业内有一个共识越来越清晰:大模型的主战场,正在从训练转向推理。越来越多的公司,开始围绕内部提效和外部商业化的方向,设计真正意义上的大模型应用,并投入生产环境。但在这个过程中,大家普遍遇到了一系列新的挑战。
这些问题,和当初大模型应用在"概念验证阶段"遇到的很不一样——它们更多地指向了规模化落地和安全性落地。也正是在这个背景下,AI 网关开始频频出现在讨论中,被不少人视为 AI 基础设施中的关键组件。
但需要指出的是,AI 网关并非独立于 API 网关的全新形态。它的本质仍然是一种 API 网关,只不过针对 AI 场景涌现出的新需求做了专门的扩展。它既是 API 网关的继承者,也是 API 网关的演进方向。所以,我们不妨从 API 的视角出发,把 AI 网关的能力重新梳理一遍。这样既能形成概念的共识,也便于后续的设计和选型。
01
API 网关的继承
围绕 API 提供的能力其实相当庞杂,涉及的角色也五花八门。为了方便理解,我们可以把这些能力按照使用方来分类:研发、供应和消费三大场景,分别对应 API 接口的研发团队、API 平台的研发运维团队,以及 API 平台的外部调用方。
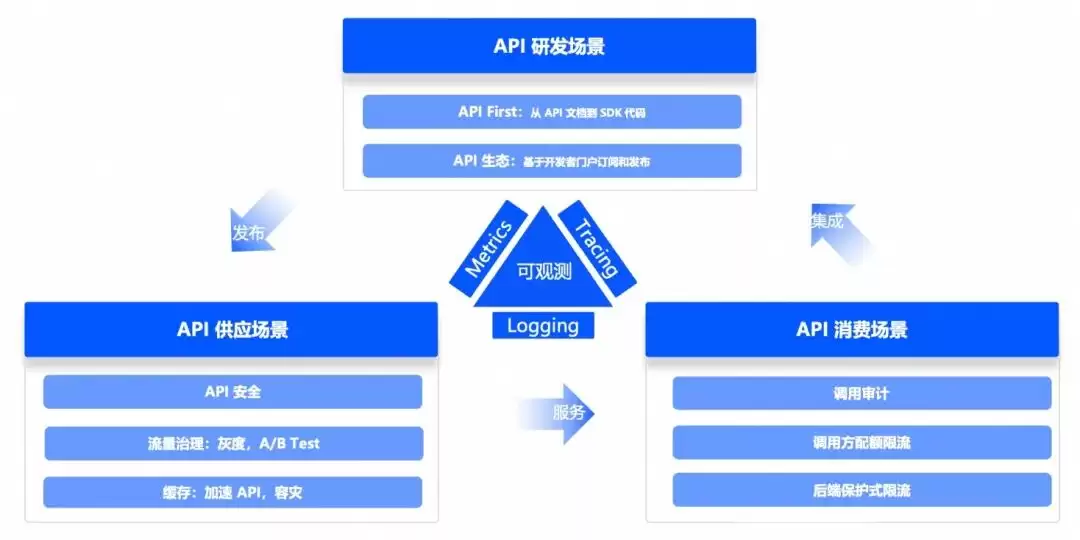
API 研发场景
API First 的理念,简单说就是"先定义规范,再写代码"。这和"撸起袖子直接写"的路径完全不同。它强调在构建应用之前,先把 API 接口当作系统的核心架构组件来设计,通过定义良好的接口规范,实现真正的模块化。好比搭乐高积木,每个模块都有标准接口,灵活组合,好扩展,也好维护。公共云的云产品、微信小程序、钉钉开放平台,背后都是这么干的。
API 供应场景
API 供应场景,指的是 API 提供方通过标准化接口把数据或功能开放出去的过程。核心就是创建、管理和维护 API,确保它们的可用性、安全性和高效性。典型能力包括:
- API 安全:身份验证、授权管理、数据加解密、防攻击——总之,确保只有合法用户或应用能访问 API,数据也不能被泄漏或篡改。
- 灰度发布:逐步引入新版本 API,先把一部分流量引到新版本,跑通了再全面推广。不影响整体稳定性,又能验证新功能。
- 缓存:把 API 的响应结果临时存起来,相同请求来了直接用,不用每次都绕到后端。响应速度能提上去,系统压力也能降下来。
API 消费场景
API 消费场景,就是调用方通过集成外部 API,快速实现自己想要的功能或获取数据。核心是利用平台提供的能力来满足业务需求。常见能力有:
- 调用审计:每一次 API 调用都记录下来——谁调了、调了什么接口、参数、结果、耗时……方便后续回溯、监控和分析。
- 调用方配额限速:按用户、应用或 IP 等维度,限制在一定时间内的调用次数或流量。防止某个调用方把资源打满,影响其他人。
- 后端保护式限流:包括负载均衡、限流、降级、熔断。目的就一个:别让流量把后端搞崩。
02
API 网关的演进
