DeepSeek-R1的正式发布,无疑是人工智能推理领域一次真正的革命性突破。本文将深入解析这款模型的核心技术架构与创新亮点。先深入了解几个关键信息:
- 开源策略:提供了经过轻量化处理的蒸馏版本,极大降低了开发者的上手门槛,便于广泛实验。
- 技术透明:完整公开了构建类似OpenAI O1高性能推理模型的全套训练方法,展现了极高的技术开放性。
- 训练创新:涵盖长链式推理数据集、过渡模型构建以及大规模强化学习,每个环节都蕴含着独特的设计巧思。
对于机器学习研发社区而言,这无疑是一座重要的里程碑。接下来,我们将从大语言模型的基础训练流程入手,逐步深入解析R1的独特之处与技术创新。
一、大语言模型的基本训练流程
与众多大语言模型相似,DeepSeek-R1采用逐词生成的运作方式。它在数学推理与复杂问题求解上表现卓越的关键,在于能够生成详尽的思考过程——通过增加推理步骤来高效解决问题。通用大模型的训练通常包含以下三个阶段:
- 预训练阶段:基于海量互联网文本数据进行下一个词元(next-token)预测,构建模型的基础语义与知识能力。
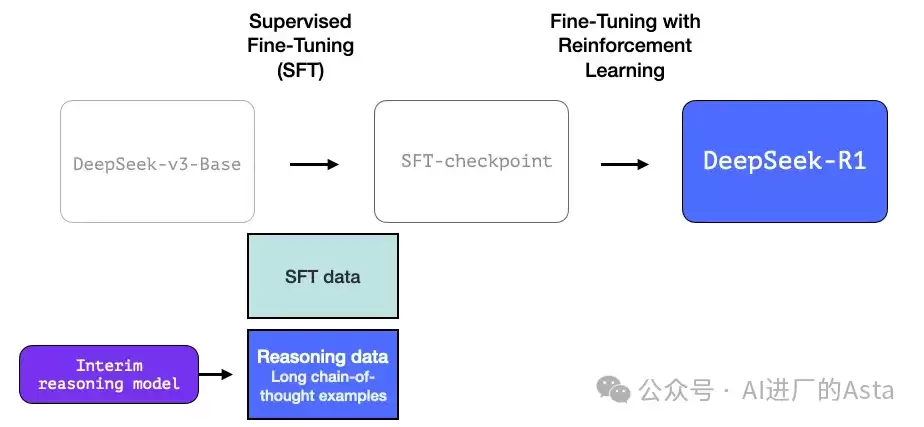
- 监督微调阶段:进行指令理解与执行训练,使模型具备基础对话能力,形成SFT(监督微调)模型。
- 偏好对齐阶段:依据人类偏好对模型行为进行优化微调,最终产出可用且符合预期的版本。
二、DeepSeek-R1的创新训练方法
DeepSeek-R1在遵循上述基本训练流程的同时,在具体实现上实现了多项创新。我们来逐一深入解析。
2.1 专注于长链式推理的训练数据
模型使用了约60万个包含细致推理过程的训练样本。如此规模的高质量推理数据,若完全依赖人工逐条标注,成本将极为高昂。为此,研发团队设计了一套独特的数据生成策略——首先构建一个擅长推理的中间模型,再由该模型自动产出大规模的高质量训练样本,实现数据的“自繁衍”。
2.2 构建专精推理的过渡模型
团队首先开发了一个专注于推理能力的中间模型(该模型本身未作正式命名)。它在其他通用任务上表现一般,但仅需少量标注数据就能在推理问题上展现出卓越能力。随后,该模型被用来生成大规模的训练数据,进而帮助训练出既能精通推理,又能胜任其他任务的最终版R1模型。
2.3 基于大规模强化学习的核心技术
强化学习训练是整个流程的核心引擎,主要分为两个关键阶段。
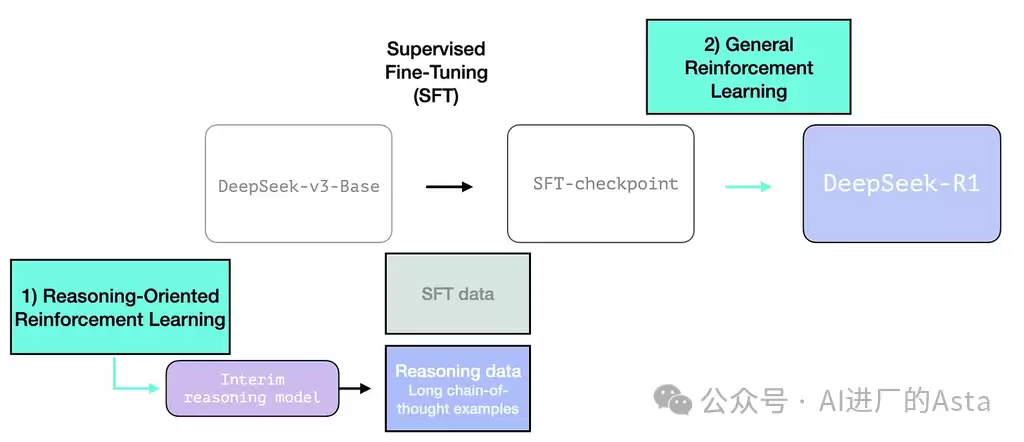
2.3.1 R1-Zero:推理导向的强化学习
这一突破性进展源于早期R1-Zero模型的实验成果。DeepSeek团队首先研发出R1-Zero模型,其最独特之处在于:无需大量人工标注数据,直接从预训练基础模型出发,仅通过强化学习就达到了与OpenAI O1模型相抗衡的水平。
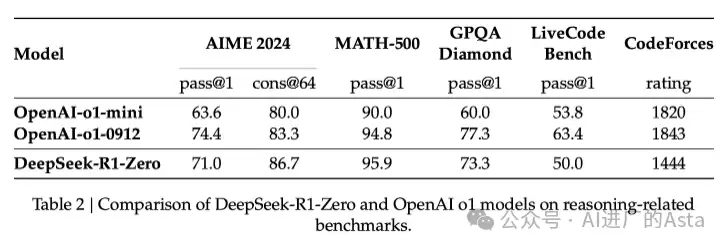
这一进展揭示了两个重要发现:
- 现代基础模型(在14.8万亿高质量词元上经过预训练)已经具备了强大的基础能力,为强化学习提供了良好起点;
- 推理类问题相比一般开放对话更容易实现自动化评估与验证。
让我们通过一个具体示例来理解推理问题的自动验证过程。假设向模型提供以下编程任务:
