套适应当前环境的策略。
不过,任何算法从实验室到真实世界的落地,都离不开漫长的调试与优化。许多在实验室中看似“无关紧要”的问题,一旦进入实际部署,就会成为难以跨越的障碍。
针对这些痛点,快手音视频技术部与清华大学孙立峰教授团队合作,对基于学习的ABR算法进行了两项核心改进,相关成果分别发表在顶级会议IEEE INFOCOM 2020和顶级期刊IEEE JSAC上。
论文地址:https://ieeexplore.ieee.org/abstract/document/9109427
自适应多码率
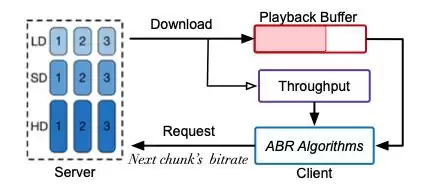
图1 码率自适应传输架构图
自适应多码率的传输架构主要分为两大类:基于分片(如MPEG-DASH、HLS)和基于流式(如LAS)。这里以基于分片的方式为例(如图1所示):视频发布前,会先被切成小段,并转码成不同码率、不同清晰度的版本。在客户端,每当下一个分片下载完成后,ABR算法会综合考量当前带宽、缓冲区状态以及用户信息,决定下一个分片应请求哪个码率,从而实现自适应,最终提升QoE(用户体验质量)。
用户的QoE通常由以下指标来衡量,具体见公式1:
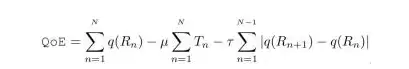
公式1 自适应码率传输中的QoE定义
公式中,Rn代表视频码率,Tn代表卡顿时长,最后一项是平滑项,目的是避免码率频繁切换。μ和τ是惩罚系数。对于ABR算法而言,这个优化是一个典型的长期优化问题。举例来说,如果某个时刻ABR算法过于“贪心”,选择了一个高码率,而下一秒网络状况变差,那么后续几个片段只能被迫选择低码率,甚至出现卡顿。综合来看,这次贪心的选择其实非常糟糕。
基于学习的ABR
机器学习能否解决这种长期优化问题?答案是肯定的。以Pensieve(SIGCOMM'17)为例,它将码率自适应过程建模为马尔可夫决策过程(MDP),利用深度强化学习(DRL)从零开始训练,最终学到的策略在QoE指标上比此前最优秀的算法高出18%。
然而,尽管Pensieve在性能上实现了突破,但真正落地部署时仍面临几个硬性挑战:
开销问题:为降低客户端的计算压力,Pensieve将整个模型推理放在服务器端。但在实践中,大多数ABR算法仍部署在客户端,因为这样可以省去服务器带来的额外延迟和服务开销。因此,如何从机制上压缩模型开销,是部署的第一大挑战。
效率问题:Pensieve通过强化学习训练,收敛一个策略通常至少需要8小时。如何提升训练效率,使其能始终适应不断变化的网络状态,这是第二个挑战。
1、结合领域知识,降低整体开销
面对第一个挑战,我们的方案是“结合领域知识”。基本动机是:尽管像AlphaZero这样的突破性算法在摒弃人类经验后达到了更高水准,但ABR算法是一个“状态和动作空间相对较小、物理意义明确”的任务——那些经典的启发式算法,是否已经挖掘出了足够有价值的“领域特征”呢?
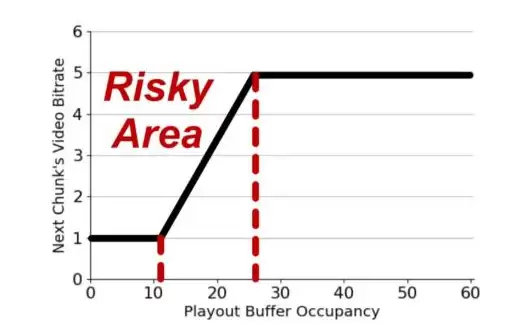
图2 BBA算法原理介绍
BBA(Buffer-Based Approach,SIGCOMM'14)就是这类算法的优秀代表。其原理如图2所示:它内部有两个阈值(RESEVIOR和CUSHION)。当当前缓冲区小于RESEVIOR时,BBA直接选择最低码率;当缓冲区大于RESEVIOR+CUSHION时,它选择最高码率;其他情况,则根据缓冲区大小线性拟合出一个合适的码率。因此,BBA性能的好坏很大程度上取决于这两个阈值选取的准确性。
我们尝试将BBA与基于学习的算法有机融合:一方面用深度学习来增强BBA,另一方面让BBA为学习算法提供宝贵的领域知识,从而降低模型开销。最终,我们提出了Stick系统。
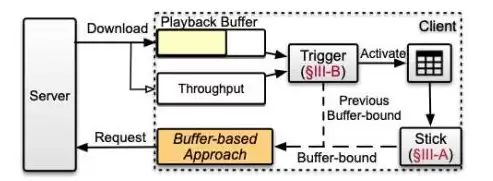
图3 Stick系统架构图
Stick的方案框架如图3所示,主要由两部分组成:
- 基本Stick模块:它由一个线下训练的神经网络构成,根据客户端的状态输出一个连续值,用来动态调节BBA的阈值。
- Trigger模块:这是一个非常轻量级的神经网络,部署在Stick之前,用于判断“这次是否需要启用Stick模块”,进一步降低开销。
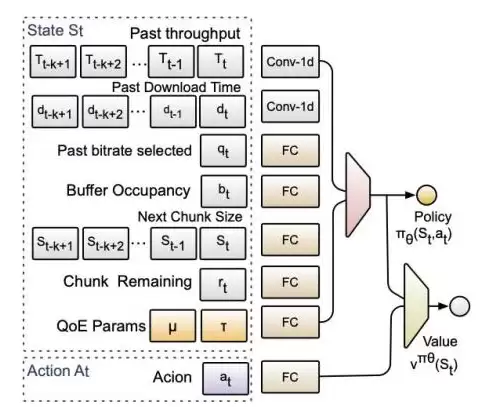
图4 Stick神经网络结构
Stick模块使用连续值下的深度强化学习算法(DDPG)来训练神经网络。它将过去的码率选择、带宽、下载时长、未来视频大小、剩余时长、当前缓冲区等信息作为输入,最终输出一个单值——这个值代表了“允许选择最大码率”的缓冲区大小。之后,经典的BBA算法会根据这个值生成一个缓冲表,从而决定每个缓冲水平下应下载哪个码率。实验证明,这种方式可以大幅降低神经网络的开销,模型大小最高缩减了88%。
Trigger模块:在利用领域知识缩小模型后,我们进一步挖掘了BBA的潜力:由于Stick使用缓冲表来选择码率,它携带的信息量远比普通输出要多。实验发现,在大部分网络情况下(只有30%-40%的情况),我们才需要激活Stick神经网络来更新阈值,其他时候沿用上一次的阈值即可。因此,我们在Stick前面部署一个极轻量级的小神经网络,用简单的结构来决定是否更新阈值。这里我们采用了模仿学习,在训练时实时求解出最优解,引导神经网络逐步接近最优策略。
实验结果显示,与经典的BBA和BOLA相比,Stick分别将QoE提升了44.26%和25.93%。在与各种其他算法的对比中,Stick也全面领先,总体提升了3.5%到25.86%的QoE。此外,与Pensieve相比,Stick的模型开销减少了88%。
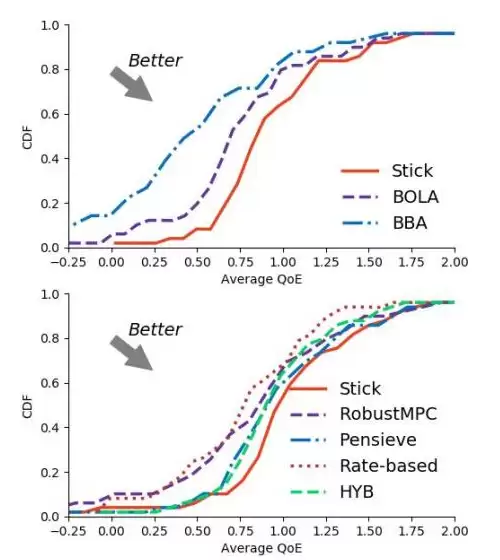
图5 Stick实验结果
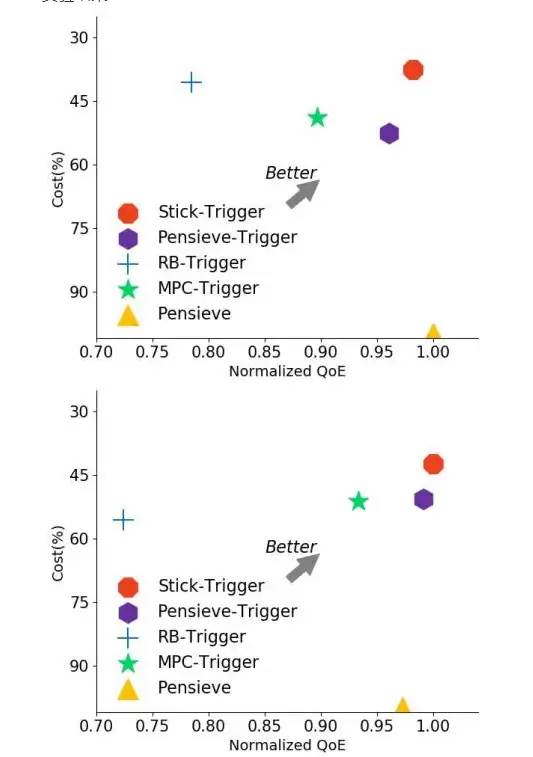
图6 Trigger实验结果
Trigger模块在三个不同数据集上的测试表明,它能显著降低Stick的整体开销,节省幅度在39%到61%之间。更有趣的是,Trigger还能帮助一些经典算法(如Rate-based和改进后的Pensieve)提升性能。
更详细的细节,可以参考我们在IEEE INFOCOM 2020上的论文:《Stick: A Harmonious Fusion of Buffer-based and Learning-based Approach for Adaptive Streaming》。
2、改善训练效率,在线终身学习
第二个挑战来自强化学习的低训练效率。在强化学习中,智能体通过与环境交互,获取{状态、动作、回报}三件套,然后通过学习来增加每次动作的回报。但问题在于,训练过程中智能体并不知道当前状态下的最优动作是什么,因此无法给出准确的梯度更新方向。ABR算法自然也难以避免这个弱点。
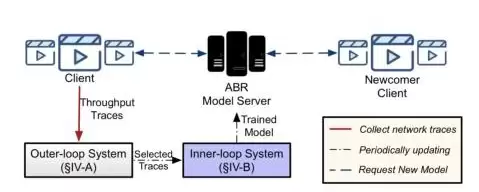
图7 LifeLong-Comyco系统架构
针对这一问题,我们提出了Lifelong-Comyco,一种终身模仿学习的ABR算法。系统架构如图7所示,由内外两层循环组成:
- 内循环系统:使用模仿学习,更快、更高效地从专家序列中学习策略。
- 外循环系统:负责持续更新,采用终身学习的方式,让系统能自主“查缺补漏”,只学习真正需要的数据。
整个流程如下:视频播放前,客户端从模型服务器下载最新的神经网络模型;每次播放结束后,客户端根据已下载的块大小和下载时长生成带宽数据;然后将这些数据提交到外循环系统。外循环系统会估算当前策略与最优策略之间的差距,如果差距过大,就判断这个带宽数据值得加入训练集。之后(例如每隔1小时),内循环系统会被激活,通过终身模仿学习高效地更新神经网络。最后,模型会定期冻结,并提交回模型服务器。
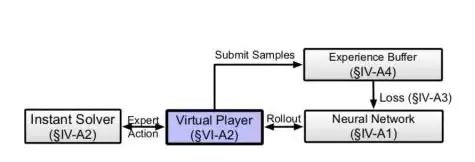
图8 内循环系统架构
内循环系统充分利用了一个特点:在给定的网络和视频条件下,我们可以通过线下模拟器准确判断出当前的最优解或接近最优的解。获得最优解后,就可以用传统的监督学习方法来高效更新神经网络。大致方法是:先用蒙特卡洛采样,从相同状态开始,推演N步;然后选择QoE得分最高的那条轨迹中的第一个选择,作为未来的码率选择;将{状态,最优选择}保存到经验池中;每次训练时,再随机从经验池中采样进行训练。与强化学习不同,模仿学习实现了采样和训练的解耦,从而能大幅提升并行效率。
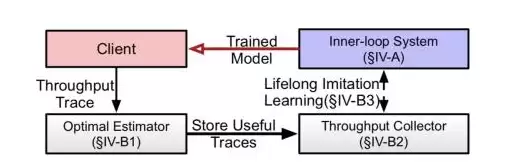
图9 外循环系统架构
外循环系统的核心是进一步减少训练所需的数据。客户端上报的带宽数据会先被计算一次最优解,然后比较当前策略和最优解之间的QoE差距。当差距超过某个阈值时,这个带宽数据就会被保留下来,加入训练数据集。最后,我们使用终身学习的方法来训练神经网络,这是一种经典的主动学习方案,能在不遗忘过去表现良好的数据的前提下,记住那些效果不佳的带宽数据。
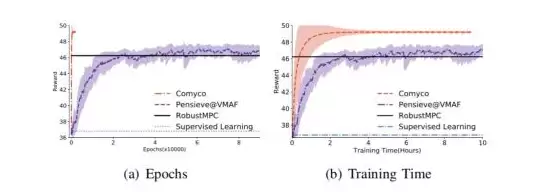
图13 内循环系统训练曲线
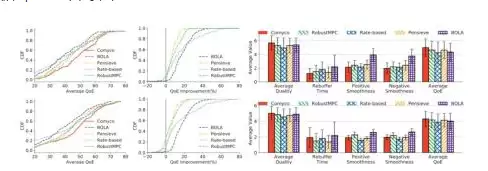
图14 内循环系统实验结果。算法在FCC和HSDPA数据集上进行了细致测试
实验结果非常令人振奋。先看内循环系统:如图10所示,模仿学习不仅有效,而且学习速度极快——整体训练步数比强化学习减少了1700倍,训练时长缩短了16倍,并且性能还有提升。在HSDPA数据集上,模仿学习训练出的策略比过去的方法高出7.5%到17.99%的QoE。
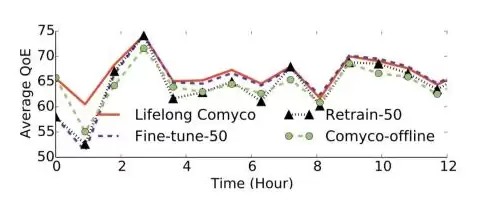
图15 外循环系统实验结果
接着测试了外循环系统。我们收集了12小时的带宽序列数据,每小时整点对神经网络进行更新,其余时间记录需要使用的带宽数据集。结果明确显示,采用终身学习可以有效避免灾难性遗忘问题,并且能随时跟随网络分布的变化更新策略,使性能始终维持在一个不错的状态。相比之下,无论是实时微调、重新训练,还是只使用内循环系统,效果都不及外循环。实验表明,加上外循环系统后,性能比仅使用内循环系统又足足提升了1.07%到9.81%。
更详细的细节,可以参考我们在IEEE JSAC上的论文《Quality-aware Neural Adaptive Video Streaming with Lifelong Imitation Learning》。
结语
基于机器学习的ABR算法要真正落地,还有许多问题值得深入探讨,例如可解释性、鲁棒性,以及更小巧的模型。快手拥有完善的数据集、AB测试平台和经验丰富的算法团队,非常期待与各位同行、学者一起研究探讨,共同打造出落地有效、真正能提升用户体验的技术方案。