大模型场景有一个显著特点:大模型本身也在通过 API 对外提供服务。于是,无论是研发场景、供应场景还是消费场景,都出现了比以往更丰富的诉求。
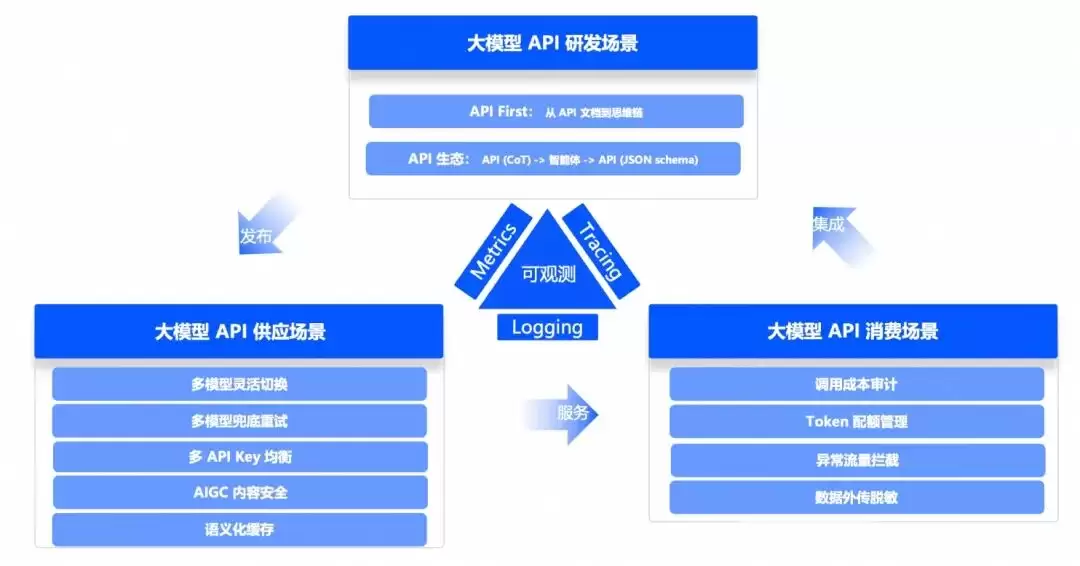
大模型 API 研发场景
API First 已经不再是一句口号,而是越来越多的实际开发规范。Agent 的开发和运行,需要调用 API;Agent 通过开放平台对外服务,也需要提供 API。API 网关可以覆盖从设计、开发、测试到发布、售卖、运维、安全管控、下线的完整生命周期。在此基础上,还可以通过插件机制提升 Agent 开发效率,比如AI 提示词模板、API AI Agent、JSON 格式化(根据用户配置的 Json Schema 对 AI 输出做结构化处理)。
大模型 API 供应场景
- 多模型灵活切换与兜底重试:后端对接多个大模型,几乎成了标配。用户能自己选模型,系统也能在某个模型出故障或容量不够时,自动切换到其他模型。
- 内容安全和合规:通过内容安全插件,过滤有害内容,检测并阻止敏感数据泄露,对 AI 生成内容进行合规性审核。
- 语义化缓存:大模型 API 的定价通常按输入 tokens 算,缓存命中的价格远低于未命中。以通义系列为例,缓存命中价格只有未命中的 40%。通过在内存数据库中缓存 LLM 响应,再以网关插件的形式,能显著降低推理延迟和成本。网关层可以自动缓存用户的历史对话,并在后续对话中自动填充上下文,帮助大模型理解上下文语义。
- 多 API Key 均衡:当你有多个 API Key 时,网关可以根据策略把请求均匀或按规则分配到这些 Key 上,避免单个 Key 被击穿。
大模型 API 消费场景
- Token 配额管理和限流:Token 是大模型应用中最常见的衡量单位。像传统网关管理服务访问量一样,AI 网关也需要对 Token 进行管理——包括观测使用量、提供限流功能、为不同租户配置精确的调用额度。
- 流量灰度:基模和大模型应用都在持续优化生成质量,变更频率相当高。这就对 A/B 测试和灰度能力提出了很高的要求。作为流量入口,AI 网关需要负责灰度打标和监控,比如入口流量延时、成功率等指标。
- 调用成本审计:大模型调用消耗的计算资源远高于普通 Web 请求,成本控制的刚需比以往更突出。这里的成本既包括直接的经济成本(比如第三方 API 费用、内部计算资源消耗),也包括间接成本(比如调用出错导致的资源浪费)。
03
为什么要在网关上,而非大模型服务层实现这些能力
这个问题很关键。它关系到整个架构的设计思路。
架构设计与解耦
- 功能分离:网关和大模型服务层,各自承担的核心职责完全不同。大模型服务层专注于执行复杂的计算任务——自然语言处理、图像识别等等;API 网关则负责 API 的访问管理,比如安全认证、流量控制、协议转换。把网关能力放在网关上,功能清晰,各司其职,维护和扩展都更容易。