编写Python代码,接受一个数字列表,按排序顺序返回它们,并在开头添加42。
此类问题可以通过多种方式自动验证。当正在训练的模型生成一个完成时,系统可以:
- 利用代码检查器判断生成内容是否为正确的Python代码;
- 直接执行代码看其能否成功运行;
- 使用另一编码大语言模型(即使不是推理专家)创建单元测试来验证所需行为;
- 甚至进一步测量执行时间,在训练过程中倾向于性能更优的解决方案。
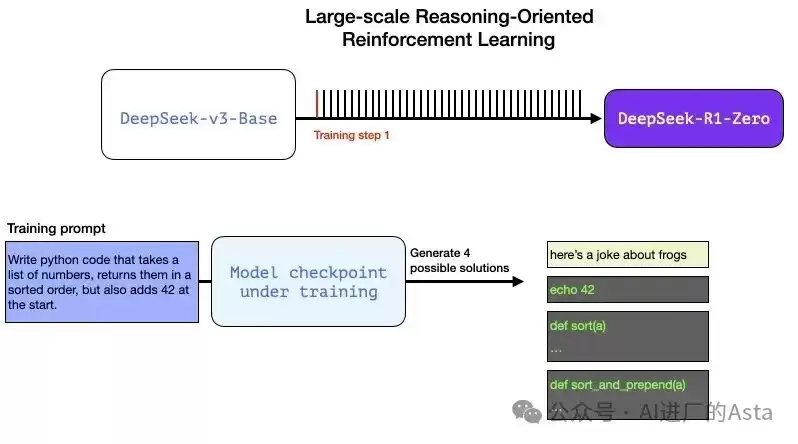
在训练过程中,模型会生成多个可能的解决方案,系统能够自动评估每个方案的质量。例如:方案1可能完全不是代码,方案2是代码但非Python,方案3是Python但未通过测试,方案4才是完全正确的解决方案。所有这些都能作为直接反馈信号,用于改进模型。当然,这一过程是在许多示例(小批量)中完成的,并在连续的训练步骤中进行。这些奖励信号和模型更新使模型在强化学习训练过程中持续进步,正如论文图2所示。与之相对应,生成响应的长度也会增加——模型会生成更多思考词元来处理复杂问题。
尽管这一过程非常有效,但R1-Zero模型在推理问题上得分虽高,却面临其他问题。例如,生成内容可读性差、语言混合等问题,使其不如预期那样易用。R1的目标正是成为一个更易用、更通用的模型。因此,它并非完全依赖单一的强化学习过程,而是在两个关键节点使用强化学习:
- 创建一个中间推理模型,用于生成高质量的SFT(监督微调)数据点;
- 训练最终R1模型,以同时改进推理和非推理问题(借助其他类型的验证器)。
2.3.2 利用过渡模型生成高质量训练数据
为了使中间推理模型更具实用性,团队在数千个推理问题示例上对其进行了监督微调(SFT)训练,其中部分示例来自对R1-Zero生成结果的筛选与整理。论文将这一步骤称为“冷启动数据”:
- 使用少样本提示技术,以长链思维方式生成推理示例;
- 直接让模型生成包含自我反思和验证环节的详细答案;
- 收集并整理R1-Zero生成的、可读性较好的输出;
- 通过人工标注进一步优化输出质量。
这个初始数据集虽然仅有约5000个样本,但它为后续扩展到60万个高质量训练样本奠定了坚实基础。这种“数据放大”过程正是中间推理模型发挥的关键作用。而监督微调(SFT)过程则确保了模型能够快速准确地完成任务——每个训练样本都包含了详细的问题解决过程,帮助模型形成清晰的思维链条。
2.3.3 全方位的强化学习优化
最终的R1模型采用了更全面的强化学习策略。除了继承前面阶段的推理能力,还引入了:
- 针对非推理任务的验证机制;
- 类似Llama模型的帮助性评估指标;
- 安全性奖励模型;
- 更完善的用户体验优化。
这使得R1不仅保持了强大的推理能力,还能胜任各种日常对话和通用任务,实现了能力与可用性的双重提升。
架构设计
与GPT-2和GPT-3初期等前代模型类似,DeepSeek-R1同样基于Transformer解码器块堆叠而成。它由61个解码器块组成,其中前三个为密集块,其余为专家混合(MoE)层。这种设计既保证了模型的性能上限,又显著提高了计算效率。
在模型维度大小及其他超参数方面,具体数值如下: