关于人工智能的发展水平,学术界、产业界和媒体圈一直存在广泛争议。最常听到的观点是:以大数据和深度学习为核心的人工智能,代表着一种全新技术形态,它能够自主学习,从而根本性地改变未来人类社会,甚至大规模取代人类劳动力。
然而,这背后隐藏着两个流传甚广的认知误区。第一,深度学习本身并非全新发明;第二,它所谓的“学习”与人类的学习截然不同——它并不能真正“深入”理解自己所处理的信息。
深度学习并非新技术
从技术发展史来看,深度学习的前身,正是上世纪80年代就已风靡一时的“人工神经元网络”技术,也称为“连接主义”。
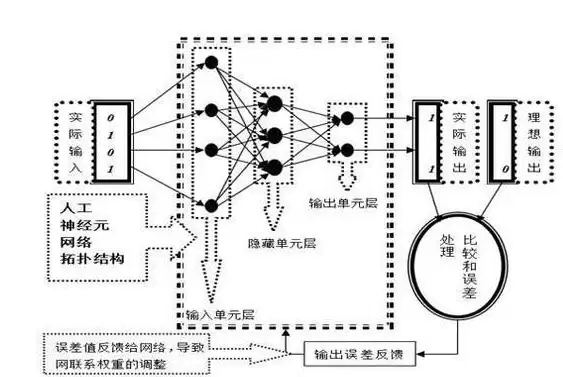
其本质是通过数学建模构建一个简化的人工神经元网络结构。该结构通常包含三个层次:输入层、中间层(隐藏层)和输出层。输入层接收外部信息后,每个单元根据内置的汇聚算法和激活函数,“决定”是否向中间层传递数据。这一过程类似于人类神经元接收电脉冲后,根据细胞核内电位变化来判断是否继续向下传递信号。
值得注意的是,无论系统执行的是图像识别还是自然语言处理,如果只观察单个计算单元的运作,根本无法看出整体任务是什么。换句话说,整个系统采用“化整为零”的方式,将宏观识别任务拆解为系统内部构件之间的微观信息传递,再通过这些微观活动呈现出的整体趋势,模拟人类心智在符号层面的信息处理过程。
工程师调整系统微观传递趋势的基本方法如下:先让系统对输入信息进行随机处理,然后将输出结果与理想结果对比。若吻合度不足,系统自动触发“反向传播算法”,调整各计算单元之间的连接权重。两个单元之间的权重越大,它们越容易产生“共激发”现象,反之亦然。系统再次比较实际输出与理想输出,若不吻合,则再次启动反向传播,直至两者一致。
经过这样训练的系统,不仅能准确归类训练样本,通常也能对与训练样本相似的输入信息做出相对准确的判断。例如,如果一个系统已学会识别既有照片库中张三的脸,那么即使是一张从未入库的新照片,系统也能迅速识别出这就是张三。
如果觉得上述技术描述有些复杂,可以用一个比喻来理解。想象一个完全不懂汉语的外国人在少林寺学武,师生之间如何教学?有两种可能。第一种,两人能用语言交流(外国人懂汉语或师傅懂外语),师傅可以直接通过“给出规则”来教。这大致类比基于规则的人工智能路线。
第二种情况,师傅与徒弟语言完全不通,那么如何学习?只能靠这种方法:徒弟先观察师傅的动作,模仿,师傅用简单的肢体语言反馈——例如,做对了就微笑,做错了就棒喝。如果师傅肯定了某个动作,徒弟就记住它,继续学习。若不对,徒弟只能猜测自己的错误,然后根据猜测尝试新动作,等待反馈,直到师傅满意为止。这种学习方式效率显然很低,因为猜测会浪费大量时间。但“猜测”二字,恰好揭示了人工神经元网络运作的实质:系统根本不知道输入信息的意义——设计者无法与系统进行符号层面的交流,就像案例中师傅无法与徒弟用语言交流一样。这种低效之所以能被接受,完全是因为计算机拥有一个巨大优势:它可以在极短时间内进行海量次数的“猜测”,并从其中选出一个相对正确的解。一旦看清这层机制,你就会发现:人工神经元网络的运作原理其实相当笨拙。
“深度学习”更应称为“深层学习”
那么,为什么“神经元网络技术”现在又有了“深度学习”这个新名称?它究竟意味着什么?
不得不承认,“深度学习”这个名称极具迷惑性——它容易让人误以为人工智能系统已经能够像人类一样“深度”理解所学内容。然而真实情况是,按人类的“理解”标准,这些系统连最肤浅的理解都无法实现。
为避免这种误解,我更倾向于将“深度学习”称为“深层学习”。因为英文原词“Deep Learning”的真正含义,就是对传统人工神经元网络进行技术升级:增加隐藏单元层的数量。这种做法的好处在于,让整个系统的信息处理机制更加精细,使更多对象特征能够在更多中间层中得到安置。
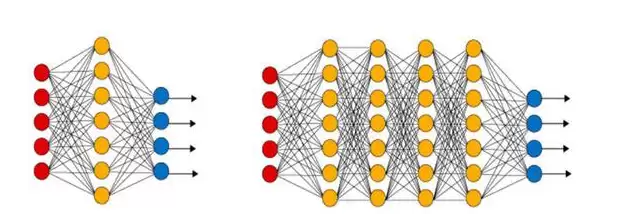
例如,在人脸识别的深度学习系统中,更多的中间层能够更精细地处理初级像素、色块边缘、线条组合、五官轮廓等不同层级的特征。这种精细化处理方式,自然能提升系统的识别能力。
然而,这种“深度”化所要求的系统数学复杂度与数据多样性,对计算机硬件和训练数据量提出了极高要求。这也是为什么深度学习技术直到21世纪后才逐渐普及——正是近十几年来计算机硬件的飞速发展,以及互联网普及带来的海量数据,为深度学习的落地提供了基础保障。
不过,有两个根本性瓶颈阻碍了神经元网络-深度学习技术的进一步“智能化”。
第一,系统一旦训练收敛,学习能力便随之停止。系统无法根据新的输入调整权重。这并非我们的理想目标。理想情况下,即使训练样本库的局限性导致网络过早收敛,面对新样本时,系统也应能自主修订原有的输入-输出映射关系,同时兼顾历史数据与新出现的数据。但现有技术根本无法做到。设计者目前只能将系统的历史知识归零,将新样本纳入样本库,然后从头开始重新训练。这里我们再次看到了令人无奈的“西西弗斯循环”。
第二,在神经元网络-深度学习的模式识别过程中,设计者的大量精力都耗费在对原始样本的特征提取上。同样的原始样本,在不同设计者手中会产生完全不同的特征提取模式,进而导致不同的建模方向。对人类程序员而言,这恰好是展现创造力的机会,但对于系统本身,这等于剥夺了它进行创造性活动的可能。试想:一个如此设计的系统,能自行观察原始样本、找到合适的特征提取模式、并设计出自己的拓扑结构吗?很难。因为这似乎要求该结构背后存在一个“元结构”,能够对自身进行反思性表征。至于这个元结构如何编程,我们目前仍一头雾水——因为实现这一元结构功能的,恰恰是我们人类自己。令人失望的是,尽管深度学习技术带有这些根本性缺陷,目前主流的人工智能界几乎已“洗脑”,认为深度学习就等于人工智能的全部。而一种基于小数据、更灵活、更通用的人工智能技术,显然还需要投入更多精力。从纯学术角度看,距离这一目标还有很长的路要走。