- 解耦系统:如果把 API 网关的功能塞进大模型服务层,两者就紧密耦合了。每次调整 API 管理策略(比如改一下安全认证方式、调一下限流规则),都可能会影响大模型服务的稳定性和性能。放在网关上实现,两者可以独立演进,系统复杂度更低,维护成本也更可控。
性能优化
- 减少大模型负载:大模型本身已经够重了——大量计算资源和内存,处理复杂的推理任务已经够吃力。如果再往里面塞身份验证、限流、缓存这些功能,负载只会更重,响应时间也会受影响。放在网关上做,可以在请求到达大模型服务层之前就做预处理和过滤,减少不必要的请求进入,提升大模型本身的性能。
- 提高并发处理能力:网关可以通过负载均衡,把大量 API 请求均匀地分配到多个大模型服务实例上,系统整体的并发处理能力因此大幅提升。如果每个大模型服务实例都要自己处理 API 管理任务,并发能力必然受限。
安全保障
- 统一安全防护:网关作为系统的唯一入口,对所有 API 请求做统一的安全检查,形成一条完整的防线。身份验证、授权、防攻击,都可以在这里集中搞定。如果让安全能力分散在大模型服务层,势必会出现防护漏洞。
- 数据保护:网关可以对 API 请求和响应做加密、脱敏处理,确保数据在传输和存储过程中的安全。如果在大模型服务层处理这些任务,不仅增加了计算负担,还让大模型直接接触了敏感数据——这不是好事。
可扩展性与灵活性
- 方便新功能集成:业务在发展,API 管理功能也得不断更新——支持新的安全认证协议、引入新的流量控制算法等等。在网关上做这些事情,比修改大模型服务层要方便得多,响应业务变化的速度自然也更快。
- 支持多模型接入:实际应用中,经常会同时使用多个不同的大模型服务。网关作为统一的接入点,为这些模型提供一致的 API 管理服务,管理调度都变得简单。如果每个大模型服务层都要单独实现 API 网关功能,系统只会越来越复杂。
可观测性与监控
- 集中监控与分析:网关可以集中监控所有 API 请求,收集各类指标——响应时间、调用频率、错误率等等。通过这些数据,能及时发现系统的问题(性能瓶颈、安全漏洞等),并做出优化。如果监控功能分散在大模型服务层,很难对整个系统形成全面的了解。
- 故障排查与定位:API 调用出问题了,在网关上排查要比在大模型服务层容易得多。网关会记录每个请求的详细日志——来源、参数、响应结果——通过这些信息,可以快速锁定故障的原因和位置,缩短修复时间。
04
AI 网关未来的演进方向
得益于 Wasm 插件的动态扩展能力,Higress 在 AI 时代快速迭代,逐步发展出了应对大模型场景的能力。本文提到的所有大模型 API 管理底层能力,都已经在开源 Higress 和阿里云云原生 API 网关上线。
(Higress 开源控制台)
(阿里云云原生 API 网关控制台)
与此同时,在阿里云云原生 API 网关上,我们还推出了专门的AI API 管理能力,让 AI 时代的 API 管理变得更高效、更便捷。
(创建 AI API 选项)